 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-LDM: A Universal Framework for Text-Grounded Object Generation in Real Images
Mar 15, 2024
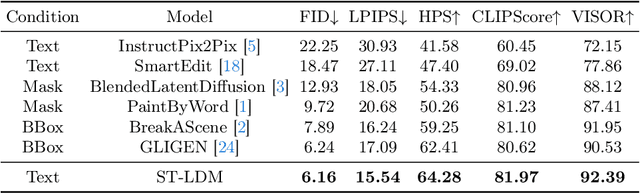
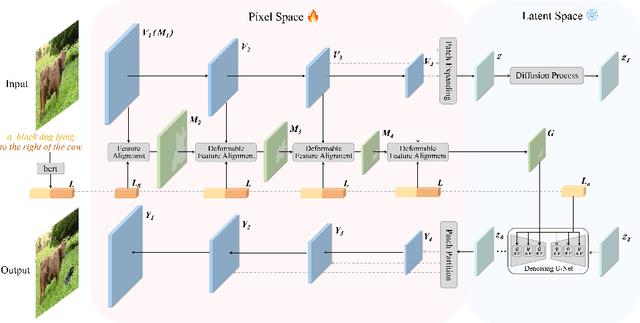
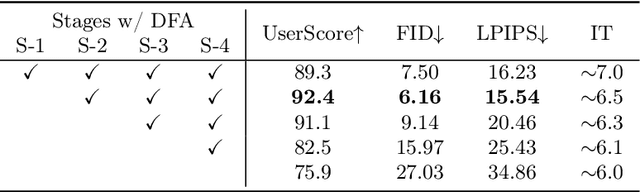
We present a novel image editing scenario termed Text-grounded Object Generation (TOG), defined as generating a new object in the real image spatially conditioned by textual descriptions. Existing diffusion models exhibit limitations of spatial perception in complex real-world scenes, relying on additional modalities to enforce constraints, and TOG imposes heightened challenges on scene comprehension under the weak supervision of linguistic information. We propose a universal framework ST-LDM based on Swin-Transformer, which can be integrated into any latent diffusion model with training-free backward guidance. ST-LDM encompasses a global-perceptual autoencoder with adaptable compression scales and hierarchical visual features, parallel with deformable multimodal transformer to generate region-wise guidance for the subsequent denoising process. We transcend the limitation of traditional attention mechanisms that only focus on existing visual features by introducing deformable feature alignment to hierarchically refine spatial positioning fused with multi-scale visual and linguistic information. Extensive Experiments demonstrate that our model enhances the localization of attention mechanisms while preserving the generative capabilities inherent to diffusion models.
Rethinking Referring Object Removal
Mar 14, 2024
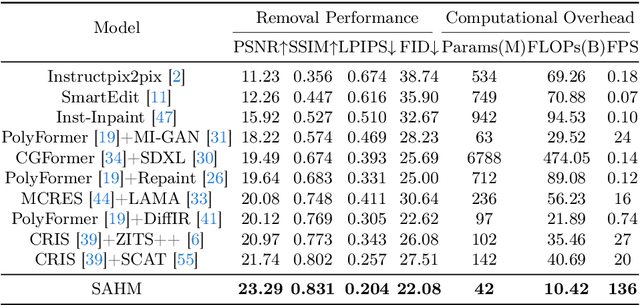


Referring object removal refers to removing the specific object in an image referred by natural language expressions and filling the missing region with reasonable semantics. To address this task, we construct the ComCOCO, a synthetic dataset consisting of 136,495 referring expressions for 34,615 objects in 23,951 image pairs. Each pair contains an image with referring expressions and the ground truth after elimination. We further propose an end-to-end syntax-aware hybrid mapping network with an encoding-decoding structure. Linguistic features are hierarchically extracted at the syntactic level and fused in the downsampling process of visual features with multi-head attention. The feature-aligned pyramid network is leveraged to generate segmentation masks and replace internal pixels with region affinity learned from external semantics in high-level feature maps. Extensive experiments demonstrate that our model outperforms diffusion models and two-stage methods which process the segmentation and inpainting task separately by a significant margin.
Multiscale Low-Frequency Memory Network for Improved Feature Extraction in Convolutional Neural Networks
Mar 13, 2024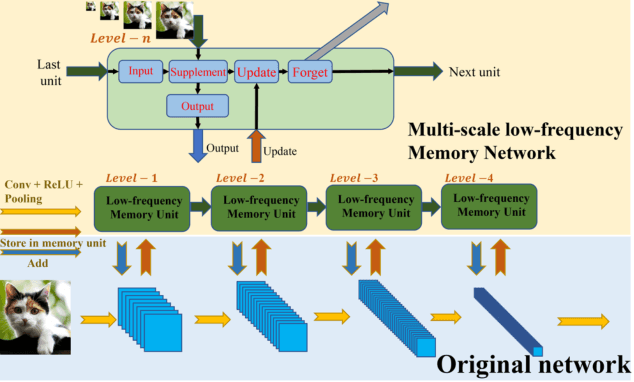
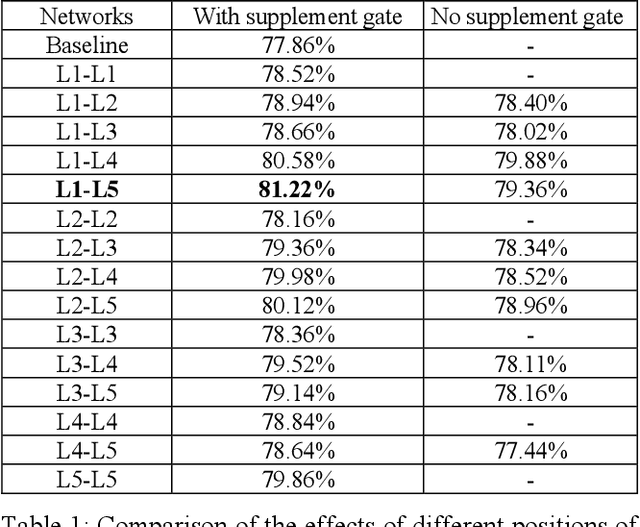
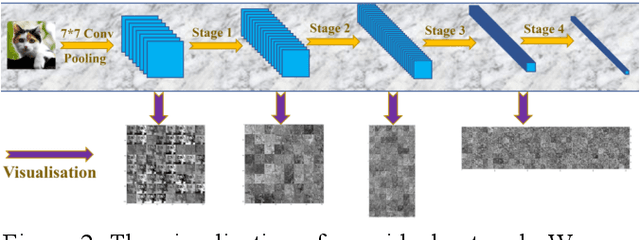
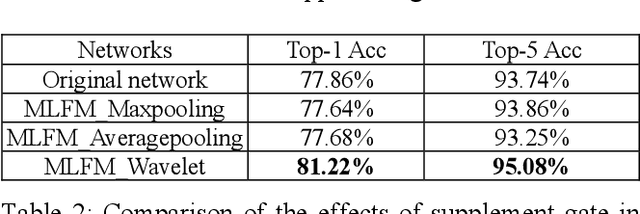
Deep learning and Convolutional Neural Networks (CNNs) have driven major transformations in diverse research areas. However, their limitations in handling low-frequency information present obstacles in certain tasks like interpreting global structures or managing smooth transition images. Despite the promising performance of transformer structures in numerous tasks, their intricate optimization complexities highlight the persistent need for refined CNN enhancements using limited resources. Responding to these complexities, we introduce a novel framework, the Multiscale Low-Frequency Memory (MLFM) Network, with the goal to harness the full potential of CNNs while keeping their complexity unchanged. The MLFM efficiently preserves low-frequency information, enhancing performance in targeted computer vision tasks. Central to our MLFM is the Low-Frequency Memory Unit (LFMU), which stores various low-frequency data and forms a parallel channel to the core network. A key advantage of MLFM is its seamless compatibility with various prevalent networks, requiring no alterations to their original core structure. Testing on ImageNet demonstrated substantial accuracy improvements in multiple 2D CNNs, including ResNet, MobileNet, EfficientNet, and ConvNeXt. Furthermore, we showcase MLFM's versatility beyond traditional image classification by successfully integrating it into image-to-image translation tasks, specifically in semantic segmentation networks like FCN and U-Net. In conclusion, our work signifies a pivotal stride in the journey of optimizing the efficacy and efficiency of CNNs with limited resources. This research builds upon the existing CNN foundations and paves the way for future advancements in computer vision. Our codes are available at https://github.com/AlphaWuSeu/ MLFM.
Beyond Strong labels: Weakly-supervised Learning Based on Gaussian Pseudo Labels for The Segmentation of Ellipse-like Vascular Structures in Non-contrast CTs
Feb 05, 2024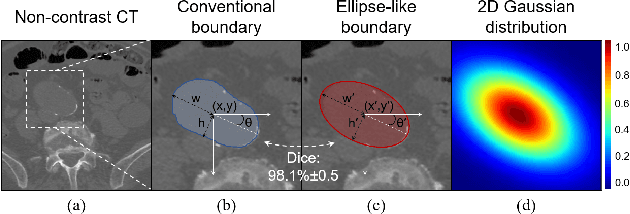

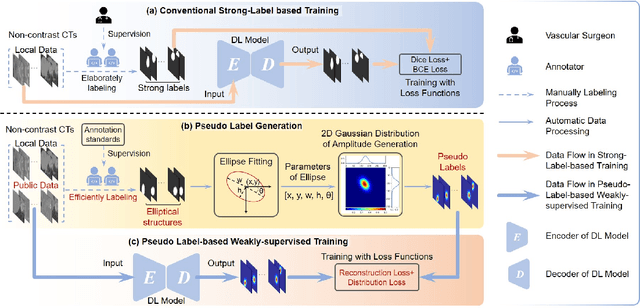
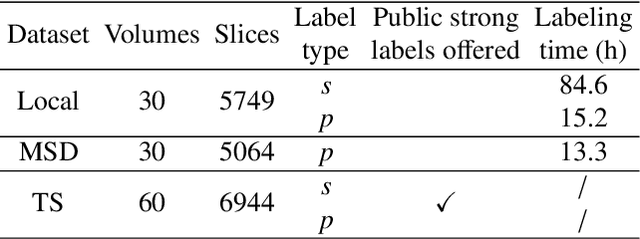
Deep-learning-based automated segmentation of vascular structures in preoperative CT scans contributes to computer-assisted diagnosis and intervention procedure in vascular diseases. While CT angiography (CTA) is the common standard, non-contrast CT imaging is significant as a contrast-risk-free alternative, avoiding complications associated with contrast agents. However, the challenges of labor-intensive labeling and high labeling variability due to the ambiguity of vascular boundaries hinder conventional strong-label-based, fully-supervised learning in non-contrast CTs. This paper introduces a weakly-supervised framework using ellipses' topology in slices, including 1) an efficient annotation process based on predefined standards, 2) ellipse-fitting processing, 3) the generation of 2D Gaussian heatmaps serving as pseudo labels, 4) a training process through a combination of voxel reconstruction loss and distribution loss with the pseudo labels. We assess the effectiveness of the proposed method on one local and two public datasets comprising non-contrast CT scans, particularly focusing on the abdominal aorta. On the local dataset, our weakly-supervised learning approach based on pseudo labels outperforms strong-label-based fully-supervised learning (1.54\% of Dice score on average), reducing labeling time by around 82.0\%. The efficiency in generating pseudo labels allows the inclusion of label-agnostic external data in the training set, leading to an additional improvement in performance (2.74\% of Dice score on average) with a reduction of 66.3\% labeling time, where the labeling time remains considerably less than that of strong labels. On the public dataset, the pseudo labels achieve an overall improvement of 1.95\% in Dice score for 2D models while a reduction of 11.65 voxel spacing in Hausdorff distance for 3D model.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022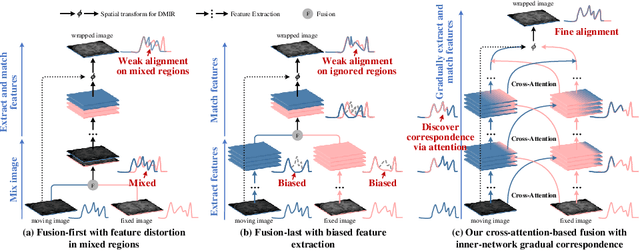
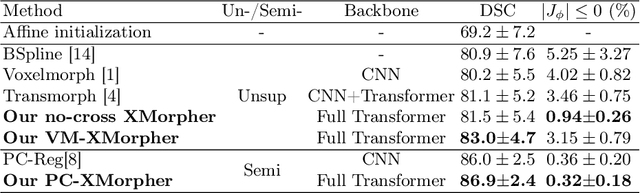
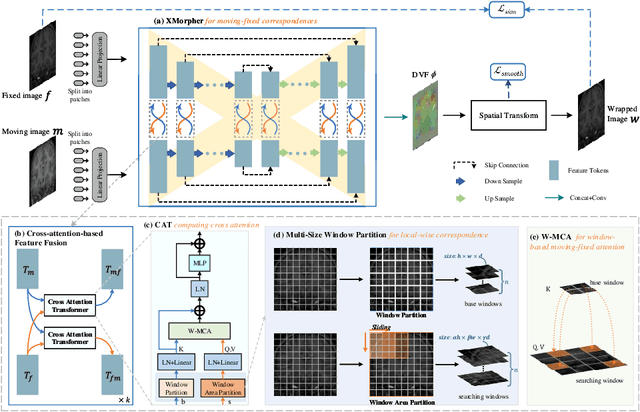
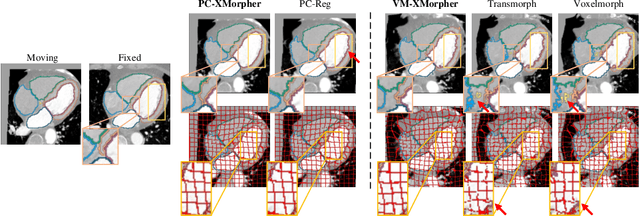
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher
MNet: Rethinking 2D/3D Networks for Anisotropic Medical Image Segmentation
May 10, 2022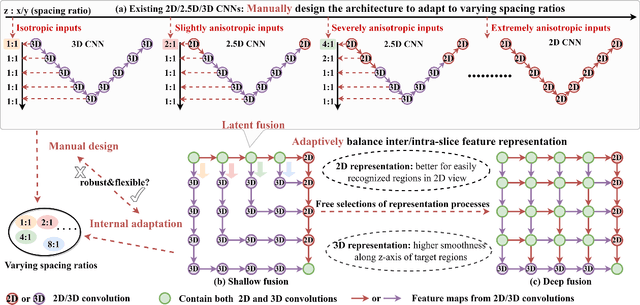
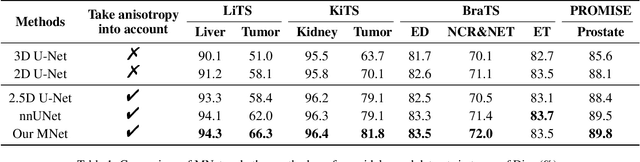
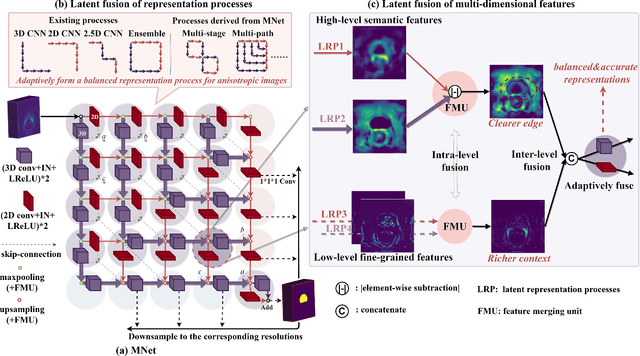

The nature of thick-slice scanning causes severe inter-slice discontinuities of 3D medical images, and the vanilla 2D/3D convolutional neural networks (CNNs) fail to represent sparse inter-slice information and dense intra-slice information in a balanced way, leading to severe underfitting to inter-slice features (for vanilla 2D CNNs) and overfitting to noise from long-range slices (for vanilla 3D CNNs). In this work, a novel mesh network (MNet) is proposed to balance the spatial representation inter axes via learning. 1) Our MNet latently fuses plenty of representation processes by embedding multi-dimensional convolutions deeply into basic modules, making the selections of representation processes flexible, thus balancing representation for sparse inter-slice information and dense intra-slice information adaptively. 2) Our MNet latently fuses multi-dimensional features inside each basic module, simultaneously taking the advantages of 2D (high segmentation accuracy of the easily recognized regions in 2D view) and 3D (high smoothness of 3D organ contour) representations, thus obtaining more accurate modeling for target regions. Comprehensive experiments are performed on four public datasets (CT\&MR), the results consistently demonstrate the proposed MNet outperforms the other methods. The code and datasets are available at: https://github.com/zfdong-code/MNet
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021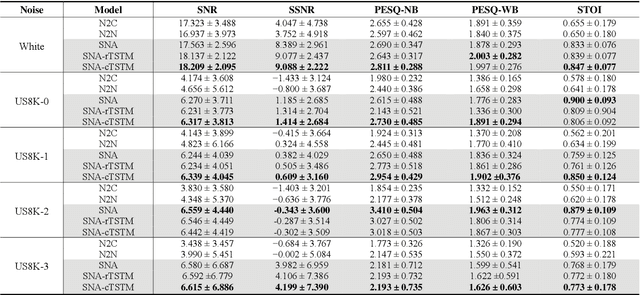
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
EnMcGAN: Adversarial Ensemble Learning for 3D Complete Renal Structures Segmentation
Jun 08, 2021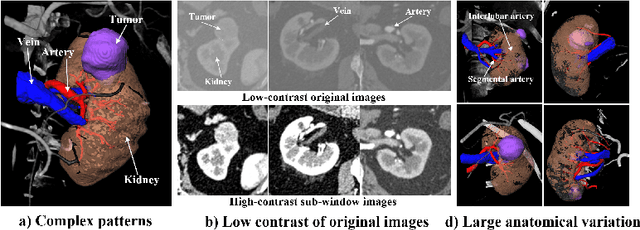

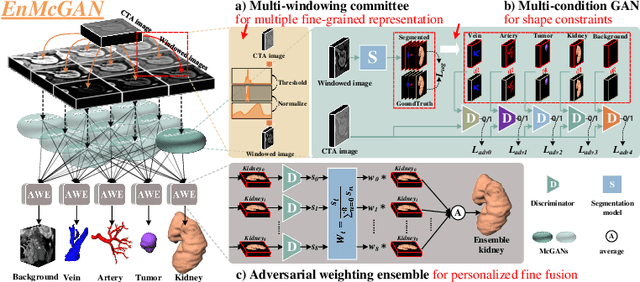
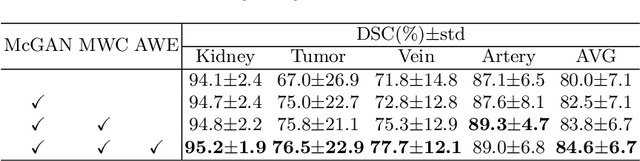
3D complete renal structures(CRS) segmentation targets on segmenting the kidneys, tumors, renal arteries and veins in one inference. Once successful, it will provide preoperative plans and intraoperative guidance for laparoscopic partial nephrectomy(LPN), playing a key role in the renal cancer treatment. However, no success has been reported in 3D CRS segmentation due to the complex shapes of renal structures, low contrast and large anatomical variation. In this study, we utilize the adversarial ensemble learning and propose Ensemble Multi-condition GAN(EnMcGAN) for 3D CRS segmentation for the first time. Its contribution is three-fold. 1)Inspired by windowing, we propose the multi-windowing committee which divides CTA image into multiple narrow windows with different window centers and widths enhancing the contrast for salient boundaries and soft tissues. And then, it builds an ensemble segmentation model on these narrow windows to fuse the segmentation superiorities and improve whole segmentation quality. 2)We propose the multi-condition GAN which equips the segmentation model with multiple discriminators to encourage the segmented structures meeting their real shape conditions, thus improving the shape feature extraction ability. 3)We propose the adversarial weighted ensemble module which uses the trained discriminators to evaluate the quality of segmented structures, and normalizes these evaluation scores for the ensemble weights directed at the input image, thus enhancing the ensemble results. 122 patients are enrolled in this study and the mean Dice coefficient of the renal structures achieves 84.6%. Extensive experiments with promising results on renal structures reveal powerful segmentation accuracy and great clinical significance in renal cancer treatment.
Deep Complementary Joint Model for Complex Scene Registration and Few-shot Segmentation on Medical Images
Aug 03, 2020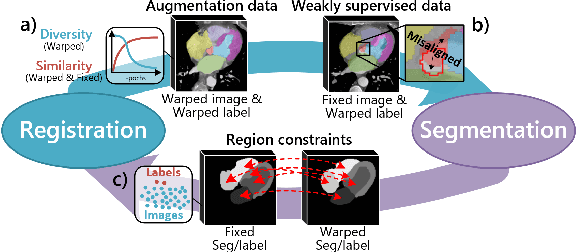

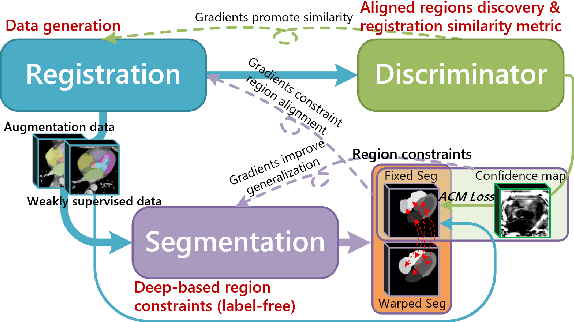
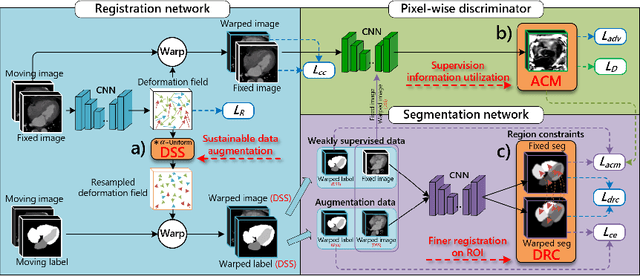
Deep learning-based medical image registration and segmentation joint models utilize the complementarity (augmentation data or weakly supervised data from registration, region constraints from segmentation) to bring mutual improvement in complex scene and few-shot situation. However, further adoption of the joint models are hindered: 1) the diversity of augmentation data is reduced limiting the further enhancement of segmentation, 2) misaligned regions in weakly supervised data disturb the training process, 3) lack of label-based region constraints in few-shot situation limits the registration performance. We propose a novel Deep Complementary Joint Model (DeepRS) for complex scene registration and few-shot segmentation. We embed a perturbation factor in the registration to increase the activity of deformation thus maintaining the augmentation data diversity. We take a pixel-wise discriminator to extract alignment confidence maps which highlight aligned regions in weakly supervised data so the misaligned regions' disturbance will be suppressed via weighting. The outputs from segmentation model are utilized to implement deep-based region constraints thus relieving the label requirements and bringing fine registration. Extensive experiments on the CT dataset of MM-WHS 2017 Challenge show great advantages of our DeepRS that outperforms the existing state-of-the-art models.
Generative networks as inverse problems with fractional wavelet scattering networks
Jul 28, 2020
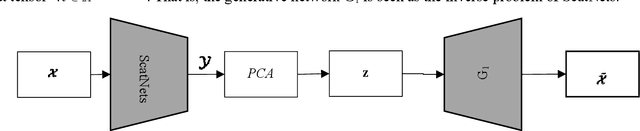
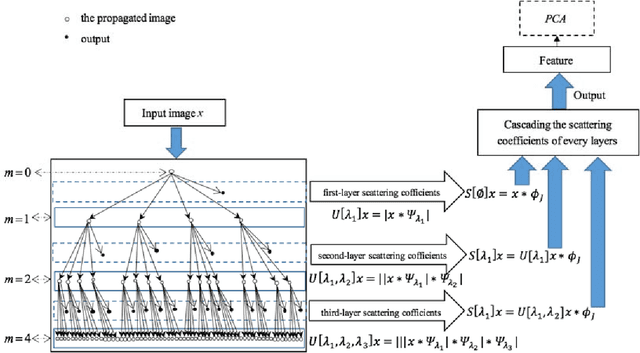
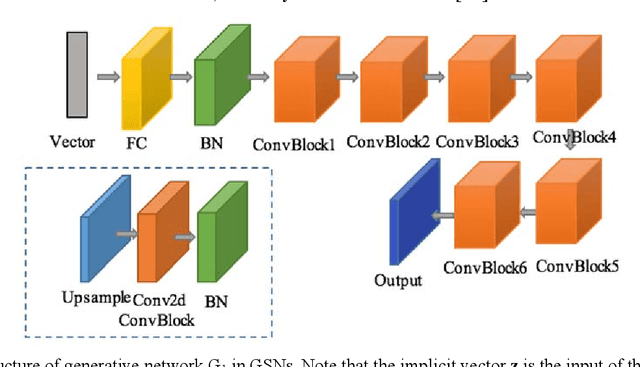
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.