 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Constructing Adversarial Examples by Feature Watermarking
Aug 14, 2020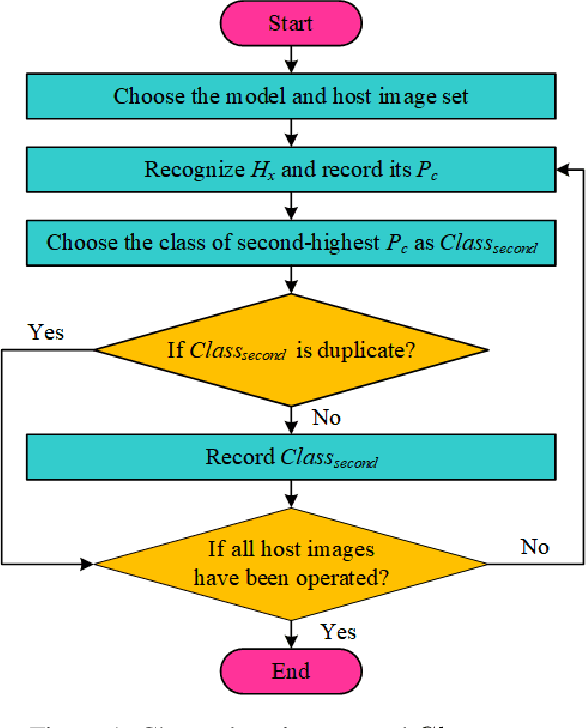

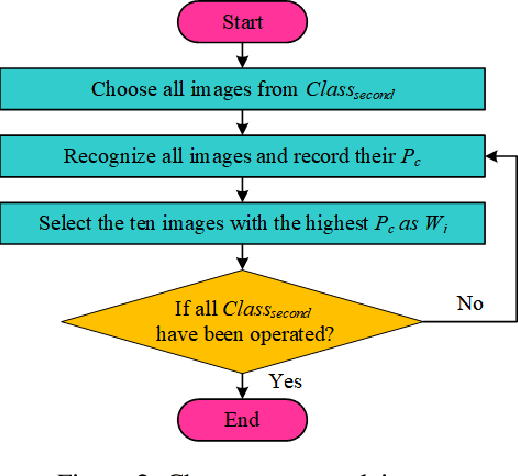
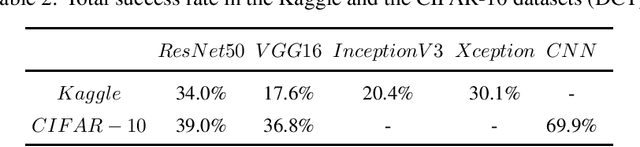
With the increasing attentions of deep learning models, attacks are also upcoming for such models. For example, an attacker may carefully construct images in specific ways (also referred to as adversarial examples) aiming to mislead the deep learning models to output incorrect classification results. Similarly, many efforts are proposed to detect and mitigate adversarial examples, usually for certain dedicated attacks. In this paper, we propose a novel digital watermark based method to generate adversarial examples for deep learning models. Specifically, partial main features of the watermark image are embedded into the host image invisibly, aiming to tamper and damage the recognition capabilities of the deep learning models. We devise an efficient mechanism to select host images and watermark images, and utilize the improved discrete wavelet transform (DWT) based Patchwork watermarking algorithm and the modified discrete cosine transform (DCT) based Patchwork watermarking algorithm. The experimental results showed that our scheme is able to generate a large number of adversarial examples efficiently. In addition, we find that using the extracted features of the image as the watermark images, can increase the success rate of an attack under certain conditions with minimal changes to the host image. To ensure repeatability, reproducibility, and code sharing, the source code is available on GitHub