 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Look-back Horizon for Time Series Forecasting in Federated Learning
Nov 18, 2025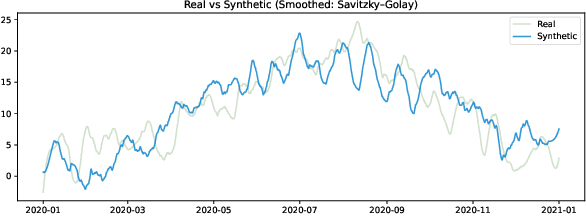
Selecting an appropriate look-back horizon remains a fundamental challenge in time series forecasting (TSF), particularly in the federated learning scenarios where data is decentralized, heterogeneous, and often non-independent. While recent work has explored horizon selection by preserving forecasting-relevant information in an intrinsic space, these approaches are primarily restricted to centralized and independently distributed settings. This paper presents a principled framework for adaptive horizon selection in federated time series forecasting through an intrinsic space formulation. We introduce a synthetic data generator (SDG) that captures essential temporal structures in client data, including autoregressive dependencies, seasonality, and trend, while incorporating client-specific heterogeneity. Building on this model, we define a transformation that maps time series windows into an intrinsic representation space with well-defined geometric and statistical properties. We then derive a decomposition of the forecasting loss into a Bayesian term, which reflects irreducible uncertainty, and an approximation term, which accounts for finite-sample effects and limited model capacity. Our analysis shows that while increasing the look-back horizon improves the identifiability of deterministic patterns, it also increases approximation error due to higher model complexity and reduced sample efficiency. We prove that the total forecasting loss is minimized at the smallest horizon where the irreducible loss starts to saturate, while the approximation loss continues to rise. This work provides a rigorous theoretical foundation for adaptive horizon selection for time series forecasting in federated learning.
ABE: A Unified Framework for Robust and Faithful Attribution-Based Explainability
May 03, 2025Attribution algorithms are essential for enhancing the interpretability and trustworthiness of deep learning models by identifying key features driving model decisions. Existing frameworks, such as InterpretDL and OmniXAI, integrate multiple attribution methods but suffer from scalability limitations, high coupling, theoretical constraints, and lack of user-friendly implementations, hindering neural network transparency and interoperability. To address these challenges, we propose Attribution-Based Explainability (ABE), a unified framework that formalizes Fundamental Attribution Methods and integrates state-of-the-art attribution algorithms while ensuring compliance with attribution axioms. ABE enables researchers to develop novel attribution techniques and enhances interpretability through four customizable modules: Robustness, Interpretability, Validation, and Data & Model. This framework provides a scalable, extensible foundation for advancing attribution-based explainability and fostering transparent AI systems. Our code is available at: https://github.com/LMBTough/ABE-XAI.
Attribution for Enhanced Explanation with Transferable Adversarial eXploration
Dec 27, 2024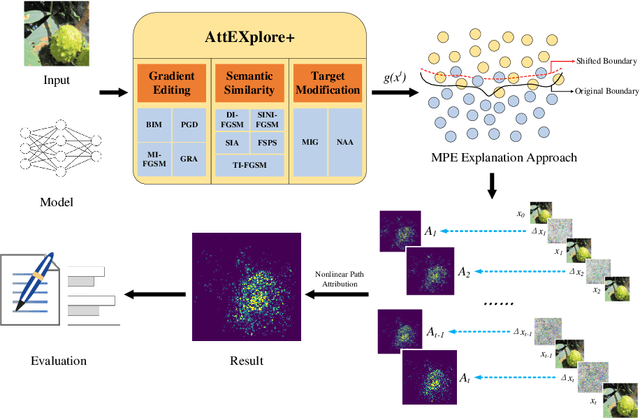
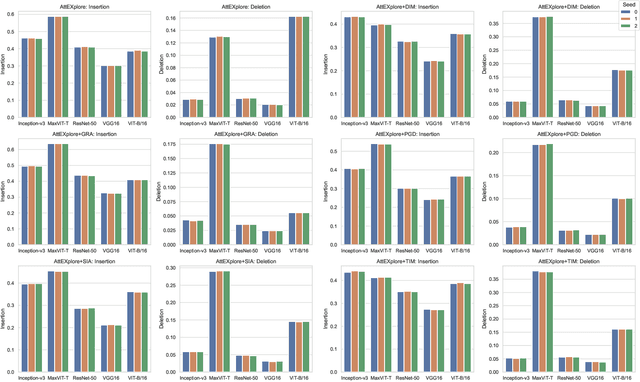
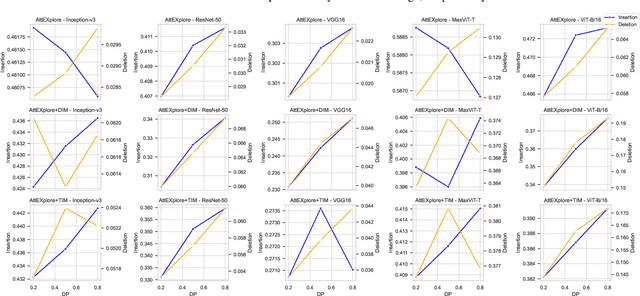
The interpretability of deep neural networks is crucial for understanding model decisions in various applications, including computer vision. AttEXplore++, an advanced framework built upon AttEXplore, enhances attribution by incorporating transferable adversarial attack methods such as MIG and GRA, significantly improving the accuracy and robustness of model explanations. We conduct extensive experiments on five models, including CNNs (Inception-v3, ResNet-50, VGG16) and vision transformers (MaxViT-T, ViT-B/16), using the ImageNet dataset. Our method achieves an average performance improvement of 7.57\% over AttEXplore and 32.62\% compared to other state-of-the-art interpretability algorithms. Using insertion and deletion scores as evaluation metrics, we show that adversarial transferability plays a vital role in enhancing attribution results. Furthermore, we explore the impact of randomness, perturbation rate, noise amplitude, and diversity probability on attribution performance, demonstrating that AttEXplore++ provides more stable and reliable explanations across various models. We release our code at: https://anonymous.4open.science/r/ATTEXPLOREP-8435/
AI-Compass: A Comprehensive and Effective Multi-module Testing Tool for AI Systems
Nov 09, 2024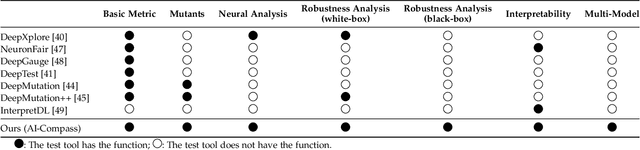

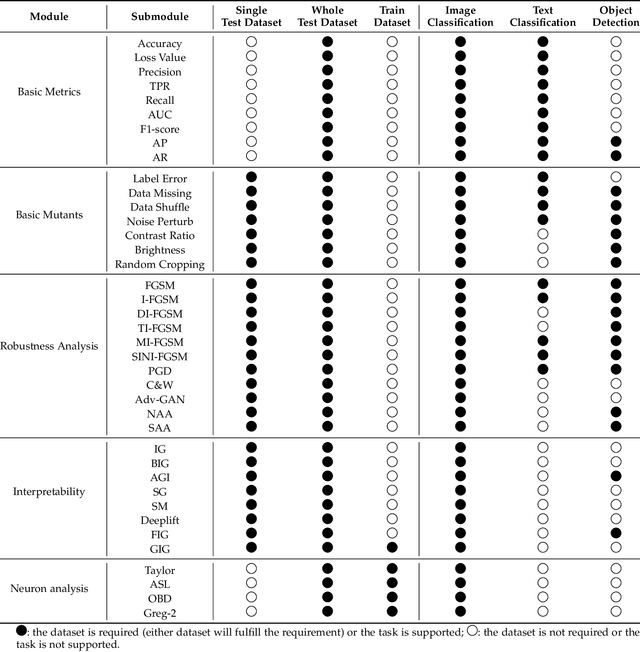

AI systems, in particular with deep learning techniques, have demonstrated superior performance for various real-world applications. Given the need for tailored optimization in specific scenarios, as well as the concerns related to the exploits of subsurface vulnerabilities, a more comprehensive and in-depth testing AI system becomes a pivotal topic. We have seen the emergence of testing tools in real-world applications that aim to expand testing capabilities. However, they often concentrate on ad-hoc tasks, rendering them unsuitable for simultaneously testing multiple aspects or components. Furthermore, trustworthiness issues arising from adversarial attacks and the challenge of interpreting deep learning models pose new challenges for developing more comprehensive and in-depth AI system testing tools. In this study, we design and implement a testing tool, \tool, to comprehensively and effectively evaluate AI systems. The tool extensively assesses multiple measurements towards adversarial robustness, model interpretability, and performs neuron analysis. The feasibility of the proposed testing tool is thoroughly validated across various modalities, including image classification, object detection, and text classification. Extensive experiments demonstrate that \tool is the state-of-the-art tool for a comprehensive assessment of the robustness and trustworthiness of AI systems. Our research sheds light on a general solution for AI systems testing landscape.
Leveraging Information Consistency in Frequency and Spatial Domain for Adversarial Attacks
Aug 22, 2024


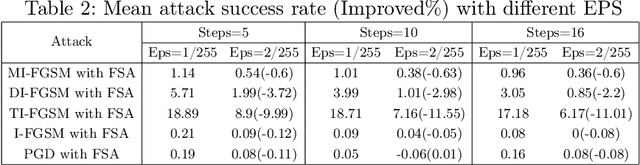
Adversarial examples are a key method to exploit deep neural networks. Using gradient information, such examples can be generated in an efficient way without altering the victim model. Recent frequency domain transformation has further enhanced the transferability of such adversarial examples, such as spectrum simulation attack. In this work, we investigate the effectiveness of frequency domain-based attacks, aligning with similar findings in the spatial domain. Furthermore, such consistency between the frequency and spatial domains provides insights into how gradient-based adversarial attacks induce perturbations across different domains, which is yet to be explored. Hence, we propose a simple, effective, and scalable gradient-based adversarial attack algorithm leveraging the information consistency in both frequency and spatial domains. We evaluate the algorithm for its effectiveness against different models. Extensive experiments demonstrate that our algorithm achieves state-of-the-art results compared to other gradient-based algorithms. Our code is available at: https://github.com/LMBTough/FSA.
Enhancing Transferability of Adversarial Attacks with GE-AdvGAN+: A Comprehensive Framework for Gradient Editing
Aug 22, 2024

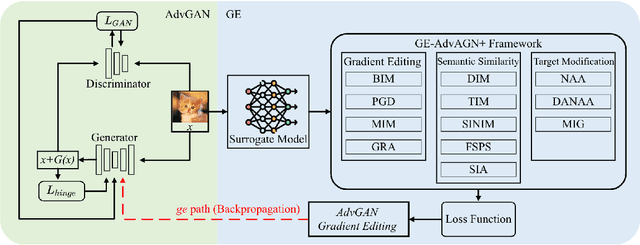

Transferable adversarial attacks pose significant threats to deep neural networks, particularly in black-box scenarios where internal model information is inaccessible. Studying adversarial attack methods helps advance the performance of defense mechanisms and explore model vulnerabilities. These methods can uncover and exploit weaknesses in models, promoting the development of more robust architectures. However, current methods for transferable attacks often come with substantial computational costs, limiting their deployment and application, especially in edge computing scenarios. Adversarial generative models, such as Generative Adversarial Networks (GANs), are characterized by their ability to generate samples without the need for retraining after an initial training phase. GE-AdvGAN, a recent method for transferable adversarial attacks, is based on this principle. In this paper, we propose a novel general framework for gradient editing-based transferable attacks, named GE-AdvGAN+, which integrates nearly all mainstream attack methods to enhance transferability while significantly reducing computational resource consumption. Our experiments demonstrate the compatibility and effectiveness of our framework. Compared to the baseline AdvGAN, our best-performing method, GE-AdvGAN++, achieves an average ASR improvement of 47.8. Additionally, it surpasses the latest competing algorithm, GE-AdvGAN, with an average ASR increase of 5.9. The framework also exhibits enhanced computational efficiency, achieving 2217.7 FPS, outperforming traditional methods such as BIM and MI-FGSM. The implementation code for our GE-AdvGAN+ framework is available at https://github.com/GEAdvGANP
Enhancing Adversarial Attacks via Parameter Adaptive Adversarial Attack
Aug 14, 2024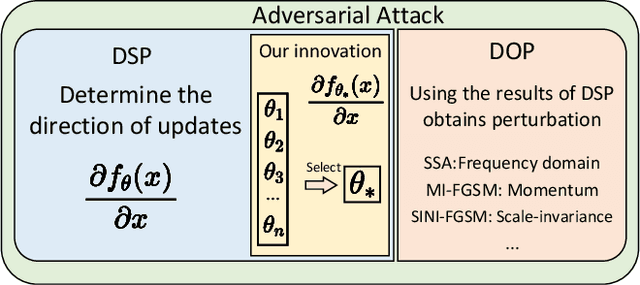
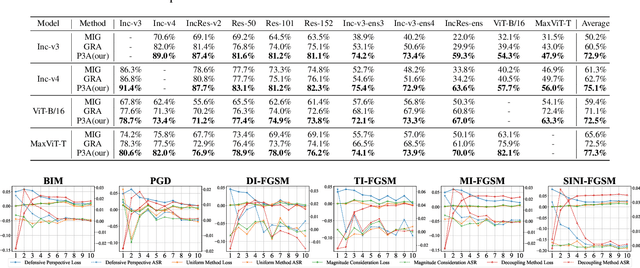
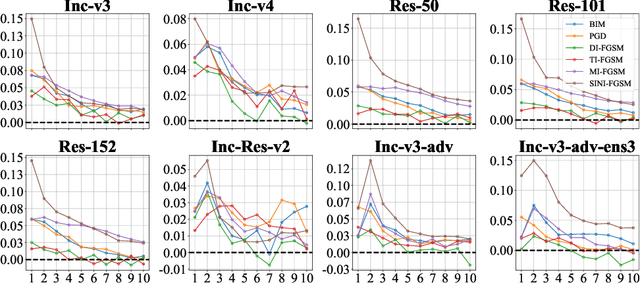
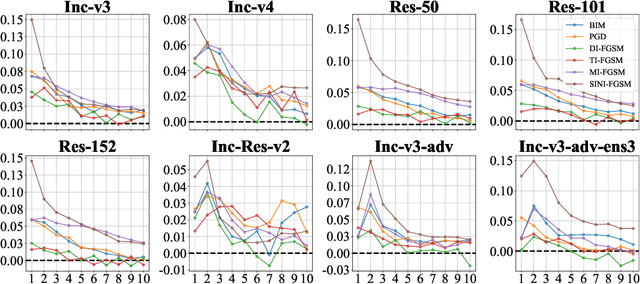
In recent times, the swift evolution of adversarial attacks has captured widespread attention, particularly concerning their transferability and other performance attributes. These techniques are primarily executed at the sample level, frequently overlooking the intrinsic parameters of models. Such neglect suggests that the perturbations introduced in adversarial samples might have the potential for further reduction. Given the essence of adversarial attacks is to impair model integrity with minimal noise on original samples, exploring avenues to maximize the utility of such perturbations is imperative. Against this backdrop, we have delved into the complexities of adversarial attack algorithms, dissecting the adversarial process into two critical phases: the Directional Supervision Process (DSP) and the Directional Optimization Process (DOP). While DSP determines the direction of updates based on the current samples and model parameters, it has been observed that existing model parameters may not always be conducive to adversarial attacks. The impact of models on adversarial efficacy is often overlooked in current research, leading to the neglect of DSP. We propose that under certain conditions, fine-tuning model parameters can significantly enhance the quality of DSP. For the first time, we propose that under certain conditions, fine-tuning model parameters can significantly improve the quality of the DSP. We provide, for the first time, rigorous mathematical definitions and proofs for these conditions, and introduce multiple methods for fine-tuning model parameters within DSP. Our extensive experiments substantiate the effectiveness of the proposed P3A method. Our code is accessible at: https://anonymous.4open.science/r/P3A-A12C/
Enhancing Model Interpretability with Local Attribution over Global Exploration
Aug 14, 2024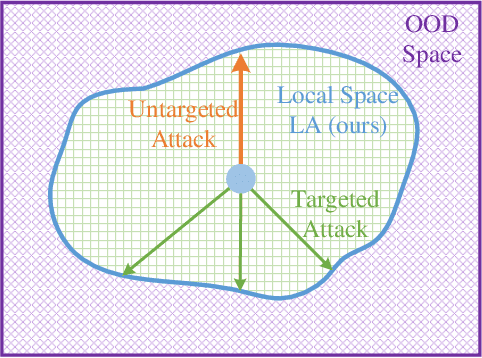

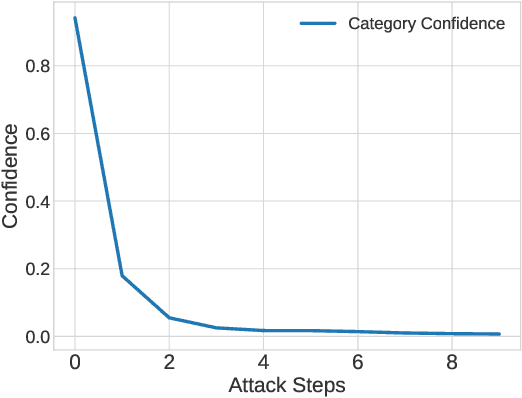

In the field of artificial intelligence, AI models are frequently described as `black boxes' due to the obscurity of their internal mechanisms. It has ignited research interest on model interpretability, especially in attribution methods that offers precise explanations of model decisions. Current attribution algorithms typically evaluate the importance of each parameter by exploring the sample space. A large number of intermediate states are introduced during the exploration process, which may reach the model's Out-of-Distribution (OOD) space. Such intermediate states will impact the attribution results, making it challenging to grasp the relative importance of features. In this paper, we firstly define the local space and its relevant properties, and we propose the Local Attribution (LA) algorithm that leverages these properties. The LA algorithm comprises both targeted and untargeted exploration phases, which are designed to effectively generate intermediate states for attribution that thoroughly encompass the local space. Compared to the state-of-the-art attribution methods, our approach achieves an average improvement of 38.21\% in attribution effectiveness. Extensive ablation studies in our experiments also validate the significance of each component in our algorithm. Our code is available at: https://github.com/LMBTough/LA/
DMS: Addressing Information Loss with More Steps for Pragmatic Adversarial Attacks
Jun 09, 2024


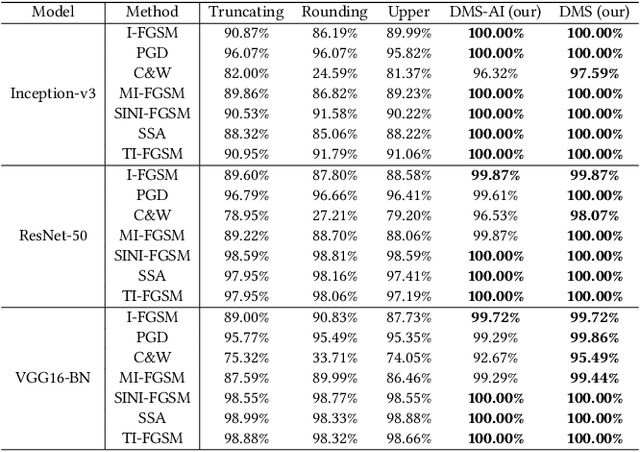
Despite the exceptional performance of deep neural networks (DNNs) across different domains, they are vulnerable to adversarial samples, in particular for tasks related to computer vision. Such vulnerability is further influenced by the digital container formats used in computers, where the discrete numerical values are commonly used for storing the pixel values. This paper examines how information loss in file formats impacts the effectiveness of adversarial attacks. Notably, we observe a pronounced hindrance to the adversarial attack performance due to the information loss of the non-integer pixel values. To address this issue, we explore to leverage the gradient information of the attack samples within the model to mitigate the information loss. We introduce the Do More Steps (DMS) algorithm, which hinges on two core techniques: gradient ascent-based \textit{adversarial integerization} (DMS-AI) and integrated gradients-based \textit{attribution selection} (DMS-AS). Our goal is to alleviate such lossy process to retain the attack performance when storing these adversarial samples digitally. In particular, DMS-AI integerizes the non-integer pixel values according to the gradient direction, and DMS-AS selects the non-integer pixels by comparing attribution results. We conduct thorough experiments to assess the effectiveness of our approach, including the implementations of the DMS-AI and DMS-AS on two large-scale datasets with various latest gradient-based attack methods. Our empirical findings conclusively demonstrate the superiority of our proposed DMS-AI and DMS-AS pixel integerization methods over the standardised methods, such as rounding, truncating and upper approaches, in maintaining attack integrity.
Benchmarking Transferable Adversarial Attacks
Feb 08, 2024
The robustness of deep learning models against adversarial attacks remains a pivotal concern. This study presents, for the first time, an exhaustive review of the transferability aspect of adversarial attacks. It systematically categorizes and critically evaluates various methodologies developed to augment the transferability of adversarial attacks. This study encompasses a spectrum of techniques, including Generative Structure, Semantic Similarity, Gradient Editing, Target Modification, and Ensemble Approach. Concurrently, this paper introduces a benchmark framework \textit{TAA-Bench}, integrating ten leading methodologies for adversarial attack transferability, thereby providing a standardized and systematic platform for comparative analysis across diverse model architectures. Through comprehensive scrutiny, we delineate the efficacy and constraints of each method, shedding light on their underlying operational principles and practical utility. This review endeavors to be a quintessential resource for both scholars and practitioners in the field, charting the complex terrain of adversarial transferability and setting a foundation for future explorations in this vital sector. The associated codebase is accessible at: https://github.com/KxPlaug/TAA-Bench