 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVecHeart: Holistic Four-Chamber Cardiac Anatomy Modeling via Hybrid VecSets
Apr 21, 2026Accurate cardiac anatomy modeling requires the model to be able to handle intricate interrelations among structures. In this paper, we propose VecHeart, a unified framework for holistic reconstruction and generation of four-chamber cardiac structures. To overcome the limitations of current feed-forward implicit methods, specifically their restriction to single-object modeling and their neglect of inter-part correlations, we introduce Hybrid Part Transformer, which leverages part-specific learnable queries and interleaved attention to capture complex inter-chamber dependencies. Furthermore, we propose Anatomical Completion Masking and Modality Alignment strategies, enabling the model to infer complete four-chamber structures from partial, sparse, or noisy observations, even when certain anatomical parts are entirely missing. VecHeart also seamlessly extends to 3D+t dynamic mesh sequence generation, demonstrating exceptional versatility. Experiments show that our method achieves state-of-the-art performance, maintaining high-fidelity reconstruction across diverse challenging scenarios. Code will be released.
Attention Sinks Induce Gradient Sinks
Mar 18, 2026Attention sinks and massive activations are recurring and closely related phenomena in Transformer models. Existing studies have largely focused on the forward pass, making it unclear whether their connection is direct or mediated by a training-time mechanism. We study this question from the perspective of backpropagation. Empirically and theoretically, we show that under causal mask, attention sinks can induce pronounced gradient concentration, which we term gradient sinks. Furthermore, in pre-norm architectures with RMSNorm, massive activations can be understood as an adaptive response to this localized gradient pressure during training. To test this hypothesis, we introduce V-scale, a modification that adjusts value-path backpropagated gradients. In pretrained V-scale models, attention sinks are preserved whereas massive activations are suppressed. These results support the interpretation that gradient sink is a key training-time mediator linking attention sinks and massive activations.
Distance-aware Self-adaptive Graph Convolution for Fine-grained Hierarchical Recommendation
May 14, 2025Graph Convolutional Networks (GCNs) are widely used to improve recommendation accuracy and performance by effectively learning the representations of user and item nodes. However, two major challenges remain: (1) the lack of further optimization in the graph representation structure and (2) insufficient attention given to the varying contributions of different convolutional layers.This paper proposes SAGCN, a distance-based adaptive hierarchical aggregation method that refines the aggregation process through differentiated representation metrics. SAGCN introduces a detailed approach to multilayer information aggregation and representation space optimization, enabling the model to learn hierarchical embedding weights based on the distance between hierarchical representations. This innovation allows for more precise cross-layer information aggregation, improves the model's ability to capture hierarchical embeddings, and optimizes the representation space structure. Additionally, the objective loss function is refined to better align with recommendation tasks.Extensive experiments conducted on four real-world datasets demonstrate significant improvements, including over a 5% increase on Yelp and a 5.58% increase in Recall@10 on the ML_1M dataset.
Probing In-Context Learning: Impact of Task Complexity and Model Architecture on Generalization and Efficiency
May 10, 2025We investigate in-context learning (ICL) through a meticulous experimental framework that systematically varies task complexity and model architecture. Extending beyond the linear regression baseline, we introduce Gaussian kernel regression and nonlinear dynamical system tasks, which emphasize temporal and recursive reasoning. We evaluate four distinct models: a GPT2-style Transformer, a Transformer with FlashAttention mechanism, a convolutional Hyena-based model, and the Mamba state-space model. Each model is trained from scratch on synthetic datasets and assessed for generalization during testing. Our findings highlight that model architecture significantly shapes ICL performance. The standard Transformer demonstrates robust performance across diverse tasks, while Mamba excels in temporally structured dynamics. Hyena effectively captures long-range dependencies but shows higher variance early in training, and FlashAttention offers computational efficiency but is more sensitive in low-data regimes. Further analysis uncovers locality-induced shortcuts in Gaussian kernel tasks, enhanced nonlinear separability through input range scaling, and the critical role of curriculum learning in mastering high-dimensional tasks.
Multilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
LUNAR: LLM Unlearning via Neural Activation Redirection
Feb 11, 2025Large Language Models (LLMs) benefit from training on ever larger amounts of textual data, but as a result, they increasingly incur the risk of leaking private information. The ability to selectively remove knowledge from LLMs is, therefore, a highly desirable capability. In this paper, we propose LUNAR, a novel unlearning methodology grounded in the Linear Representation Hypothesis. LUNAR operates by redirecting the representations of unlearned data to regions that trigger the model's inherent ability to express its inability to answer. LUNAR achieves state-of-the-art unlearning performance while significantly enhancing the controllability of the unlearned model during inference. Specifically, LUNAR achieves between 2.9x to 11.7x improvements on combined "unlearning efficacy" and "model utility" score ("Deviation Score") on the PISTOL dataset across various base models. We also demonstrate, through quantitative analysis and qualitative examples, LUNAR's superior controllability in generating coherent and contextually aware responses, mitigating undesired side effects of existing methods. Moreover, we demonstrate that LUNAR is robust against white-box adversarial attacks and versatile in handling real-world scenarios, such as processing sequential unlearning requests.
MedTet: An Online Motion Model for 4D Heart Reconstruction
Dec 03, 2024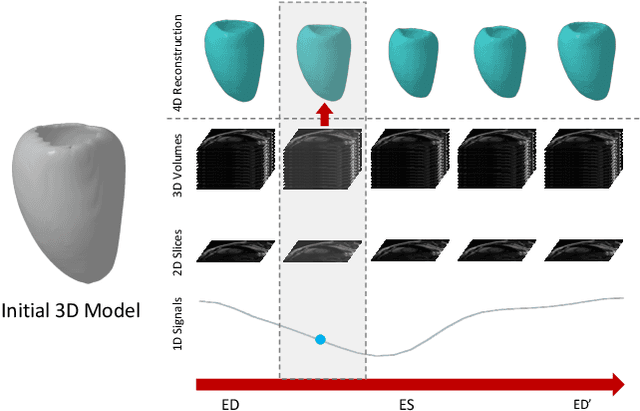
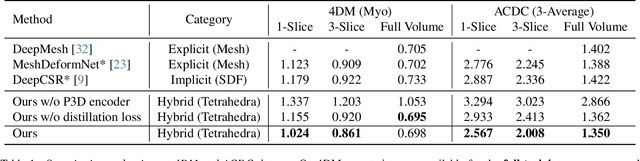
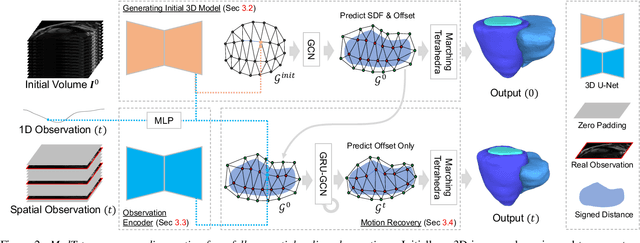
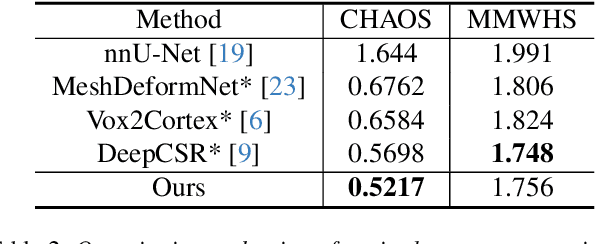
We present a novel approach to reconstruction of 3D cardiac motion from sparse intraoperative data. While existing methods can accurately reconstruct 3D organ geometries from full 3D volumetric imaging, they cannot be used during surgical interventions where usually limited observed data, such as a few 2D frames or 1D signals, is available in real-time. We propose a versatile framework for reconstructing 3D motion from such partial data. It discretizes the 3D space into a deformable tetrahedral grid with signed distance values, providing implicit unlimited resolution while maintaining explicit control over motion dynamics. Given an initial 3D model reconstructed from pre-operative full volumetric data, our system, equipped with an universal observation encoder, can reconstruct coherent 3D cardiac motion from full 3D volumes, a few 2D MRI slices or even 1D signals. Extensive experiments on cardiac intervention scenarios demonstrate our ability to generate plausible and anatomically consistent 3D motion reconstructions from various sparse real-time observations, highlighting its potential for multimodal cardiac imaging. Our code and model will be made available at https://github.com/Scalsol/MedTet.
Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language
Oct 31, 2024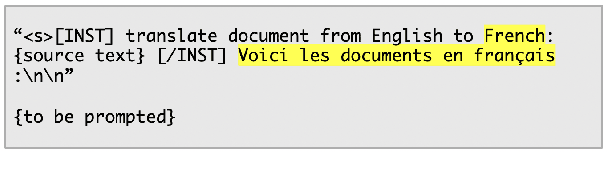
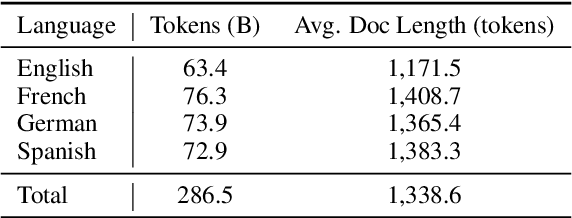
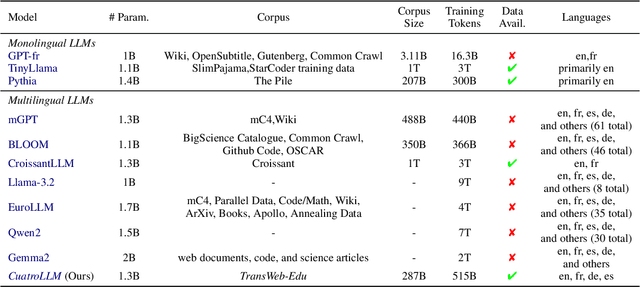
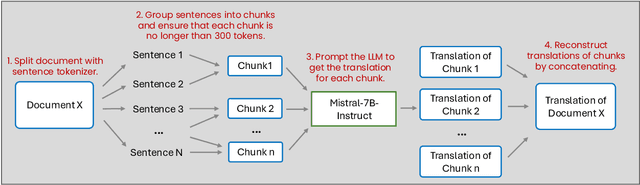
English, as a very high-resource language, enables the pretraining of high-quality large language models (LLMs). The same cannot be said for most other languages, as leading LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated text from a single high-quality source language can contribute significantly to the pretraining of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into French, German, and Spanish, resulting in a final 300B-token dataset, which we call TransWeb-Edu, and pretrain a 1.3B-parameter model, CuatroLLM, from scratch on this dataset. Across five non-English reasoning tasks, we show that CuatroLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2 and Gemma2, despite using an order of magnitude less data, such as about 6% of the tokens used for Llama3.2's training. We further demonstrate that with additional domain-specific pretraining, amounting to less than 1% of TransWeb-Edu, CuatroLLM surpasses the state of the art in multilingual reasoning. To promote reproducibility, we release our corpus, models, and training pipeline under open licenses at hf.co/britllm/CuatroLLM.
Jet Expansions of Residual Computation
Oct 08, 2024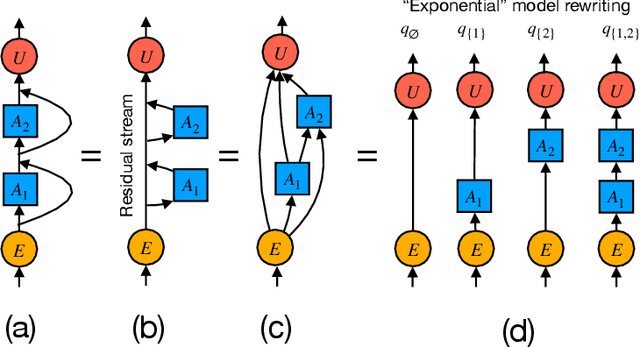

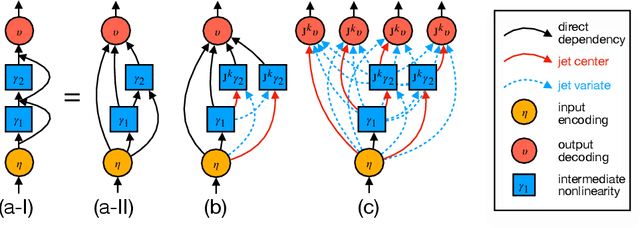
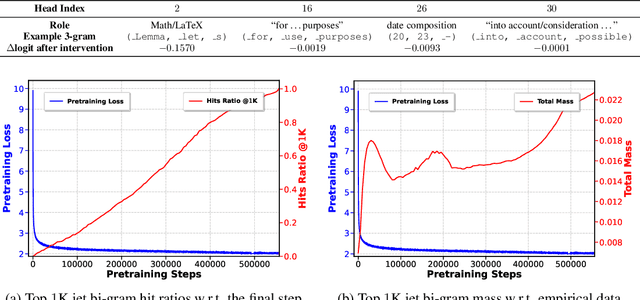
We introduce a framework for expanding residual computational graphs using jets, operators that generalize truncated Taylor series. Our method provides a systematic approach to disentangle contributions of different computational paths to model predictions. In contrast to existing techniques such as distillation, probing, or early decoding, our expansions rely solely on the model itself and requires no data, training, or sampling from the model. We demonstrate how our framework grounds and subsumes logit lens, reveals a (super-)exponential path structure in the recursive residual depth and opens up several applications. These include sketching a transformer large language model with $n$-gram statistics extracted from its computations, and indexing the models' levels of toxicity knowledge. Our approach enables data-free analysis of residual computation for model interpretability, development, and evaluation.
AsEP: Benchmarking Deep Learning Methods for Antibody-specific Epitope Prediction
Jul 25, 2024Epitope identification is vital for antibody design yet challenging due to the inherent variability in antibodies. While many deep learning methods have been developed for general protein binding site prediction tasks, whether they work for epitope prediction remains an understudied research question. The challenge is also heightened by the lack of a consistent evaluation pipeline with sufficient dataset size and epitope diversity. We introduce a filtered antibody-antigen complex structure dataset, AsEP (Antibody-specific Epitope Prediction). AsEP is the largest of its kind and provides clustered epitope groups, allowing the community to develop and test novel epitope prediction methods. AsEP comes with an easy-to-use interface in Python and pre-built graph representations of each antibody-antigen complex while also supporting customizable embedding methods. Based on this new dataset, we benchmarked various representative general protein-binding site prediction methods and find that their performances are not satisfactory as expected for epitope prediction. We thus propose a new method, WALLE, that leverages both protein language models and graph neural networks. WALLE demonstrate about 5X performance gain over existing methods. Our empirical findings evidence that epitope prediction benefits from combining sequential embeddings provided by language models and geometrical information from graph representations, providing a guideline for future method design. In addition, we reformulate the task as bipartite link prediction, allowing easy model performance attribution and interpretability. We open-source our data and code at https://github.com/biochunan/AsEP-dataset.