 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Breast Ultrasound Image Augmentation Method Using Advanced Neural Style Transfer: An Efficient and Explainable Approach
Oct 31, 2024



Clinical diagnosis of breast malignancy (BM) is a challenging problem in the recent era. In particular, Deep learning (DL) models have continued to offer important solutions for early BM diagnosis but their performance experiences overfitting due to the limited volume of breast ultrasound (BUS) image data. Further, large BUS datasets are difficult to manage due to privacy and legal concerns. Hence, image augmentation is a necessary and challenging step to improve the performance of the DL models. However, the current DL-based augmentation models are inadequate and operate as a black box resulting lack of information and justifications about their suitability and efficacy. Additionally, pre and post-augmentation need high-performance computational resources and time to produce the augmented image and evaluate the model performance. Thus, this study aims to develop a novel efficient augmentation approach for BUS images with advanced neural style transfer (NST) and Explainable AI (XAI) harnessing GPU-based parallel infrastructure. We scale and distribute the training of the augmentation model across 8 GPUs using the Horovod framework on a DGX cluster, achieving a 5.09 speedup while maintaining the model's accuracy. The proposed model is evaluated on 800 (348 benign and 452 malignant) BUS images and its performance is analyzed with other progressive techniques, using different quantitative analyses. The result indicates that the proposed approach can successfully augment the BUS images with 92.47% accuracy.
A Parallel Workflow for Polar Sea-Ice Classification using Auto-labeling of Sentinel-2 Imagery
Mar 19, 2024The observation of the advancing and retreating pattern of polar sea ice cover stands as a vital indicator of global warming. This research aims to develop a robust, effective, and scalable system for classifying polar sea ice as thick/snow-covered, young/thin, or open water using Sentinel-2 (S2) images. Since the S2 satellite is actively capturing high-resolution imagery over the earth's surface, there are lots of images that need to be classified. One major obstacle is the absence of labeled S2 training data (images) to act as the ground truth. We demonstrate a scalable and accurate method for segmenting and automatically labeling S2 images using carefully determined color thresholds. We employ a parallel workflow using PySpark to scale and achieve 9-fold data loading and 16-fold map-reduce speedup on auto-labeling S2 images based on thin cloud and shadow-filtered color-based segmentation to generate label data. The auto-labeled data generated from this process are then employed to train a U-Net machine learning model, resulting in good classification accuracy. As training the U-Net classification model is computationally heavy and time-consuming, we distribute the U-Net model training to scale it over 8 GPUs using the Horovod framework over a DGX cluster with a 7.21x speedup without affecting the accuracy of the model. Using the Antarctic's Ross Sea region as an example, the U-Net model trained on auto-labeled data achieves a classification accuracy of 98.97% for auto-labeled training datasets when the thin clouds and shadows from the S2 images are filtered out.
A Converting Autoencoder Toward Low-latency and Energy-efficient DNN Inference at the Edge
Mar 11, 2024
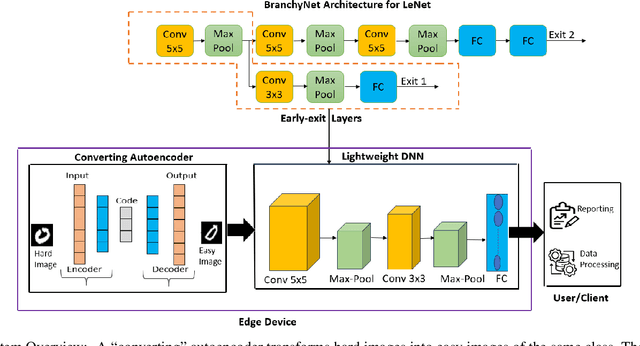


Reducing inference time and energy usage while maintaining prediction accuracy has become a significant concern for deep neural networks (DNN) inference on resource-constrained edge devices. To address this problem, we propose a novel approach based on "converting" autoencoder and lightweight DNNs. This improves upon recent work such as early-exiting framework and DNN partitioning. Early-exiting frameworks spend different amounts of computation power for different input data depending upon their complexity. However, they can be inefficient in real-world scenarios that deal with many hard image samples. On the other hand, DNN partitioning algorithms that utilize the computation power of both the cloud and edge devices can be affected by network delays and intermittent connections between the cloud and the edge. We present CBNet, a low-latency and energy-efficient DNN inference framework tailored for edge devices. It utilizes a "converting" autoencoder to efficiently transform hard images into easy ones, which are subsequently processed by a lightweight DNN for inference. To the best of our knowledge, such autoencoder has not been proposed earlier. Our experimental results using three popular image-classification datasets on a Raspberry Pi 4, a Google Cloud instance, and an instance with Nvidia Tesla K80 GPU show that CBNet achieves up to 4.8x speedup in inference latency and 79% reduction in energy usage compared to competing techniques while maintaining similar or higher accuracy.