 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Higher Resolution Polar Sea Ice Classification and Freeboard Calculation from ICESat-2 ATL03 Data
Feb 04, 2025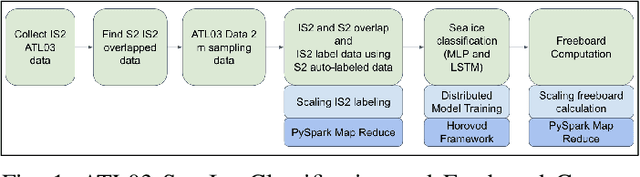
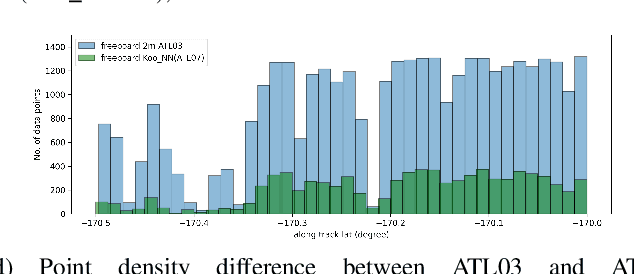
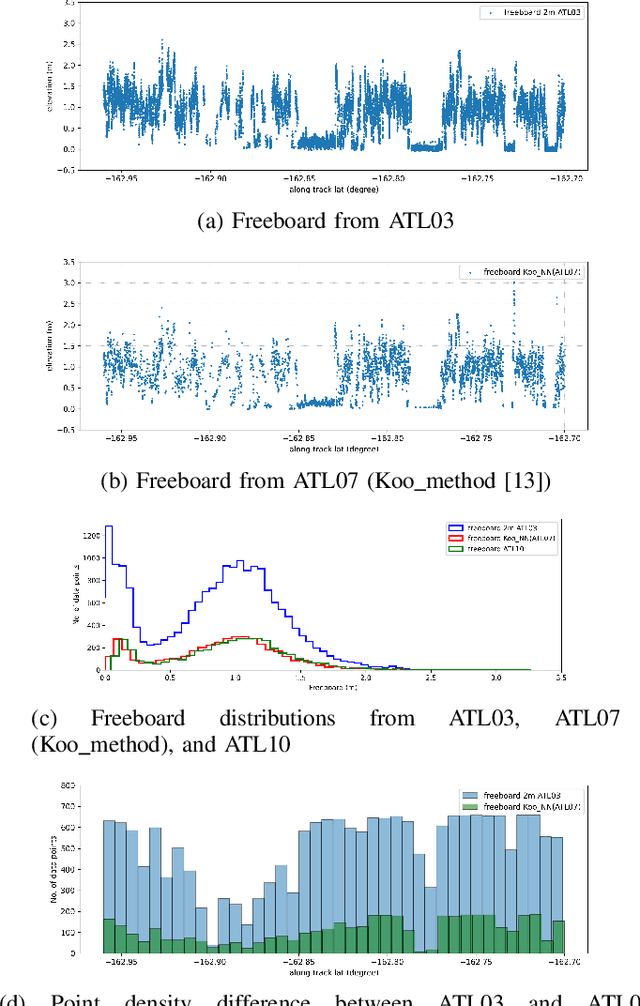
ICESat-2 (IS2) by NASA is an Earth-observing satellite that measures high-resolution surface elevation. The IS2's ATL07 and ATL10 sea ice elevation and freeboard products of 10m-200m segments which aggregated 150 signal photons from the raw ATL03 (geolocated photon) data. These aggregated products can potentially overestimate local sea surface height, thus underestimating the calculations of freeboard (sea ice height above sea surface). To achieve a higher resolution of sea surface height and freeboard information, in this work we utilize a 2m window to resample the ATL03 data. Then, we classify these 2m segments into thick sea ice, thin ice, and open water using deep learning methods (Long short-term memory and Multi-layer perceptron models). To obtain labeled training data for our deep learning models, we use segmented Sentinel-2 (S2) multi-spectral imagery overlapping with IS2 tracks in space and time to auto-label IS2 data, followed by some manual corrections in the regions of transition between different ice/water types or cloudy regions. We employ a parallel workflow for this auto-labeling using PySpark to scale, and we achieve 9-fold data loading and 16.25-fold map-reduce speedup. To train our models, we employ a Horovod-based distributed deep-learning workflow on a DGX A100 8 GPU cluster, achieving a 7.25-fold speedup. Next, we calculate the local sea surface heights based on the open water segments. Finally, we scale the freeboard calculation using the derived local sea level and achieve 8.54-fold data loading and 15.7-fold map-reduce speedup. Compared with the ATL07 (local sea level) and ATL10 (freeboard) data products, our results show higher resolutions and accuracy (96.56%).
A Parallel Workflow for Polar Sea-Ice Classification using Auto-labeling of Sentinel-2 Imagery
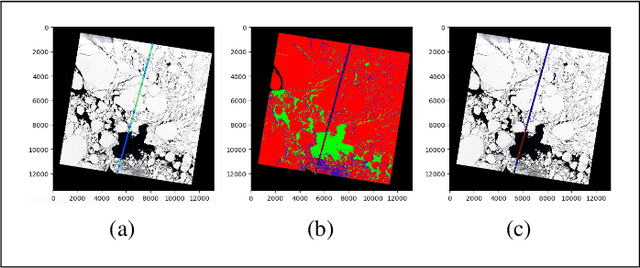
Mar 19, 2024The observation of the advancing and retreating pattern of polar sea ice cover stands as a vital indicator of global warming. This research aims to develop a robust, effective, and scalable system for classifying polar sea ice as thick/snow-covered, young/thin, or open water using Sentinel-2 (S2) images. Since the S2 satellite is actively capturing high-resolution imagery over the earth's surface, there are lots of images that need to be classified. One major obstacle is the absence of labeled S2 training data (images) to act as the ground truth. We demonstrate a scalable and accurate method for segmenting and automatically labeling S2 images using carefully determined color thresholds. We employ a parallel workflow using PySpark to scale and achieve 9-fold data loading and 16-fold map-reduce speedup on auto-labeling S2 images based on thin cloud and shadow-filtered color-based segmentation to generate label data. The auto-labeled data generated from this process are then employed to train a U-Net machine learning model, resulting in good classification accuracy. As training the U-Net classification model is computationally heavy and time-consuming, we distribute the U-Net model training to scale it over 8 GPUs using the Horovod framework over a DGX cluster with a 7.21x speedup without affecting the accuracy of the model. Using the Antarctic's Ross Sea region as an example, the U-Net model trained on auto-labeled data achieves a classification accuracy of 98.97% for auto-labeled training datasets when the thin clouds and shadows from the S2 images are filtered out.