 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Text-to-SQL for IoT Defense: A Comprehensive Framework for Querying and Classifying IoT Threats
Jun 25, 2024Recognizing the promise of natural language interfaces to databases, prior studies have emphasized the development of text-to-SQL systems. While substantial progress has been made in this field, existing research has concentrated on generating SQL statements from text queries. The broader challenge, however, lies in inferring new information about the returned data. Our research makes two major contributions to address this gap. First, we introduce a novel Internet-of-Things (IoT) text-to-SQL dataset comprising 10,985 text-SQL pairs and 239,398 rows of network traffic activity. The dataset contains additional query types limited in prior text-to-SQL datasets, notably temporal-related queries. Our dataset is sourced from a smart building's IoT ecosystem exploring sensor read and network traffic data. Second, our dataset allows two-stage processing, where the returned data (network traffic) from a generated SQL can be categorized as malicious or not. Our results show that joint training to query and infer information about the data can improve overall text-to-SQL performance, nearly matching substantially larger models. We also show that current large language models (e.g., GPT3.5) struggle to infer new information about returned data, thus our dataset provides a novel test bed for integrating complex domain-specific reasoning into LLMs.
Extracting Biomedical Entities from Noisy Audio Transcripts
Mar 26, 2024



Automatic Speech Recognition (ASR) technology is fundamental in transcribing spoken language into text, with considerable applications in the clinical realm, including streamlining medical transcription and integrating with Electronic Health Record (EHR) systems. Nevertheless, challenges persist, especially when transcriptions contain noise, leading to significant drops in performance when Natural Language Processing (NLP) models are applied. Named Entity Recognition (NER), an essential clinical task, is particularly affected by such noise, often termed the ASR-NLP gap. Prior works have primarily studied ASR's efficiency in clean recordings, leaving a research gap concerning the performance in noisy environments. This paper introduces a novel dataset, BioASR-NER, designed to bridge the ASR-NLP gap in the biomedical domain, focusing on extracting adverse drug reactions and mentions of entities from the Brief Test of Adult Cognition by Telephone (BTACT) exam. Our dataset offers a comprehensive collection of almost 2,000 clean and noisy recordings. In addressing the noise challenge, we present an innovative transcript-cleaning method using GPT4, investigating both zero-shot and few-shot methodologies. Our study further delves into an error analysis, shedding light on the types of errors in transcription software, corrections by GPT4, and the challenges GPT4 faces. This paper aims to foster improved understanding and potential solutions for the ASR-NLP gap, ultimately supporting enhanced healthcare documentation practices.
Interpretable Self-supervised Multi-task Learning for COVID-19 Information Retrieval and Extraction
Jun 15, 2021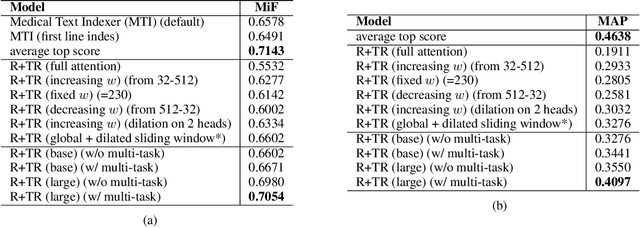


The rapidly evolving literature of COVID-19 related articles makes it challenging for NLP models to be effectively trained for information retrieval and extraction with the corresponding labeled data that follows the current distribution of the pandemic. On the other hand, due to the uncertainty of the situation, human experts' supervision would always be required to double check the decision making of these models highlighting the importance of interpretability. In the light of these challenges, this study proposes an interpretable self-supervised multi-task learning model to jointly and effectively tackle the tasks of information retrieval (IR) and extraction (IE) during the current emergency health crisis situation. Our results show that our model effectively leverage the multi-task and self-supervised learning to improve generalization, data efficiency and robustness to the ongoing dataset shift problem. Our model outperforms baselines in IE and IR tasks, respectively by micro-f score of 0.08 (LCA-F score of 0.05), and MAP of 0.05 on average. In IE the zero- and few-shot learning performances are on average 0.32 and 0.19 micro-f score higher than those of the baselines.
A Self-supervised Approach for Semantic Indexing in the Context of COVID-19 Pandemic
Oct 07, 2020

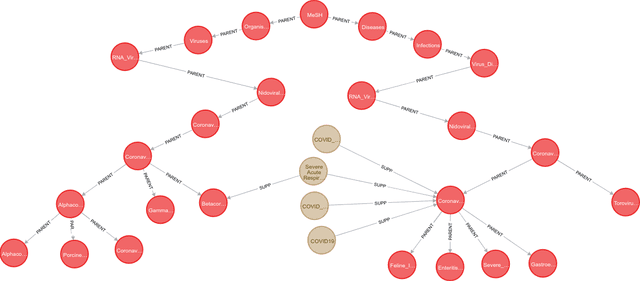
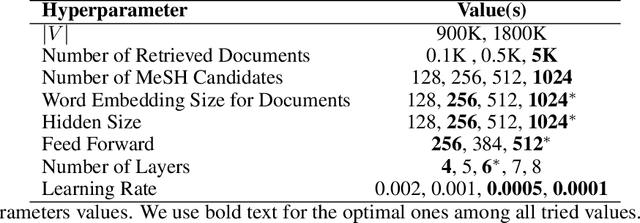
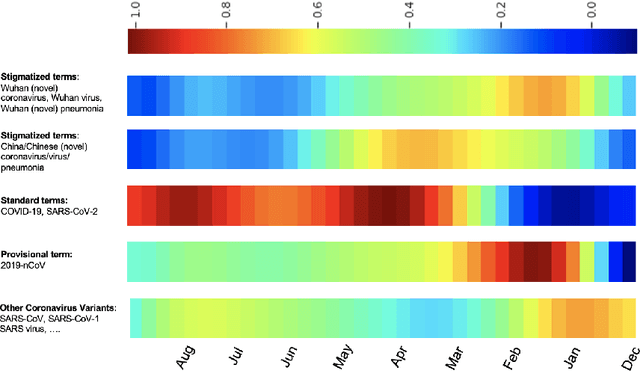
The pandemic has accelerated the pace at which COVID-19 scientific papers are published. In addition, the process of manually assigning semantic indexes to these papers by experts is even more time-consuming and overwhelming in the current health crisis. Therefore, there is an urgent need for automatic semantic indexing models which can effectively scale-up to newly introduced concepts and rapidly evolving distributions of the hyperfocused related literature. In this research, we present a novel semantic indexing approach based on the state-of-the-art self-supervised representation learning and transformer encoding exclusively suitable for pandemic crises. We present a case study on a novel dataset that is based on COVID-19 papers published and manually indexed in PubMed. Our study shows that our self-supervised model outperforms the best performing models of BioASQ Task 8a by micro-F1 score of 0.1 and LCA-F score of 0.08 on average. Our model also shows superior performance on detecting the supplementary concepts which is quite important when the focus of the literature has drastically shifted towards specific concepts related to the pandemic. Our study sheds light on the main challenges confronting semantic indexing models during a pandemic, namely new domains and drastic changes of their distributions, and as a superior alternative for such situations, propose a model founded on approaches which have shown auspicious performance in improving generalization and data efficiency in various NLP tasks. We also show the joint indexing of major Medical Subject Headings (MeSH) and supplementary concepts improves the overall performance.
Human Action Performance using Deep Neuro-Fuzzy Recurrent Attention Model
Feb 19, 2020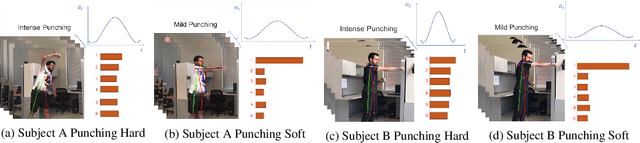

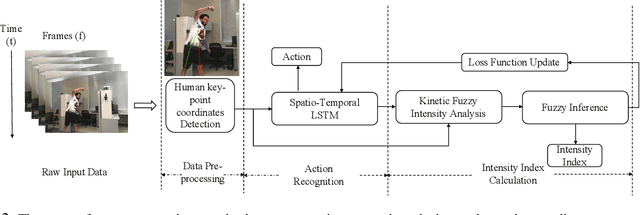
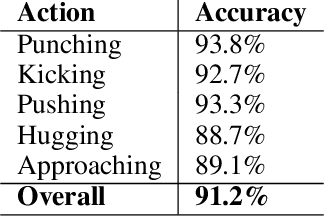
A great number of computer vision publications have focused on distinguishing between human action recognition and classification rather than the intensity of actions performed. Indexing the intensity which determines the performance of human actions is a challenging task due to the uncertainty and information deficiency that exists in the video inputs. To remedy this uncertainty, in this paper, we coupled fuzzy logic rules with the neural-based action recognition model to index the intensity of the action as intense or mild. In our approach, we define fuzzy logic rules to detect the intensity index of the performed action using the weights generated by the Spatio-Temporal LSTM and demonstrate through experiments that indexing of the action intensity is possible. We analyzed the integrated model by applying it to videos of human actions with different action intensities and were able to achieve an accuracy of 89.16% on our generated dataset for intensity indexing. The integrated model demonstrates the ability of the fuzzy inference module to effectively estimate the intensity index of the human action.