 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-LDM: A Universal Framework for Text-Grounded Object Generation in Real Images
Mar 15, 2024
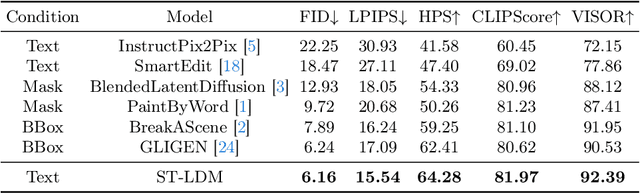
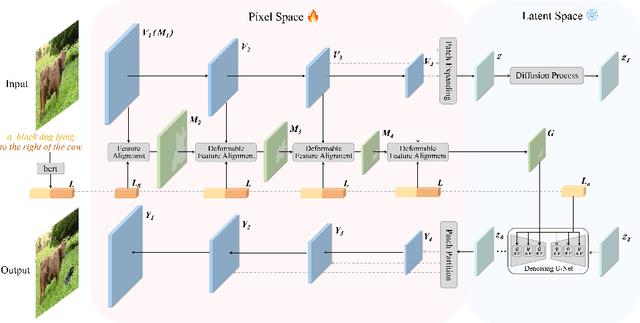
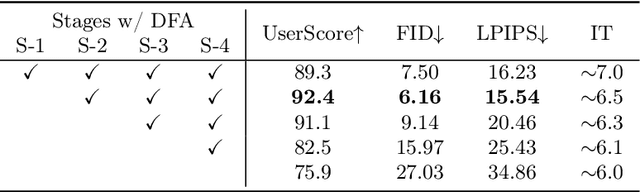
We present a novel image editing scenario termed Text-grounded Object Generation (TOG), defined as generating a new object in the real image spatially conditioned by textual descriptions. Existing diffusion models exhibit limitations of spatial perception in complex real-world scenes, relying on additional modalities to enforce constraints, and TOG imposes heightened challenges on scene comprehension under the weak supervision of linguistic information. We propose a universal framework ST-LDM based on Swin-Transformer, which can be integrated into any latent diffusion model with training-free backward guidance. ST-LDM encompasses a global-perceptual autoencoder with adaptable compression scales and hierarchical visual features, parallel with deformable multimodal transformer to generate region-wise guidance for the subsequent denoising process. We transcend the limitation of traditional attention mechanisms that only focus on existing visual features by introducing deformable feature alignment to hierarchically refine spatial positioning fused with multi-scale visual and linguistic information. Extensive Experiments demonstrate that our model enhances the localization of attention mechanisms while preserving the generative capabilities inherent to diffusion models.
Rethinking Referring Object Removal
Mar 14, 2024
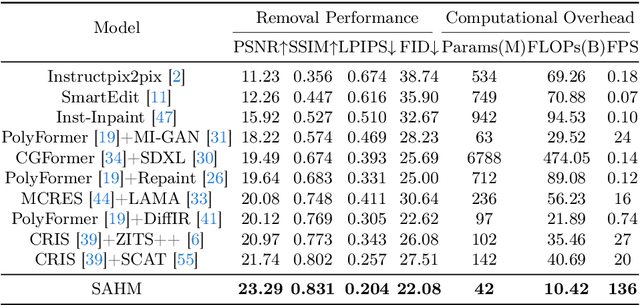


Referring object removal refers to removing the specific object in an image referred by natural language expressions and filling the missing region with reasonable semantics. To address this task, we construct the ComCOCO, a synthetic dataset consisting of 136,495 referring expressions for 34,615 objects in 23,951 image pairs. Each pair contains an image with referring expressions and the ground truth after elimination. We further propose an end-to-end syntax-aware hybrid mapping network with an encoding-decoding structure. Linguistic features are hierarchically extracted at the syntactic level and fused in the downsampling process of visual features with multi-head attention. The feature-aligned pyramid network is leveraged to generate segmentation masks and replace internal pixels with region affinity learned from external semantics in high-level feature maps. Extensive experiments demonstrate that our model outperforms diffusion models and two-stage methods which process the segmentation and inpainting task separately by a significant margin.
Multiscale Low-Frequency Memory Network for Improved Feature Extraction in Convolutional Neural Networks
Mar 13, 2024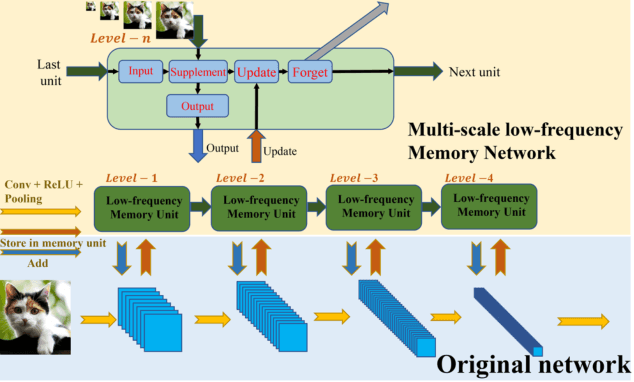
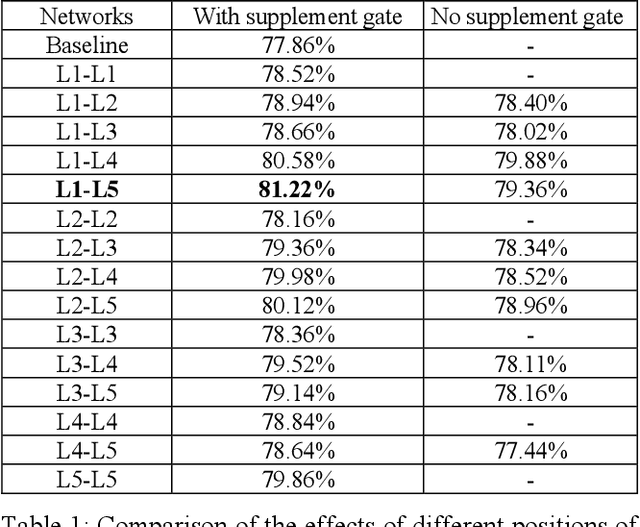
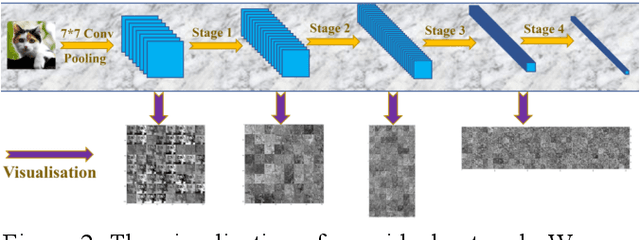
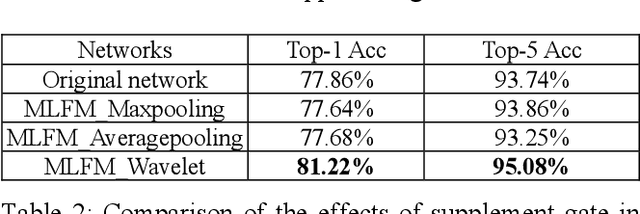
Deep learning and Convolutional Neural Networks (CNNs) have driven major transformations in diverse research areas. However, their limitations in handling low-frequency information present obstacles in certain tasks like interpreting global structures or managing smooth transition images. Despite the promising performance of transformer structures in numerous tasks, their intricate optimization complexities highlight the persistent need for refined CNN enhancements using limited resources. Responding to these complexities, we introduce a novel framework, the Multiscale Low-Frequency Memory (MLFM) Network, with the goal to harness the full potential of CNNs while keeping their complexity unchanged. The MLFM efficiently preserves low-frequency information, enhancing performance in targeted computer vision tasks. Central to our MLFM is the Low-Frequency Memory Unit (LFMU), which stores various low-frequency data and forms a parallel channel to the core network. A key advantage of MLFM is its seamless compatibility with various prevalent networks, requiring no alterations to their original core structure. Testing on ImageNet demonstrated substantial accuracy improvements in multiple 2D CNNs, including ResNet, MobileNet, EfficientNet, and ConvNeXt. Furthermore, we showcase MLFM's versatility beyond traditional image classification by successfully integrating it into image-to-image translation tasks, specifically in semantic segmentation networks like FCN and U-Net. In conclusion, our work signifies a pivotal stride in the journey of optimizing the efficacy and efficiency of CNNs with limited resources. This research builds upon the existing CNN foundations and paves the way for future advancements in computer vision. Our codes are available at https://github.com/AlphaWuSeu/ MLFM.
FedSODA: Federated Cross-assessment and Dynamic Aggregation for Histopathology Segmentation
Dec 20, 2023


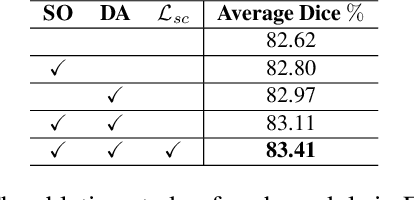
Federated learning (FL) for histopathology image segmentation involving multiple medical sites plays a crucial role in advancing the field of accurate disease diagnosis and treatment. However, it is still a task of great challenges due to the sample imbalance across clients and large data heterogeneity from disparate organs, variable segmentation tasks, and diverse distribution. Thus, we propose a novel FL approach for histopathology nuclei and tissue segmentation, FedSODA, via synthetic-driven cross-assessment operation (SO) and dynamic stratified-layer aggregation (DA). Our SO constructs a cross-assessment strategy to connect clients and mitigate the representation bias under sample imbalance. Our DA utilizes layer-wise interaction and dynamic aggregation to diminish heterogeneity and enhance generalization. The effectiveness of our FedSODA has been evaluated on the most extensive histopathology image segmentation dataset from 7 independent datasets. The code is available at https://github.com/yuanzhang7/FedSODA.
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021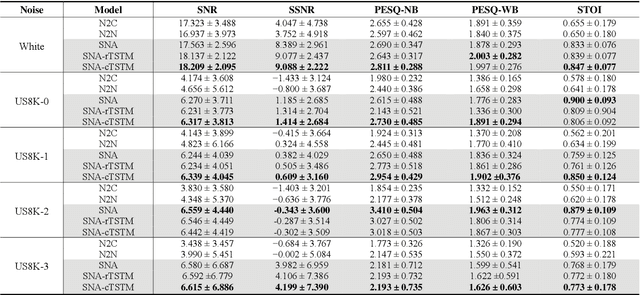
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
Generative networks as inverse problems with fractional wavelet scattering networks
Jul 28, 2020
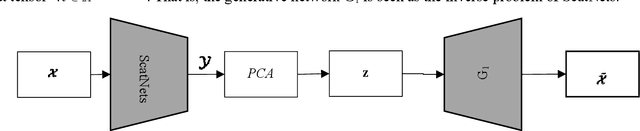
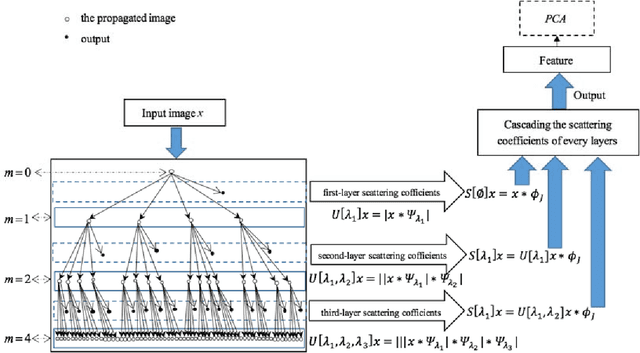
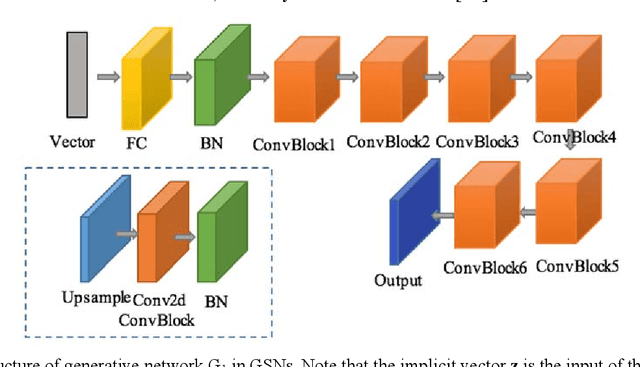
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.
SLNSpeech: solving extended speech separation problem by the help of sign language
Jul 21, 2020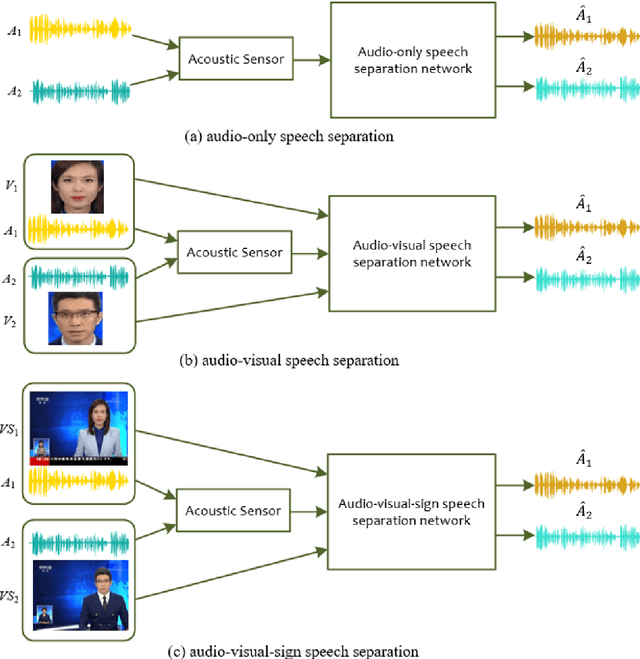


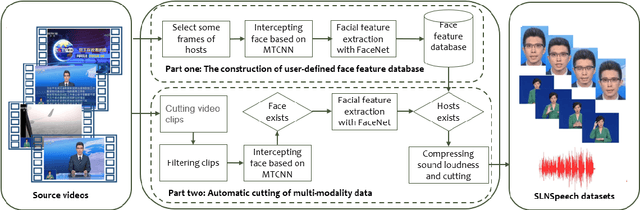
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/
Deep Octonion Networks
Mar 20, 2019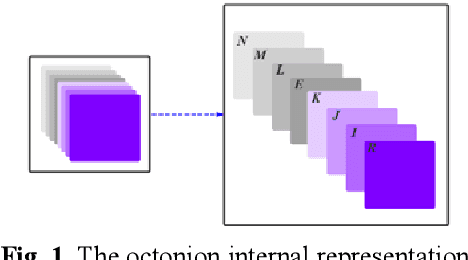
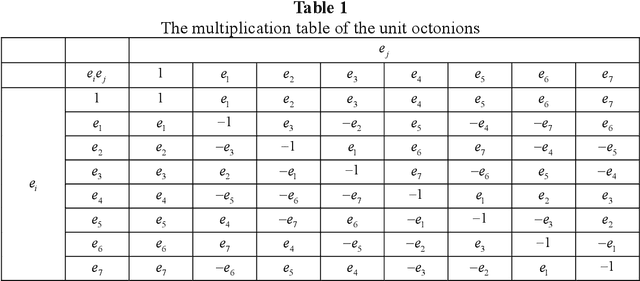
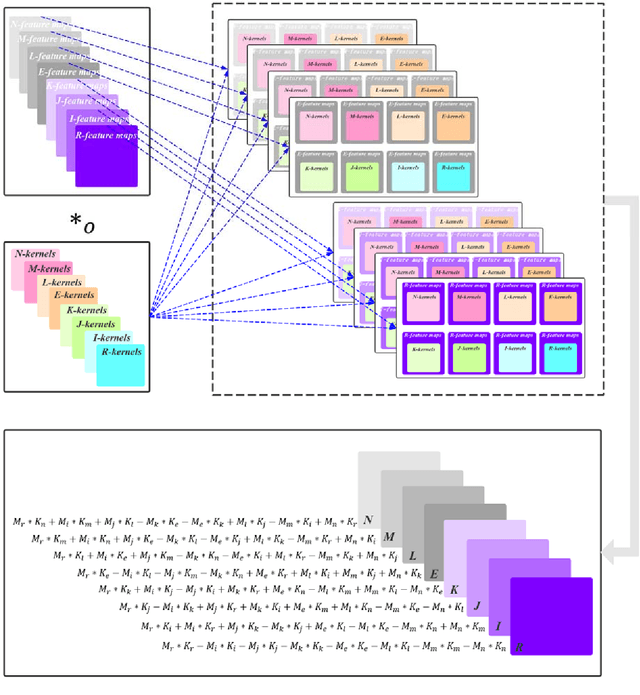
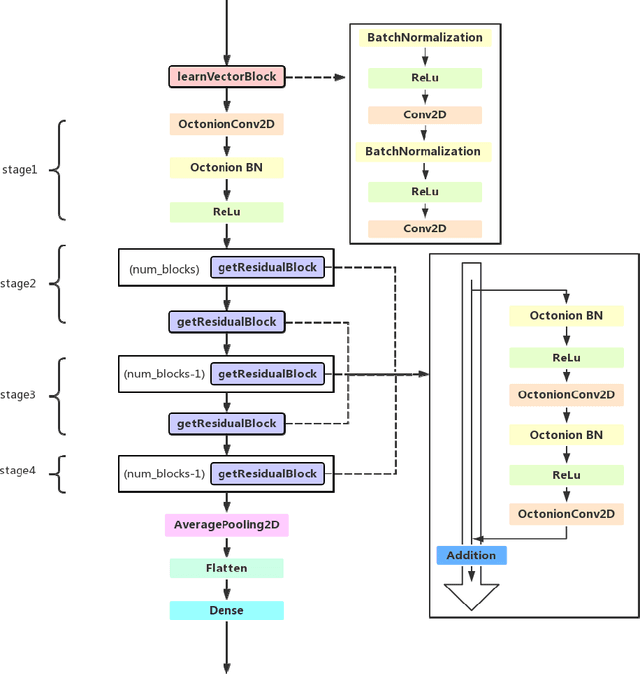
Deep learning is a research hot topic in the field of machine learning. Real-value neural networks (Real NNs), especially deep real networks (DRNs), have been widely used in many research fields. In recent years, the deep complex networks (DCNs) and the deep quaternion networks (DQNs) have attracted more and more attentions. The octonion algebra, which is an extension of complex algebra and quaternion algebra, can provide more efficient and compact expression. This paper constructs a general framework of deep octonion networks (DONs) and provides the main building blocks of DONs such as octonion convolution, octonion batch normalization and octonion weight initialization; DONs are then used in image classification tasks for CIFAR-10 and CIFAR-100 data sets. Compared with the DRNs, the DCNs, and the DQNs, the proposed DONs have better convergence and higher classification accuracy. The success of DONs is also explained by multi-task learning.
Compressing complex convolutional neural network based on an improved deep compression algorithm
Mar 06, 2019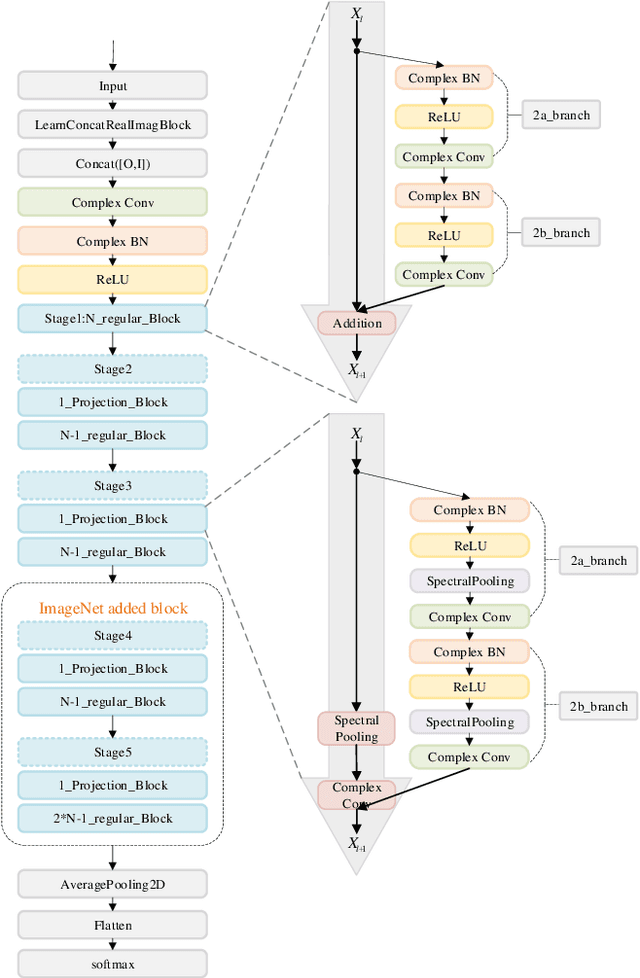
Although convolutional neural network (CNN) has made great progress, large redundant parameters restrict its deployment on embedded devices, especially mobile devices. The recent compression works are focused on real-value convolutional neural network (Real CNN), however, to our knowledge, there is no attempt for the compression of complex-value convolutional neural network (Complex CNN). Compared with the real-valued network, the complex-value neural network is easier to optimize, generalize, and has better learning potential. This paper extends the commonly used deep compression algorithm from real domain to complex domain and proposes an improved deep compression algorithm for the compression of Complex CNN. The proposed algorithm compresses the network about 8 times on CIFAR-10 dataset with less than 3% accuracy loss. On the ImageNet dataset, our method compresses the model about 16 times and the accuracy loss is about 2% without retraining.
Fractional spectral graph wavelets and their applications
Feb 27, 2019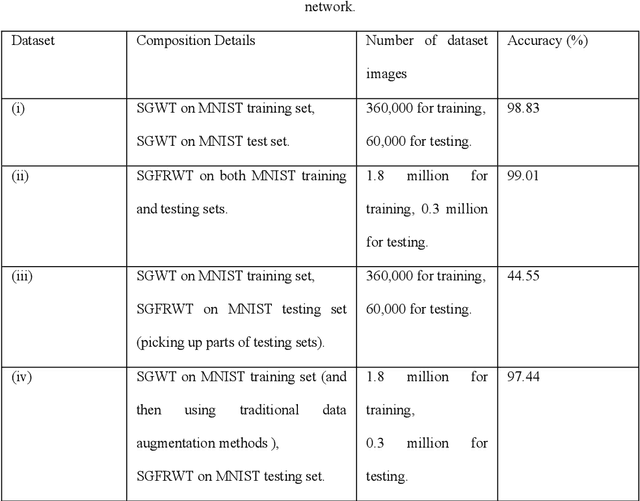
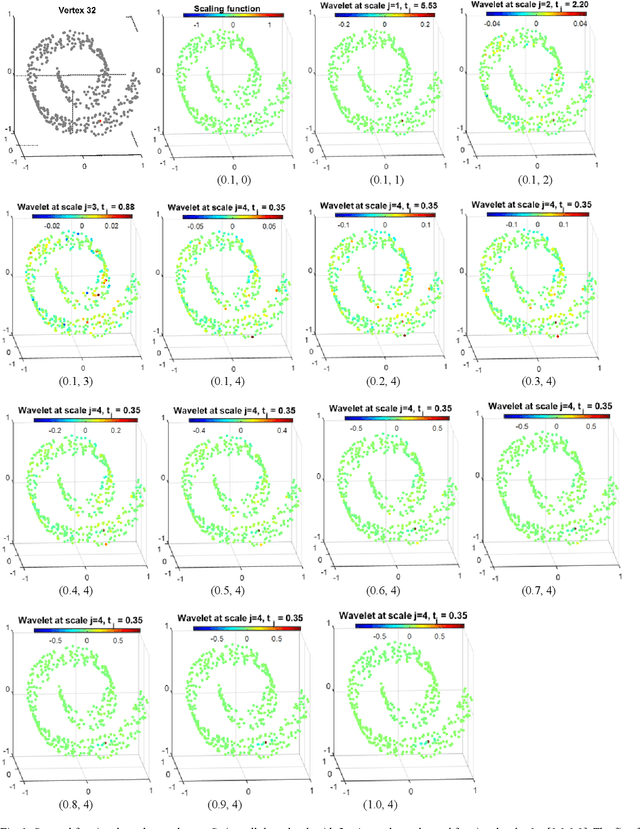


One of the key challenges in the area of signal processing on graphs is to design transforms and dictionaries methods to identify and exploit structure in signals on weighted graphs. In this paper, we first generalize graph Fourier transform (GFT) to graph fractional Fourier transform (GFRFT), which is then used to define a novel transform named spectral graph fractional wavelet transform (SGFRWT), which is a generalized and extended version of spectral graph wavelet transform (SGWT). A fast algorithm for SGFRWT is also derived and implemented based on Fourier series approximation. The potential applications of SGFRWT are also presented.