 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Temporal Radiology with Anatomical Change Explanation for Grounded X-ray Report Generation
Feb 03, 2026Temporal comparison of chest X-rays is fundamental to clinical radiology, enabling detection of disease progression, treatment response, and new findings. While vision-language models have advanced single-image report generation and visual grounding, no existing method combines these capabilities for temporal change detection. We introduce Temporal Radiology with Anatomical Change Explanation (TRACE), the first model that jointly performs temporal comparison, change classification, and spatial localization. Given a prior and current chest X-ray, TRACE generates natural language descriptions of interval changes (worsened, improved, stable) while grounding each finding with bounding box coordinates. TRACE demonstrates effective spatial localization with over 90% grounding accuracy, establishing a foundation for this challenging new task. Our ablation study uncovers an emergent capability: change detection arises only when temporal comparison and spatial grounding are jointly learned, as neither alone enables meaningful change detection. This finding suggests that grounding provides a spatial attention mechanism essential for temporal reasoning.
SRA-Seg: Synthetic to Real Alignment for Semi-Supervised Medical Image Segmentation
Feb 03, 2026Synthetic data, an appealing alternative to extensive expert-annotated data for medical image segmentation, consistently fails to improve segmentation performance despite its visual realism. The reason being that synthetic and real medical images exist in different semantic feature spaces, creating a domain gap that current semi-supervised learning methods cannot bridge. We propose SRA-Seg, a framework explicitly designed to align synthetic and real feature distributions for medical image segmentation. SRA-Seg introduces a similarity-alignment (SA) loss using frozen DINOv2 embeddings to pull synthetic representations toward their nearest real counterparts in semantic space. We employ soft edge blending to create smooth anatomical transitions and continuous labels, eliminating the hard boundaries from traditional copy-paste augmentation. The framework generates pseudo-labels for synthetic images via an EMA teacher model and applies soft-segmentation losses that respect uncertainty in mixed regions. Our experiments demonstrate strong results: using only 10% labeled real data and 90% synthetic unlabeled data, SRA-Seg achieves 89.34% Dice on ACDC and 84.42% on FIVES, significantly outperforming existing semi-supervised methods and matching the performance of methods using real unlabeled data.
PMPNet: Pixel Movement Prediction Network for Monocular Depth Estimation in Dynamic Scenes
Nov 04, 2024In this paper, we propose a novel method for monocular depth estimation in dynamic scenes. We first explore the arbitrariness of object's movement trajectory in dynamic scenes theoretically. To overcome the arbitrariness, we use assume that points move along a straight line over short distances and then summarize it as a triangular constraint loss in two dimensional Euclidean space. To overcome the depth inconsistency problem around the edges, we propose a deformable support window module that learns features from different shapes of objects, making depth value more accurate around edge area. The proposed model is trained and tested on two outdoor datasets - KITTI and Make3D, as well as an indoor dataset - NYU Depth V2. The quantitative and qualitative results reported on these datasets demonstrate the success of our proposed model when compared against other approaches. Ablation study results on the KITTI dataset also validate the effectiveness of the proposed pixel movement prediction module as well as the deformable support window module.
Mazed and Confused: A Dataset of Cybersickness, Working Memory, Mental Load, Physical Load, and Attention During a Real Walking Task in VR
Sep 10, 2024Virtual Reality (VR) is quickly establishing itself in various industries, including training, education, medicine, and entertainment, in which users are frequently required to carry out multiple complex cognitive and physical activities. However, the relationship between cognitive activities, physical activities, and familiar feelings of cybersickness is not well understood and thus can be unpredictable for developers. Researchers have previously provided labeled datasets for predicting cybersickness while users are stationary, but there have been few labeled datasets on cybersickness while users are physically walking. Thus, from 39 participants, we collected head orientation, head position, eye tracking, images, physiological readings from external sensors, and the self-reported cybersickness severity, physical load, and mental load in VR. Throughout the data collection, participants navigated mazes via real walking and performed tasks challenging their attention and working memory. To demonstrate the dataset's utility, we conducted a case study of training classifiers in which we achieved 95% accuracy for cybersickness severity classification. The noteworthy performance of the straightforward classifiers makes this dataset ideal for future researchers to develop cybersickness detection and reduction models. To better understand the features that helped with classification, we performed SHAP(SHapley Additive exPlanations) analysis, highlighting the importance of eye tracking and physiological measures for cybersickness prediction while walking. This open dataset can allow future researchers to study the connection between cybersickness and cognitive loads and develop prediction models. This dataset will empower future VR developers to design efficient and effective Virtual Environments by improving cognitive load management and minimizing cybersickness.
EncodeNet: A Framework for Boosting DNN Accuracy with Entropy-driven Generalized Converting Autoencoder
Apr 21, 2024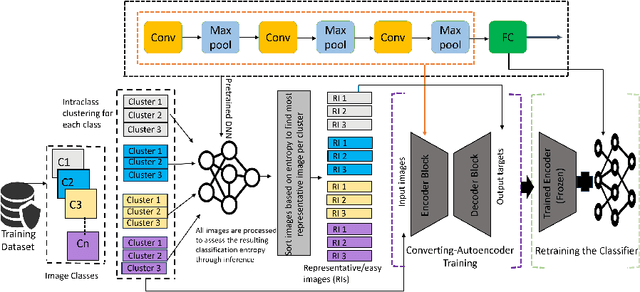
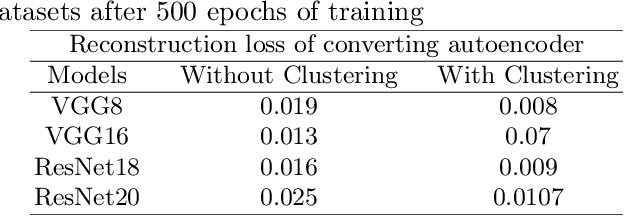
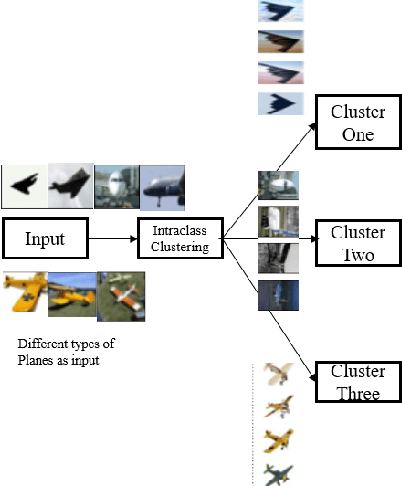
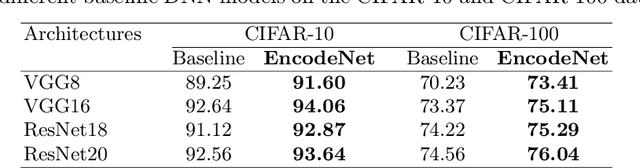
Image classification is a fundamental task in computer vision, and the quest to enhance DNN accuracy without inflating model size or latency remains a pressing concern. We make a couple of advances in this regard, leading to a novel EncodeNet design and training framework. The first advancement involves Converting Autoencoders, a novel approach that transforms images into an easy-to-classify image of its class. Our prior work that applied the Converting Autoencoder and a simple classifier in tandem achieved moderate accuracy over simple datasets, such as MNIST and FMNIST. However, on more complex datasets like CIFAR-10, the Converting Autoencoder has a large reconstruction loss, making it unsuitable for enhancing DNN accuracy. To address these limitations, we generalize the design of Converting Autoencoders by leveraging a larger class of DNNs, those with architectures comprising feature extraction layers followed by classification layers. We incorporate a generalized algorithmic design of the Converting Autoencoder and intraclass clustering to identify representative images, leading to optimized image feature learning. Next, we demonstrate the effectiveness of our EncodeNet design and training framework, improving the accuracy of well-trained baseline DNNs while maintaining the overall model size. EncodeNet's building blocks comprise the trained encoder from our generalized Converting Autoencoders transferring knowledge to a lightweight classifier network - also extracted from the baseline DNN. Our experimental results demonstrate that EncodeNet improves the accuracy of VGG16 from 92.64% to 94.05% on CIFAR-10 and RestNet20 from 74.56% to 76.04% on CIFAR-100. It outperforms state-of-the-art techniques that rely on knowledge distillation and attention mechanisms, delivering higher accuracy for models of comparable size.
A Survey on 3D Egocentric Human Pose Estimation
Mar 26, 2024Egocentric human pose estimation aims to estimate human body poses and develop body representations from a first-person camera perspective. It has gained vast popularity in recent years because of its wide range of applications in sectors like XR-technologies, human-computer interaction, and fitness tracking. However, to the best of our knowledge, there is no systematic literature review based on the proposed solutions regarding egocentric 3D human pose estimation. To that end, the aim of this survey paper is to provide an extensive overview of the current state of egocentric pose estimation research. In this paper, we categorize and discuss the popular datasets and the different pose estimation models, highlighting the strengths and weaknesses of different methods by comparative analysis. This survey can be a valuable resource for both researchers and practitioners in the field, offering insights into key concepts and cutting-edge solutions in egocentric pose estimation, its wide-ranging applications, as well as the open problems with future scope.
A Converting Autoencoder Toward Low-latency and Energy-efficient DNN Inference at the Edge
Mar 11, 2024Reducing inference time and energy usage while maintaining prediction accuracy has become a significant concern for deep neural networks (DNN) inference on resource-constrained edge devices. To address this problem, we propose a novel approach based on "converting" autoencoder and lightweight DNNs. This improves upon recent work such as early-exiting framework and DNN partitioning. Early-exiting frameworks spend different amounts of computation power for different input data depending upon their complexity. However, they can be inefficient in real-world scenarios that deal with many hard image samples. On the other hand, DNN partitioning algorithms that utilize the computation power of both the cloud and edge devices can be affected by network delays and intermittent connections between the cloud and the edge. We present CBNet, a low-latency and energy-efficient DNN inference framework tailored for edge devices. It utilizes a "converting" autoencoder to efficiently transform hard images into easy ones, which are subsequently processed by a lightweight DNN for inference. To the best of our knowledge, such autoencoder has not been proposed earlier. Our experimental results using three popular image-classification datasets on a Raspberry Pi 4, a Google Cloud instance, and an instance with Nvidia Tesla K80 GPU show that CBNet achieves up to 4.8x speedup in inference latency and 79% reduction in energy usage compared to competing techniques while maintaining similar or higher accuracy.
Generalized Zero-Shot Learning using Multimodal Variational Auto-Encoder with Semantic Concepts
Jun 26, 2021
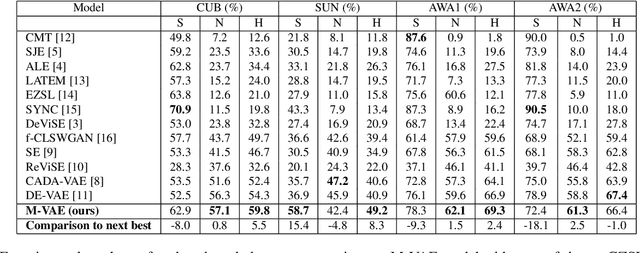


With the ever-increasing amount of data, the central challenge in multimodal learning involves limitations of labelled samples. For the task of classification, techniques such as meta-learning, zero-shot learning, and few-shot learning showcase the ability to learn information about novel classes based on prior knowledge. Recent techniques try to learn a cross-modal mapping between the semantic space and the image space. However, they tend to ignore the local and global semantic knowledge. To overcome this problem, we propose a Multimodal Variational Auto-Encoder (M-VAE) which can learn the shared latent space of image features and the semantic space. In our approach we concatenate multimodal data to a single embedding before passing it to the VAE for learning the latent space. We propose the use of a multi-modal loss during the reconstruction of the feature embedding through the decoder. Our approach is capable to correlating modalities and exploit the local and global semantic knowledge for novel sample predictions. Our experimental results using a MLP classifier on four benchmark datasets show that our proposed model outperforms the current state-of-the-art approaches for generalized zero-shot learning.
Show Why the Answer is Correct! Towards Explainable AI using Compositional Temporal Attention
May 15, 2021
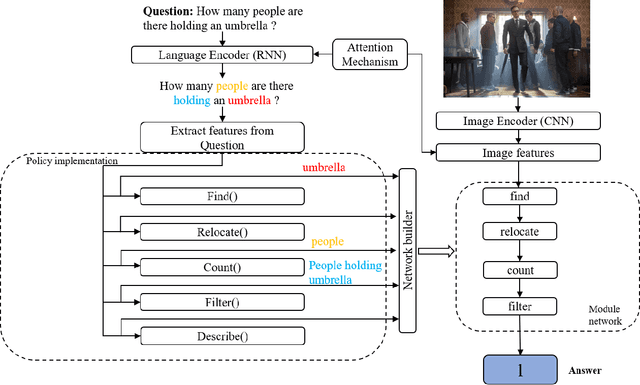


Visual Question Answering (VQA) models have achieved significant success in recent times. Despite the success of VQA models, they are mostly black-box models providing no reasoning about the predicted answer, thus raising questions for their applicability in safety-critical such as autonomous systems and cyber-security. Current state of the art fail to better complex questions and thus are unable to exploit compositionality. To minimize the black-box effect of these models and also to make them better exploit compositionality, we propose a Dynamic Neural Network (DMN), which can understand a particular question and then dynamically assemble various relatively shallow deep learning modules from a pool of modules to form a network. We incorporate compositional temporal attention to these deep learning based modules to increase compositionality exploitation. This results in achieving better understanding of complex questions and also provides reasoning as to why the module predicts a particular answer. Experimental analysis on the two benchmark datasets, VQA2.0 and CLEVR, depicts that our model outperforms the previous approaches for Visual Question Answering task as well as provides better reasoning, thus making it reliable for mission critical applications like safety and security.