 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Text-to-SQL for IoT Defense: A Comprehensive Framework for Querying and Classifying IoT Threats
Jun 25, 2024Recognizing the promise of natural language interfaces to databases, prior studies have emphasized the development of text-to-SQL systems. While substantial progress has been made in this field, existing research has concentrated on generating SQL statements from text queries. The broader challenge, however, lies in inferring new information about the returned data. Our research makes two major contributions to address this gap. First, we introduce a novel Internet-of-Things (IoT) text-to-SQL dataset comprising 10,985 text-SQL pairs and 239,398 rows of network traffic activity. The dataset contains additional query types limited in prior text-to-SQL datasets, notably temporal-related queries. Our dataset is sourced from a smart building's IoT ecosystem exploring sensor read and network traffic data. Second, our dataset allows two-stage processing, where the returned data (network traffic) from a generated SQL can be categorized as malicious or not. Our results show that joint training to query and infer information about the data can improve overall text-to-SQL performance, nearly matching substantially larger models. We also show that current large language models (e.g., GPT3.5) struggle to infer new information about returned data, thus our dataset provides a novel test bed for integrating complex domain-specific reasoning into LLMs.
Towards Understanding the Generalization of Medical Text-to-SQL Models and Datasets
Mar 22, 2023
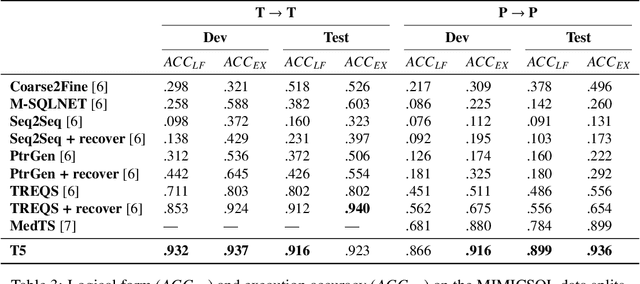
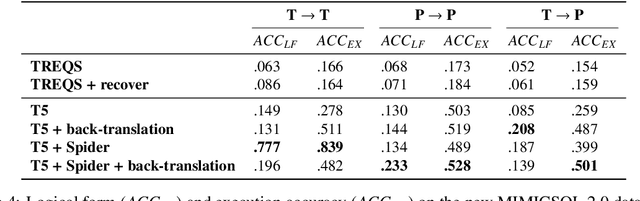
Electronic medical records (EMRs) are stored in relational databases. It can be challenging to access the required information if the user is unfamiliar with the database schema or general database fundamentals. Hence, researchers have explored text-to-SQL generation methods that provide healthcare professionals direct access to EMR data without needing a database expert. However, currently available datasets have been essentially "solved" with state-of-the-art models achieving accuracy greater than or near 90%. In this paper, we show that there is still a long way to go before solving text-to-SQL generation in the medical domain. To show this, we create new splits of the existing medical text-to-SQL dataset MIMICSQL that better measure the generalizability of the resulting models. We evaluate state-of-the-art language models on our new split showing substantial drops in performance with accuracy dropping from up to 92% to 28%, thus showing substantial room for improvement. Moreover, we introduce a novel data augmentation approach to improve the generalizability of the language models. Overall, this paper is the first step towards developing more robust text-to-SQL models in the medical domain.\footnote{The dataset and code will be released upon acceptance.