 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Trial and Error Falls Behind in the Era of Experience
Jan 29, 2026While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
Mastering Massive Multi-Task Reinforcement Learning via Mixture-of-Expert Decision Transformer
May 30, 2025Despite recent advancements in offline multi-task reinforcement learning (MTRL) have harnessed the powerful capabilities of the Transformer architecture, most approaches focus on a limited number of tasks, with scaling to extremely massive tasks remaining a formidable challenge. In this paper, we first revisit the key impact of task numbers on current MTRL method, and further reveal that naively expanding the parameters proves insufficient to counteract the performance degradation as the number of tasks escalates. Building upon these insights, we propose M3DT, a novel mixture-of-experts (MoE) framework that tackles task scalability by further unlocking the model's parameter scalability. Specifically, we enhance both the architecture and the optimization of the agent, where we strengthen the Decision Transformer (DT) backbone with MoE to reduce task load on parameter subsets, and introduce a three-stage training mechanism to facilitate efficient training with optimal performance. Experimental results show that, by increasing the number of experts, M3DT not only consistently enhances its performance as model expansion on the fixed task numbers, but also exhibits remarkable task scalability, successfully extending to 160 tasks with superior performance.
QPO: Query-dependent Prompt Optimization via Multi-Loop Offline Reinforcement Learning
Aug 20, 2024Prompt engineering has demonstrated remarkable success in enhancing the performance of large language models (LLMs) across diverse tasks. However, most existing prompt optimization methods only focus on the task-level performance, overlooking the importance of query-preferred prompts, which leads to suboptimal performances. Additionally, these methods rely heavily on frequent interactions with LLMs to obtain feedback for guiding the optimization process, incurring substantial redundant interaction costs. In this paper, we introduce Query-dependent Prompt Optimization (QPO), which leverages multi-loop offline reinforcement learning to iteratively fine-tune a small pretrained language model to generate optimal prompts tailored to the input queries, thus significantly improving the prompting effect on the large target LLM. We derive insights from offline prompting demonstration data, which already exists in large quantities as a by-product of benchmarking diverse prompts on open-sourced tasks, thereby circumventing the expenses of online interactions. Furthermore, we continuously augment the offline dataset with the generated prompts in each loop, as the prompts from the fine-tuned model are supposed to outperform the source prompts in the original dataset. These iterative loops bootstrap the model towards generating optimal prompts. Experiments on various LLM scales and diverse NLP and math tasks demonstrate the efficacy and cost-efficiency of our method in both zero-shot and few-shot scenarios.
DEER: A Delay-Resilient Framework for Reinforcement Learning with Variable Delays
Jun 05, 2024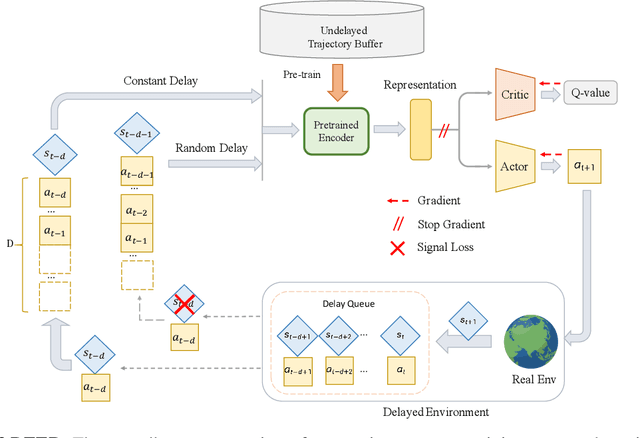
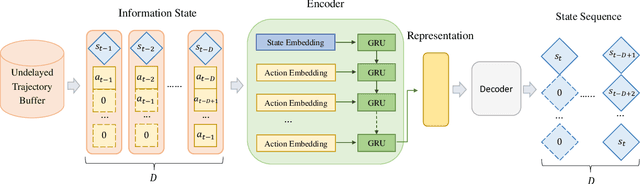
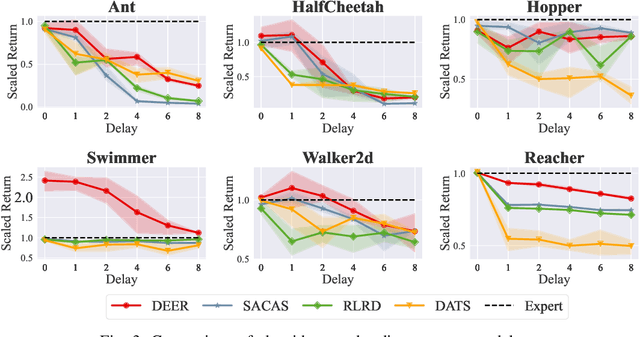
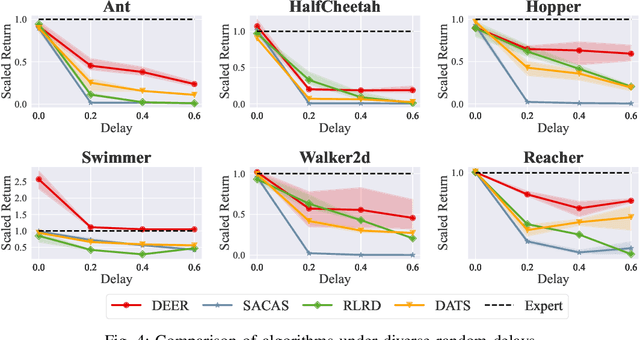
Classic reinforcement learning (RL) frequently confronts challenges in tasks involving delays, which cause a mismatch between received observations and subsequent actions, thereby deviating from the Markov assumption. Existing methods usually tackle this issue with end-to-end solutions using state augmentation. However, these black-box approaches often involve incomprehensible processes and redundant information in the information states, causing instability and potentially undermining the overall performance. To alleviate the delay challenges in RL, we propose $\textbf{DEER (Delay-resilient Encoder-Enhanced RL)}$, a framework designed to effectively enhance the interpretability and address the random delay issues. DEER employs a pretrained encoder to map delayed states, along with their variable-length past action sequences resulting from different delays, into hidden states, which is trained on delay-free environment datasets. In a variety of delayed scenarios, the trained encoder can seamlessly integrate with standard RL algorithms without requiring additional modifications and enhance the delay-solving capability by simply adapting the input dimension of the original algorithms. We evaluate DEER through extensive experiments on Gym and Mujoco environments. The results confirm that DEER is superior to state-of-the-art RL algorithms in both constant and random delay settings.
TPTU-v2: Boosting Task Planning and Tool Usage of Large Language Model-based Agents in Real-world Systems
Nov 19, 2023Large Language Models (LLMs) have demonstrated proficiency in addressing tasks that necessitate a combination of task planning and the usage of external tools that require a blend of task planning and the utilization of external tools, such as APIs. However, real-world complex systems present three prevalent challenges concerning task planning and tool usage: (1) The real system usually has a vast array of APIs, so it is impossible to feed the descriptions of all APIs to the prompt of LLMs as the token length is limited; (2) the real system is designed for handling complex tasks, and the base LLMs can hardly plan a correct sub-task order and API-calling order for such tasks; (3) Similar semantics and functionalities among APIs in real systems create challenges for both LLMs and even humans in distinguishing between them. In response, this paper introduces a comprehensive framework aimed at enhancing the Task Planning and Tool Usage (TPTU) abilities of LLM-based agents operating within real-world systems. Our framework comprises three key components designed to address these challenges: (1) the API Retriever selects the most pertinent APIs for the user task among the extensive array available; (2) LLM Finetuner tunes a base LLM so that the finetuned LLM can be more capable for task planning and API calling; (3) the Demo Selector adaptively retrieves different demonstrations related to hard-to-distinguish APIs, which is further used for in-context learning to boost the final performance. We validate our methods using a real-world commercial system as well as an open-sourced academic dataset, and the outcomes clearly showcase the efficacy of each individual component as well as the integrated framework.
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021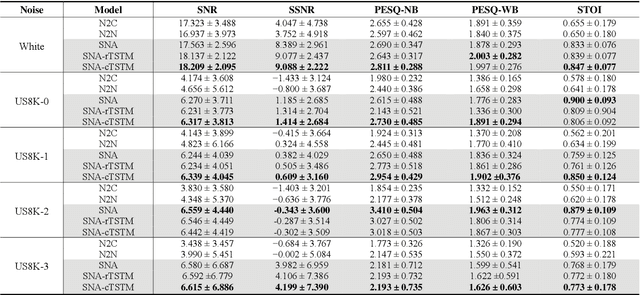
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.