 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-LDM: A Universal Framework for Text-Grounded Object Generation in Real Images
Mar 15, 2024
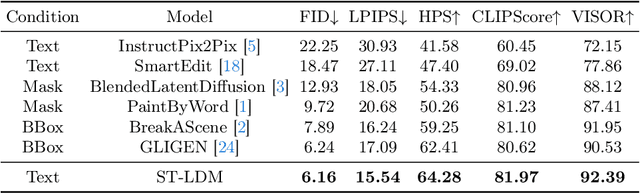
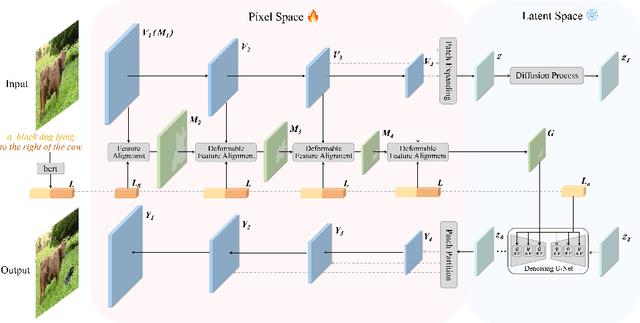
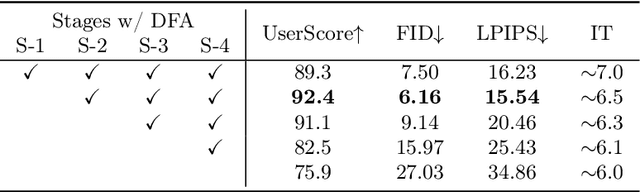
We present a novel image editing scenario termed Text-grounded Object Generation (TOG), defined as generating a new object in the real image spatially conditioned by textual descriptions. Existing diffusion models exhibit limitations of spatial perception in complex real-world scenes, relying on additional modalities to enforce constraints, and TOG imposes heightened challenges on scene comprehension under the weak supervision of linguistic information. We propose a universal framework ST-LDM based on Swin-Transformer, which can be integrated into any latent diffusion model with training-free backward guidance. ST-LDM encompasses a global-perceptual autoencoder with adaptable compression scales and hierarchical visual features, parallel with deformable multimodal transformer to generate region-wise guidance for the subsequent denoising process. We transcend the limitation of traditional attention mechanisms that only focus on existing visual features by introducing deformable feature alignment to hierarchically refine spatial positioning fused with multi-scale visual and linguistic information. Extensive Experiments demonstrate that our model enhances the localization of attention mechanisms while preserving the generative capabilities inherent to diffusion models.
Rethinking Referring Object Removal
Mar 14, 2024
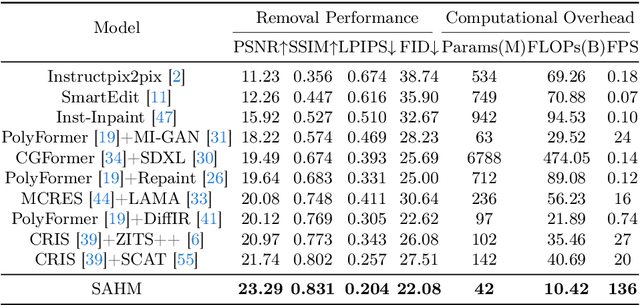


Referring object removal refers to removing the specific object in an image referred by natural language expressions and filling the missing region with reasonable semantics. To address this task, we construct the ComCOCO, a synthetic dataset consisting of 136,495 referring expressions for 34,615 objects in 23,951 image pairs. Each pair contains an image with referring expressions and the ground truth after elimination. We further propose an end-to-end syntax-aware hybrid mapping network with an encoding-decoding structure. Linguistic features are hierarchically extracted at the syntactic level and fused in the downsampling process of visual features with multi-head attention. The feature-aligned pyramid network is leveraged to generate segmentation masks and replace internal pixels with region affinity learned from external semantics in high-level feature maps. Extensive experiments demonstrate that our model outperforms diffusion models and two-stage methods which process the segmentation and inpainting task separately by a significant margin.