 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Higher Resolution Polar Sea Ice Classification and Freeboard Calculation from ICESat-2 ATL03 Data
Feb 04, 2025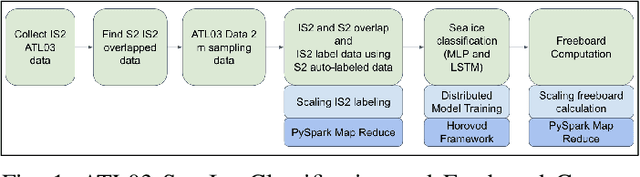
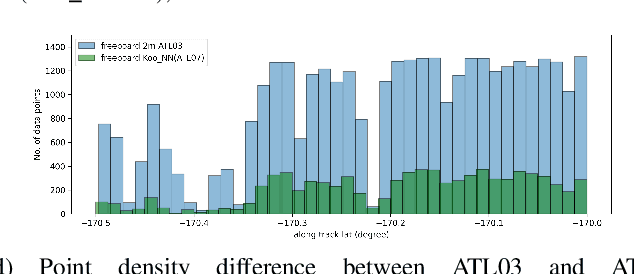
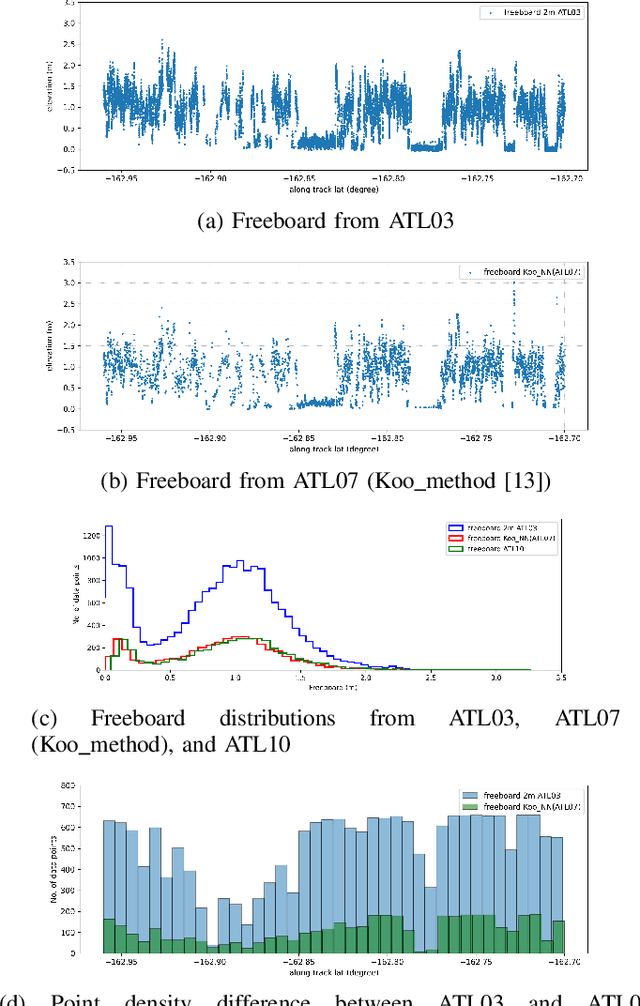
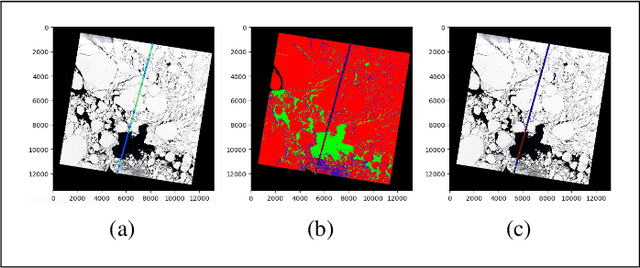
ICESat-2 (IS2) by NASA is an Earth-observing satellite that measures high-resolution surface elevation. The IS2's ATL07 and ATL10 sea ice elevation and freeboard products of 10m-200m segments which aggregated 150 signal photons from the raw ATL03 (geolocated photon) data. These aggregated products can potentially overestimate local sea surface height, thus underestimating the calculations of freeboard (sea ice height above sea surface). To achieve a higher resolution of sea surface height and freeboard information, in this work we utilize a 2m window to resample the ATL03 data. Then, we classify these 2m segments into thick sea ice, thin ice, and open water using deep learning methods (Long short-term memory and Multi-layer perceptron models). To obtain labeled training data for our deep learning models, we use segmented Sentinel-2 (S2) multi-spectral imagery overlapping with IS2 tracks in space and time to auto-label IS2 data, followed by some manual corrections in the regions of transition between different ice/water types or cloudy regions. We employ a parallel workflow for this auto-labeling using PySpark to scale, and we achieve 9-fold data loading and 16.25-fold map-reduce speedup. To train our models, we employ a Horovod-based distributed deep-learning workflow on a DGX A100 8 GPU cluster, achieving a 7.25-fold speedup. Next, we calculate the local sea surface heights based on the open water segments. Finally, we scale the freeboard calculation using the derived local sea level and achieve 8.54-fold data loading and 15.7-fold map-reduce speedup. Compared with the ATL07 (local sea level) and ATL10 (freeboard) data products, our results show higher resolutions and accuracy (96.56%).
EncodeNet: A Framework for Boosting DNN Accuracy with Entropy-driven Generalized Converting Autoencoder
Apr 21, 2024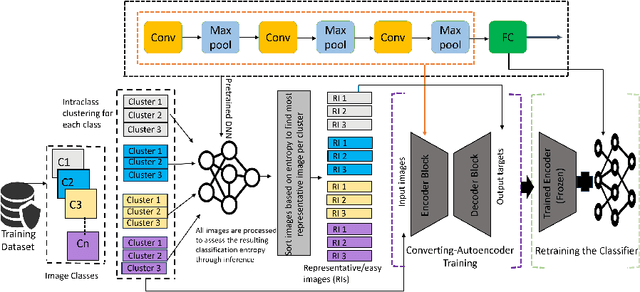
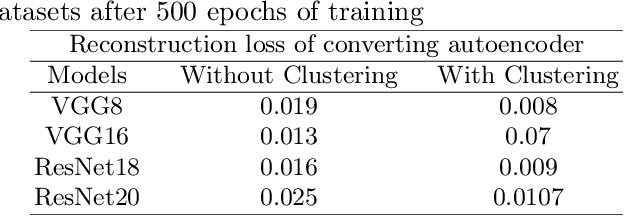
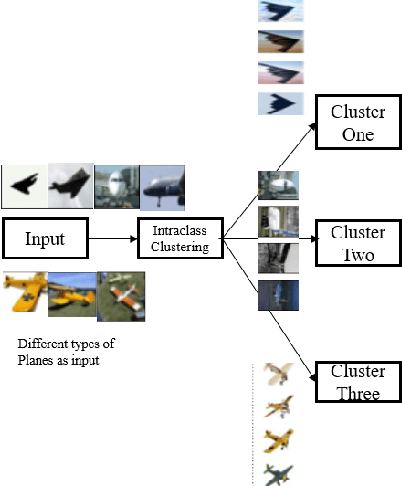
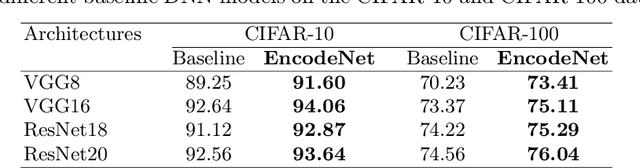
Image classification is a fundamental task in computer vision, and the quest to enhance DNN accuracy without inflating model size or latency remains a pressing concern. We make a couple of advances in this regard, leading to a novel EncodeNet design and training framework. The first advancement involves Converting Autoencoders, a novel approach that transforms images into an easy-to-classify image of its class. Our prior work that applied the Converting Autoencoder and a simple classifier in tandem achieved moderate accuracy over simple datasets, such as MNIST and FMNIST. However, on more complex datasets like CIFAR-10, the Converting Autoencoder has a large reconstruction loss, making it unsuitable for enhancing DNN accuracy. To address these limitations, we generalize the design of Converting Autoencoders by leveraging a larger class of DNNs, those with architectures comprising feature extraction layers followed by classification layers. We incorporate a generalized algorithmic design of the Converting Autoencoder and intraclass clustering to identify representative images, leading to optimized image feature learning. Next, we demonstrate the effectiveness of our EncodeNet design and training framework, improving the accuracy of well-trained baseline DNNs while maintaining the overall model size. EncodeNet's building blocks comprise the trained encoder from our generalized Converting Autoencoders transferring knowledge to a lightweight classifier network - also extracted from the baseline DNN. Our experimental results demonstrate that EncodeNet improves the accuracy of VGG16 from 92.64% to 94.05% on CIFAR-10 and RestNet20 from 74.56% to 76.04% on CIFAR-100. It outperforms state-of-the-art techniques that rely on knowledge distillation and attention mechanisms, delivering higher accuracy for models of comparable size.