 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Network Embedding Model for Exposing COVID-19 Spread Trajectory Archetypes
Sep 21, 2022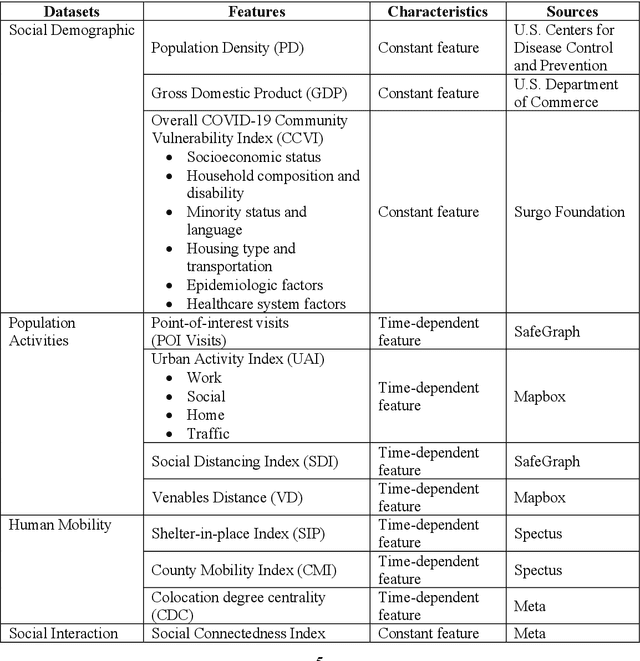

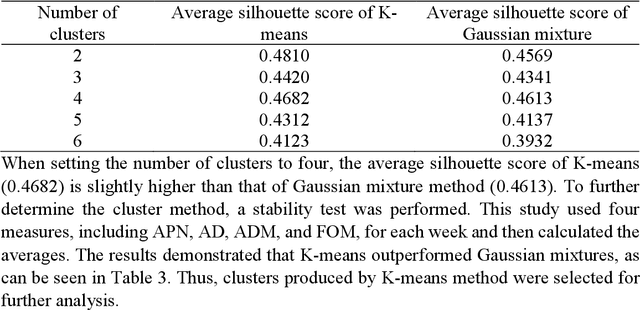

The spread of COVID-19 revealed that transmission risk patterns are not homogenous across different cities and communities, and various heterogeneous features can influence the spread trajectories. Hence, for predictive pandemic monitoring, it is essential to explore latent heterogeneous features in cities and communities that distinguish their specific pandemic spread trajectories. To this end, this study creates a network embedding model capturing cross-county visitation networks, as well as heterogeneous features to uncover clusters of counties in the United States based on their pandemic spread transmission trajectories. We collected and computed location intelligence features from 2,787 counties from March 3 to June 29, 2020 (initial wave). Second, we constructed a human visitation network, which incorporated county features as node attributes, and visits between counties as network edges. Our attributed network embeddings approach integrates both typological characteristics of the cross-county visitation network, as well as heterogeneous features. We conducted clustering analysis on the attributed network embeddings to reveal four archetypes of spread risk trajectories corresponding to four clusters of counties. Subsequently, we identified four features as important features underlying the distinctive transmission risk patterns among the archetypes. The attributed network embedding approach and the findings identify and explain the non-homogenous pandemic risk trajectories across counties for predictive pandemic monitoring. The study also contributes to data-driven and deep learning-based approaches for pandemic analytics to complement the standard epidemiological models for policy analysis in pandemics.
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021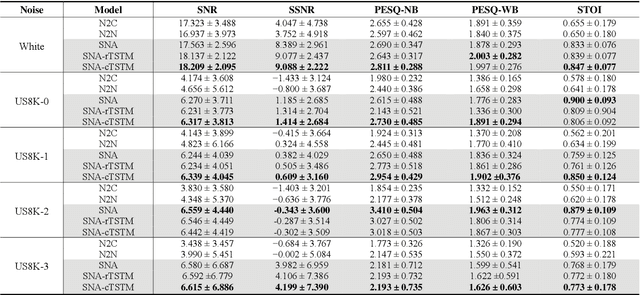
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
Spatio-Temporal Graph Convolutional Networks for Road Network Inundation Status Prediction during Urban Flooding
Apr 06, 2021



The objective of this study is to predict the near-future flooding status of road segments based on their own and adjacent road segments current status through the use of deep learning framework on fine-grained traffic data. Predictive flood monitoring for situational awareness of road network status plays a critical role to support crisis response activities such as evaluation of the loss of access to hospitals and shelters. Existing studies related to near-future prediction of road network flooding status at road segment level are missing. Using fine-grained traffic speed data related to road sections, this study designed and implemented three spatio-temporal graph convolutional network (STGCN) models to predict road network status during flood events at the road segment level in the context of the 2017 Hurricane Harvey in Harris County (Texas, USA). Model 1 consists of two spatio-temporal blocks considering the adjacency and distance between road segments, while Model 2 contains an additional elevation block to account for elevation difference between road segments. Model 3 includes three blocks for considering the adjacency and the product of distance and elevation difference between road segments. The analysis tested the STGCN models and evaluated their prediction performance. Our results indicated that Model 1 and Model 2 have reliable and accurate performance for predicting road network flooding status in near future (e.g., 2-4 hours) with model precision and recall values larger than 98% and 96%, respectively. With reliable road network status predictions in floods, the proposed model can benefit affected communities to avoid flooded roads and the emergency management agencies to implement evacuation and relief resource delivery plans.