 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Zero-Shot Learning using Multimodal Variational Auto-Encoder with Semantic Concepts
Paper and Code
Jun 26, 2021
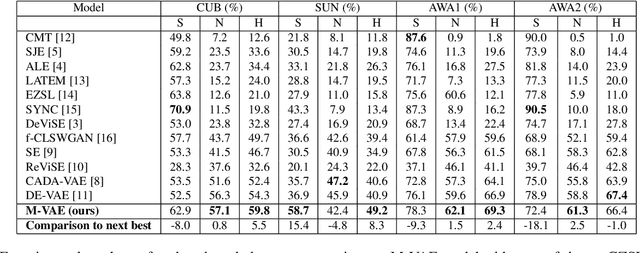


With the ever-increasing amount of data, the central challenge in multimodal learning involves limitations of labelled samples. For the task of classification, techniques such as meta-learning, zero-shot learning, and few-shot learning showcase the ability to learn information about novel classes based on prior knowledge. Recent techniques try to learn a cross-modal mapping between the semantic space and the image space. However, they tend to ignore the local and global semantic knowledge. To overcome this problem, we propose a Multimodal Variational Auto-Encoder (M-VAE) which can learn the shared latent space of image features and the semantic space. In our approach we concatenate multimodal data to a single embedding before passing it to the VAE for learning the latent space. We propose the use of a multi-modal loss during the reconstruction of the feature embedding through the decoder. Our approach is capable to correlating modalities and exploit the local and global semantic knowledge for novel sample predictions. Our experimental results using a MLP classifier on four benchmark datasets show that our proposed model outperforms the current state-of-the-art approaches for generalized zero-shot learning.