 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLSA-PFL: Robust Lightweight Secure Aggregation with Model Inconsistency Detection in Privacy-Preserving Federated Learning
Feb 13, 2025Federated Learning (FL) allows users to collaboratively train a global machine learning model by sharing local model only, without exposing their private data to a central server. This distributed learning is particularly appealing in scenarios where data privacy is crucial, and it has garnered substantial attention from both industry and academia. However, studies have revealed privacy vulnerabilities in FL, where adversaries can potentially infer sensitive information from the shared model parameters. In this paper, we present an efficient masking-based secure aggregation scheme utilizing lightweight cryptographic primitives to mitigate privacy risks. Our scheme offers several advantages over existing methods. First, it requires only a single setup phase for the entire FL training session, significantly reducing communication overhead. Second, it minimizes user-side overhead by eliminating the need for user-to-user interactions, utilizing an intermediate server layer and a lightweight key negotiation method. Third, the scheme is highly resilient to user dropouts, and the users can join at any FL round. Fourth, it can detect and defend against malicious server activities, including recently discovered model inconsistency attacks. Finally, our scheme ensures security in both semi-honest and malicious settings. We provide security analysis to formally prove the robustness of our approach. Furthermore, we implemented an end-to-end prototype of our scheme. We conducted comprehensive experiments and comparisons, which show that it outperforms existing solutions in terms of communication and computation overhead, functionality, and security.
AI-Compass: A Comprehensive and Effective Multi-module Testing Tool for AI Systems
Nov 09, 2024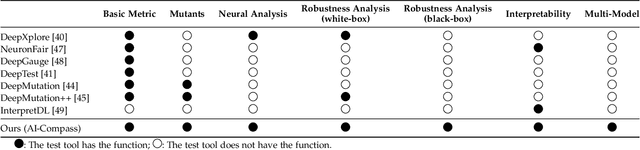

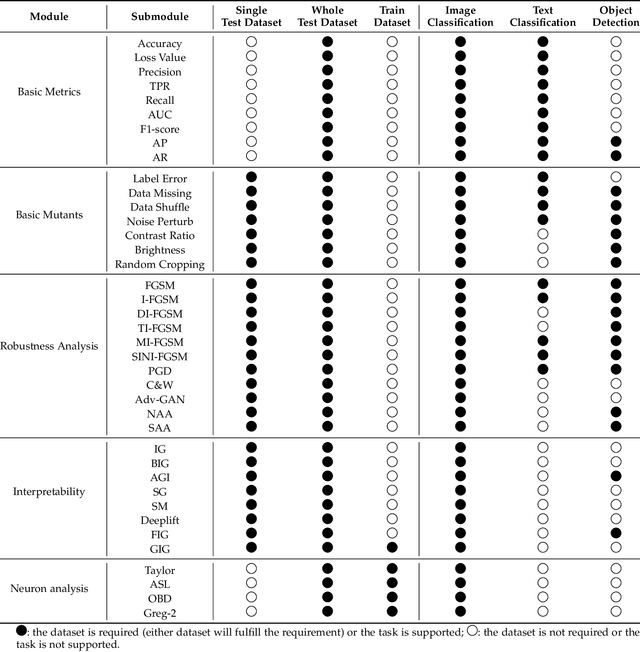

AI systems, in particular with deep learning techniques, have demonstrated superior performance for various real-world applications. Given the need for tailored optimization in specific scenarios, as well as the concerns related to the exploits of subsurface vulnerabilities, a more comprehensive and in-depth testing AI system becomes a pivotal topic. We have seen the emergence of testing tools in real-world applications that aim to expand testing capabilities. However, they often concentrate on ad-hoc tasks, rendering them unsuitable for simultaneously testing multiple aspects or components. Furthermore, trustworthiness issues arising from adversarial attacks and the challenge of interpreting deep learning models pose new challenges for developing more comprehensive and in-depth AI system testing tools. In this study, we design and implement a testing tool, \tool, to comprehensively and effectively evaluate AI systems. The tool extensively assesses multiple measurements towards adversarial robustness, model interpretability, and performs neuron analysis. The feasibility of the proposed testing tool is thoroughly validated across various modalities, including image classification, object detection, and text classification. Extensive experiments demonstrate that \tool is the state-of-the-art tool for a comprehensive assessment of the robustness and trustworthiness of AI systems. Our research sheds light on a general solution for AI systems testing landscape.