 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Segment Anything for Real-Time Tumor Tracking in Cine-MRI
Oct 29, 2025In this work, we address the TrackRAD2025 challenge of real-time tumor tracking in cine-MRI sequences of the thoracic and abdominal regions under strong data scarcity constraints. Two complementary strategies were explored: (i) unsupervised registration with the IMPACT similarity metric and (ii) foundation model-based segmentation leveraging SAM 2.1 and its recent variants through prompt-based interaction. Due to the one-second runtime constraint, the SAM-based method was ultimately selected. The final configuration used SAM2.1 b+ with mask-based prompts from the first annotated slice, fine-tuned solely on the small labeled subset from TrackRAD2025. Training was configured to minimize overfitting, using 1024x1024 patches (batch size 1), standard augmentations, and a balanced Dice + IoU loss. A low uniform learning rate (0.0001) was applied to all modules (prompt encoder, decoder, Hiera backbone) to preserve generalization while adapting to annotator-specific styles. Training lasted 300 epochs (~12h on RTX A6000, 48GB). The same inference strategy was consistently applied across all anatomical sites and MRI field strengths. Test-time augmentation was considered but ultimately discarded due to negligible performance gains. The final model was selected based on the highest Dice Similarity Coefficient achieved on the validation set after fine-tuning. On the hidden test set, the model reached a Dice score of 0.8794, ranking 6th overall in the TrackRAD2025 challenge. These results highlight the strong potential of foundation models for accurate and real-time tumor tracking in MRI-guided radiotherapy.
Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS) challenge results
May 13, 2025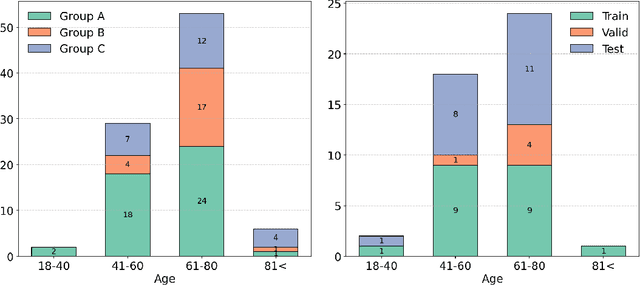
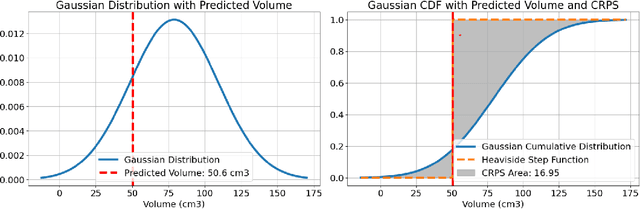

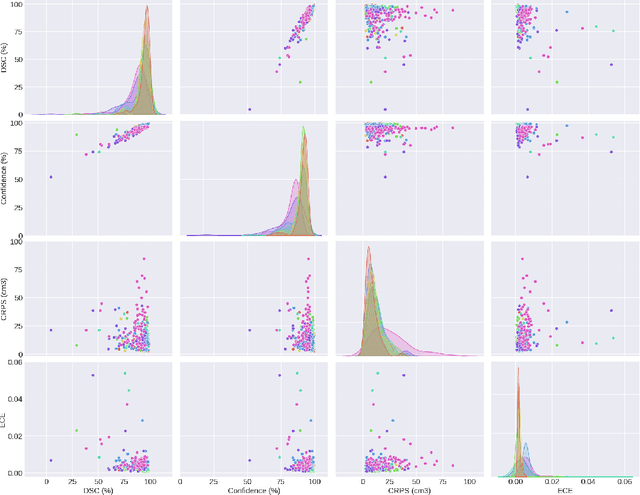
Deep learning (DL) has become the dominant approach for medical image segmentation, yet ensuring the reliability and clinical applicability of these models requires addressing key challenges such as annotation variability, calibration, and uncertainty estimation. This is why we created the Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS), which highlights the critical role of multiple annotators in establishing a more comprehensive ground truth, emphasizing that segmentation is inherently subjective and that leveraging inter-annotator variability is essential for robust model evaluation. Seven teams participated in the challenge, submitting a variety of DL models evaluated using metrics such as Dice Similarity Coefficient (DSC), Expected Calibration Error (ECE), and Continuous Ranked Probability Score (CRPS). By incorporating consensus and dissensus ground truth, we assess how DL models handle uncertainty and whether their confidence estimates align with true segmentation performance. Our findings reinforce the importance of well-calibrated models, as better calibration is strongly correlated with the quality of the results. Furthermore, we demonstrate that segmentation models trained on diverse datasets and enriched with pre-trained knowledge exhibit greater robustness, particularly in cases deviating from standard anatomical structures. Notably, the best-performing models achieved high DSC and well-calibrated uncertainty estimates. This work underscores the need for multi-annotator ground truth, thorough calibration assessments, and uncertainty-aware evaluations to develop trustworthy and clinically reliable DL-based medical image segmentation models.
IMPACT: A Generic Semantic Loss for Multimodal Medical Image Registration
Mar 31, 2025Image registration is fundamental in medical imaging, enabling precise alignment of anatomical structures for diagnosis, treatment planning, image-guided treatment or longitudinal monitoring. This work introduces IMPACT (Image Metric with Pretrained model-Agnostic Comparison for Transmodality registration), a generic semantic similarity metric designed for seamless integration into diverse image registration frameworks (such as Elastix and Voxelmorph). It compares deep learning-based features extracted from medical images without requiring task-specific training, ensuring broad applicability across various modalities. By leveraging the features of the large-scale pretrained TotalSegmentator models and the ability to integrate Segment Anything Model (SAM) and other large-scale segmentation networks, this approach offers significant advantages. It provides robust, scalable, and efficient solutions for multimodal image registration. The IMPACT loss was evaluated on five challenging registration tasks involving thoracic CT/CBCT, and pelvic MR/CT datasets. Quantitative metrics, such as Target Registration Error and Dice Similarity Coefficient, demonstrated significant improvements in anatomical alignment compared to baseline methods. Qualitative analyses further confirmed the increased robustness of the proposed metric in the face of noise, artifacts, and modality variations. IMPACT's versatility and efficiency make it a valuable tool for advancing registration performance in clinical and research applications, addressing critical challenges in multimodal medical imaging.
CNN-based real-time 2D-3D deformable registration from a single X-ray projection
Dec 15, 2022Purpose: The purpose of this paper is to present a method for real-time 2D-3D non-rigid registration using a single fluoroscopic image. Such a method can find applications in surgery, interventional radiology and radiotherapy. By estimating a three-dimensional displacement field from a 2D X-ray image, anatomical structures segmented in the preoperative scan can be projected onto the 2D image, thus providing a mixed reality view. Methods: A dataset composed of displacement fields and 2D projections of the anatomy is generated from the preoperative scan. From this dataset, a neural network is trained to recover the unknown 3D displacement field from a single projection image. Results: Our method is validated on lung 4D CT data at different stages of the lung deformation. The training is performed on a 3D CT using random (non domain-specific) diffeomorphic deformations, to which perturbations mimicking the pose uncertainty are added. The model achieves a mean TRE over a series of landmarks ranging from 2.3 to 5.5 mm depending on the amplitude of deformation. Conclusion: In this paper, a CNN-based method for real-time 2D-3D non-rigid registration is presented. This method is able to cope with pose estimation uncertainties, making it applicable to actual clinical scenarios, such as lung surgery, where the C-arm pose is planned before the intervention.
CPNet: Cycle Prototype Network for Weakly-supervised 3D Renal Compartments Segmentation on CT Images
Aug 15, 2021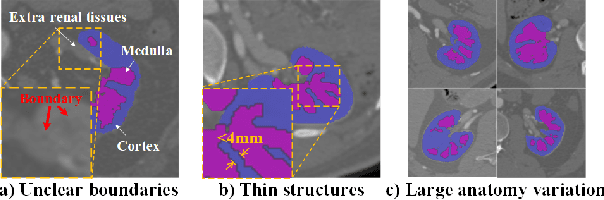
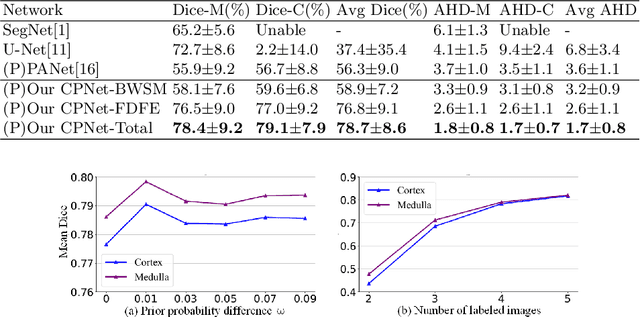
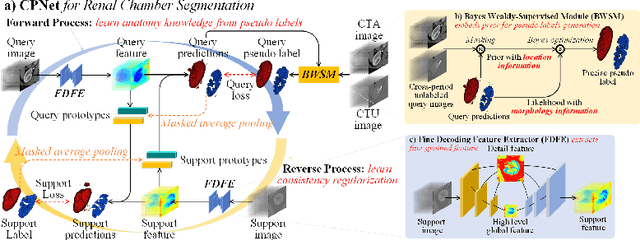
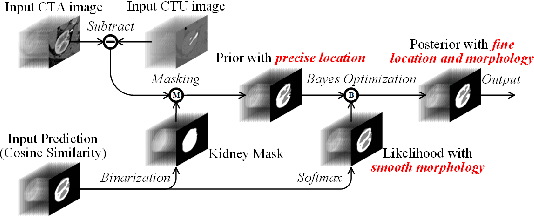
Renal compartment segmentation on CT images targets on extracting the 3D structure of renal compartments from abdominal CTA images and is of great significance to the diagnosis and treatment for kidney diseases. However, due to the unclear compartment boundary, thin compartment structure and large anatomy variation of 3D kidney CT images, deep-learning based renal compartment segmentation is a challenging task. We propose a novel weakly supervised learning framework, Cycle Prototype Network, for 3D renal compartment segmentation. It has three innovations: 1) A Cycle Prototype Learning (CPL) is proposed to learn consistency for generalization. It learns from pseudo labels through the forward process and learns consistency regularization through the reverse process. The two processes make the model robust to noise and label-efficient. 2) We propose a Bayes Weakly Supervised Module (BWSM) based on cross-period prior knowledge. It learns prior knowledge from cross-period unlabeled data and perform error correction automatically, thus generates accurate pseudo labels. 3) We present a Fine Decoding Feature Extractor (FDFE) for fine-grained feature extraction. It combines global morphology information and local detail information to obtain feature maps with sharp detail, so the model will achieve fine segmentation on thin structures. Our model achieves Dice of 79.1% and 78.7% with only four labeled images, achieving a significant improvement by about 20% than typical prototype model PANet.
Deep Complementary Joint Model for Complex Scene Registration and Few-shot Segmentation on Medical Images
Aug 03, 2020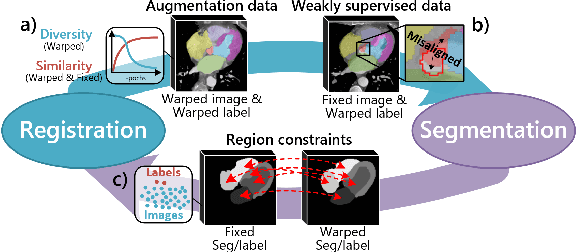

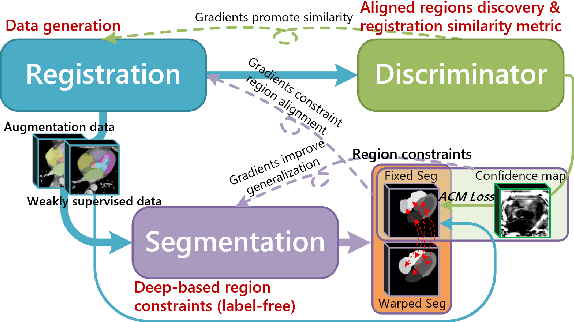
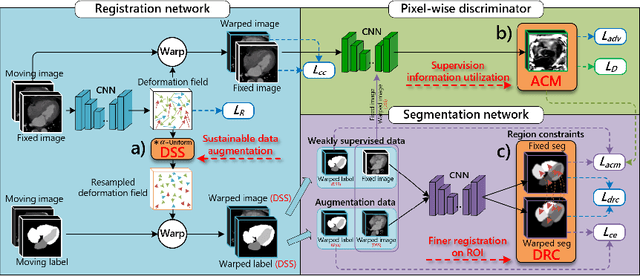
Deep learning-based medical image registration and segmentation joint models utilize the complementarity (augmentation data or weakly supervised data from registration, region constraints from segmentation) to bring mutual improvement in complex scene and few-shot situation. However, further adoption of the joint models are hindered: 1) the diversity of augmentation data is reduced limiting the further enhancement of segmentation, 2) misaligned regions in weakly supervised data disturb the training process, 3) lack of label-based region constraints in few-shot situation limits the registration performance. We propose a novel Deep Complementary Joint Model (DeepRS) for complex scene registration and few-shot segmentation. We embed a perturbation factor in the registration to increase the activity of deformation thus maintaining the augmentation data diversity. We take a pixel-wise discriminator to extract alignment confidence maps which highlight aligned regions in weakly supervised data so the misaligned regions' disturbance will be suppressed via weighting. The outputs from segmentation model are utilized to implement deep-based region constraints thus relieving the label requirements and bringing fine registration. Extensive experiments on the CT dataset of MM-WHS 2017 Challenge show great advantages of our DeepRS that outperforms the existing state-of-the-art models.
Sub-pixel matching method for low-resolution thermal stereo images
Nov 30, 2019
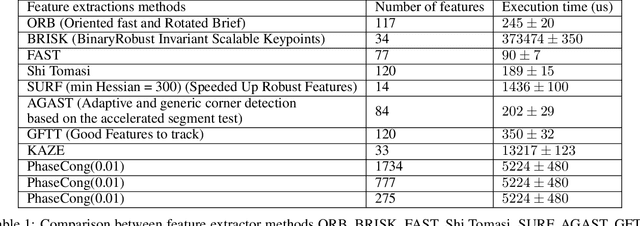
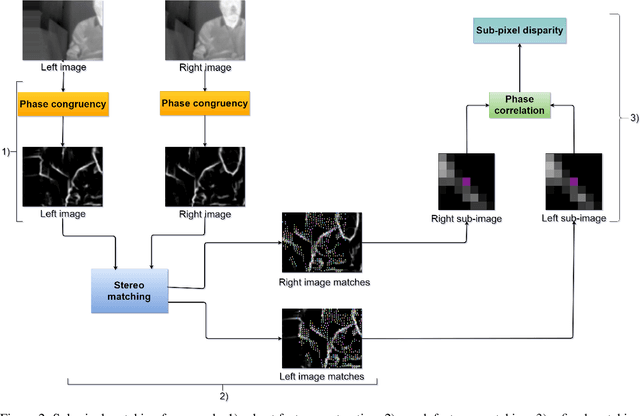
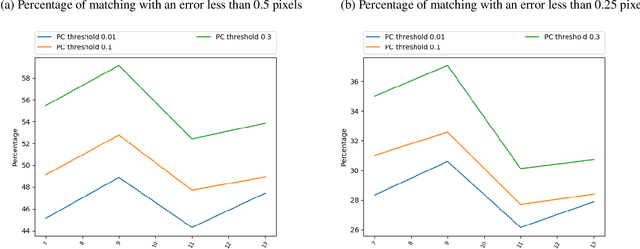
In the context of a localization and tracking application, we developed a stereo vision system based on cheap low-resolution 80x60 pixels thermal cameras. We proposed a threefold sub-pixel stereo matching framework (called ST for Subpixel Thermal): 1) robust features extraction method based on phase congruency, 2) rough matching of these features in pixel precision, and 3) refined matching in sub-pixel accuracy based on local phase coherence. We performed experiments on our very low-resolution thermal images (acquired using a stereo system we manufactured) as for high-resolution images from a benchmark dataset. Even if phase congruency computation time is high, it was able to extract two times more features than state-of-the-art methods such as ORB or SURF. We proposed a modified version of the phase correlation applied in the phase congruency feature space for sub-pixel matching. Using simulated stereo, we investigated how the phase congruency threshold and the sub-image size of sub-pixel matching can influence the accuracy. We then proved that given our stereo setup and the resolution of our images, being wrong of 1 pixel leads to a 500 mm error in the Z position of the point. Finally, we showed that our method could extract four times more matches than a baseline method ORB + OpenCV KNN matching on low-resolution images. Moreover, our matches were more robust. More precisely, when projecting points of a standing person, ST got a standard deviation of 300 mm when ORB + OpenCV KNN gave more than 1000 mm.