 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Zero-Shot Learning using Multimodal Variational Auto-Encoder with Semantic Concepts
Jun 26, 2021
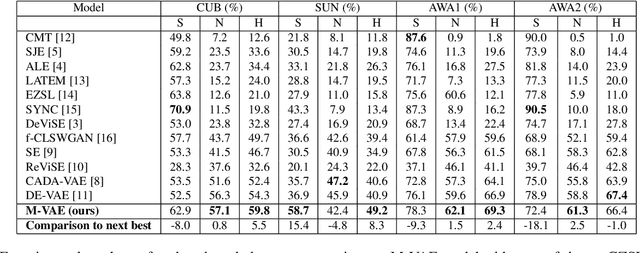


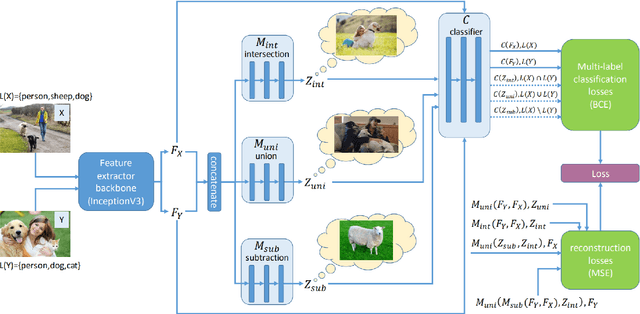
With the ever-increasing amount of data, the central challenge in multimodal learning involves limitations of labelled samples. For the task of classification, techniques such as meta-learning, zero-shot learning, and few-shot learning showcase the ability to learn information about novel classes based on prior knowledge. Recent techniques try to learn a cross-modal mapping between the semantic space and the image space. However, they tend to ignore the local and global semantic knowledge. To overcome this problem, we propose a Multimodal Variational Auto-Encoder (M-VAE) which can learn the shared latent space of image features and the semantic space. In our approach we concatenate multimodal data to a single embedding before passing it to the VAE for learning the latent space. We propose the use of a multi-modal loss during the reconstruction of the feature embedding through the decoder. Our approach is capable to correlating modalities and exploit the local and global semantic knowledge for novel sample predictions. Our experimental results using a MLP classifier on four benchmark datasets show that our proposed model outperforms the current state-of-the-art approaches for generalized zero-shot learning.
Show Why the Answer is Correct! Towards Explainable AI using Compositional Temporal Attention
May 15, 2021
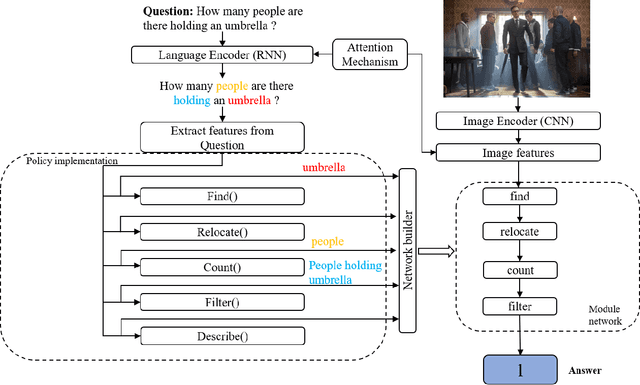


Visual Question Answering (VQA) models have achieved significant success in recent times. Despite the success of VQA models, they are mostly black-box models providing no reasoning about the predicted answer, thus raising questions for their applicability in safety-critical such as autonomous systems and cyber-security. Current state of the art fail to better complex questions and thus are unable to exploit compositionality. To minimize the black-box effect of these models and also to make them better exploit compositionality, we propose a Dynamic Neural Network (DMN), which can understand a particular question and then dynamically assemble various relatively shallow deep learning modules from a pool of modules to form a network. We incorporate compositional temporal attention to these deep learning based modules to increase compositionality exploitation. This results in achieving better understanding of complex questions and also provides reasoning as to why the module predicts a particular answer. Experimental analysis on the two benchmark datasets, VQA2.0 and CLEVR, depicts that our model outperforms the previous approaches for Visual Question Answering task as well as provides better reasoning, thus making it reliable for mission critical applications like safety and security.
Learning from Few Samples: A Survey
Jul 30, 2020
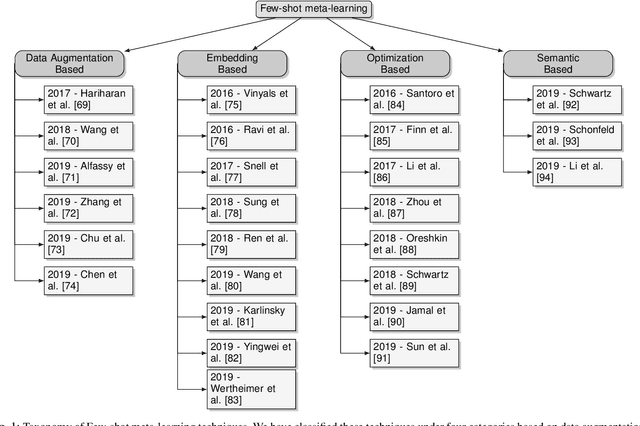
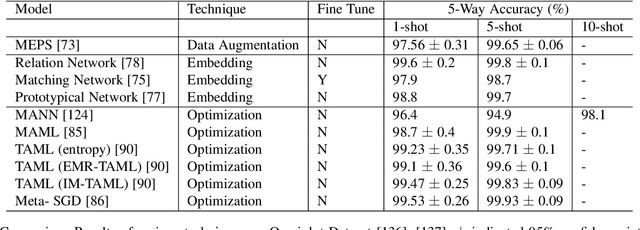
Deep neural networks have been able to outperform humans in some cases like image recognition and image classification. However, with the emergence of various novel categories, the ability to continuously widen the learning capability of such networks from limited samples, still remains a challenge. Techniques like Meta-Learning and/or few-shot learning showed promising results, where they can learn or generalize to a novel category/task based on prior knowledge. In this paper, we perform a study of the existing few-shot meta-learning techniques in the computer vision domain based on their method and evaluation metrics. We provide a taxonomy for the techniques and categorize them as data-augmentation, embedding, optimization and semantics based learning for few-shot, one-shot and zero-shot settings. We then describe the seminal work done in each category and discuss their approach towards solving the predicament of learning from few samples. Lastly we provide a comparison of these techniques on the commonly used benchmark datasets: Omniglot, and MiniImagenet, along with a discussion towards the future direction of improving the performance of these techniques towards the final goal of outperforming humans.
Human Action Performance using Deep Neuro-Fuzzy Recurrent Attention Model
Feb 19, 2020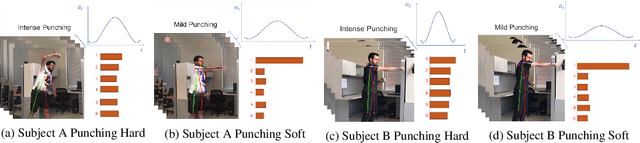

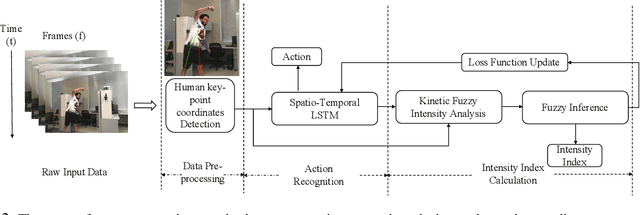
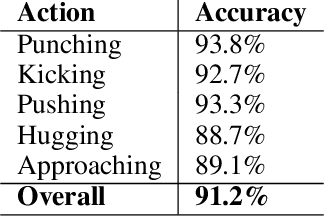
A great number of computer vision publications have focused on distinguishing between human action recognition and classification rather than the intensity of actions performed. Indexing the intensity which determines the performance of human actions is a challenging task due to the uncertainty and information deficiency that exists in the video inputs. To remedy this uncertainty, in this paper, we coupled fuzzy logic rules with the neural-based action recognition model to index the intensity of the action as intense or mild. In our approach, we define fuzzy logic rules to detect the intensity index of the performed action using the weights generated by the Spatio-Temporal LSTM and demonstrate through experiments that indexing of the action intensity is possible. We analyzed the integrated model by applying it to videos of human actions with different action intensities and were able to achieve an accuracy of 89.16% on our generated dataset for intensity indexing. The integrated model demonstrates the ability of the fuzzy inference module to effectively estimate the intensity index of the human action.