 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsEP: Benchmarking Deep Learning Methods for Antibody-specific Epitope Prediction
Jul 25, 2024Epitope identification is vital for antibody design yet challenging due to the inherent variability in antibodies. While many deep learning methods have been developed for general protein binding site prediction tasks, whether they work for epitope prediction remains an understudied research question. The challenge is also heightened by the lack of a consistent evaluation pipeline with sufficient dataset size and epitope diversity. We introduce a filtered antibody-antigen complex structure dataset, AsEP (Antibody-specific Epitope Prediction). AsEP is the largest of its kind and provides clustered epitope groups, allowing the community to develop and test novel epitope prediction methods. AsEP comes with an easy-to-use interface in Python and pre-built graph representations of each antibody-antigen complex while also supporting customizable embedding methods. Based on this new dataset, we benchmarked various representative general protein-binding site prediction methods and find that their performances are not satisfactory as expected for epitope prediction. We thus propose a new method, WALLE, that leverages both protein language models and graph neural networks. WALLE demonstrate about 5X performance gain over existing methods. Our empirical findings evidence that epitope prediction benefits from combining sequential embeddings provided by language models and geometrical information from graph representations, providing a guideline for future method design. In addition, we reformulate the task as bipartite link prediction, allowing easy model performance attribution and interpretability. We open-source our data and code at https://github.com/biochunan/AsEP-dataset.
Are words easier to learn from infant- than adult-directed speech? A quantitative corpus-based investigation
Dec 23, 2017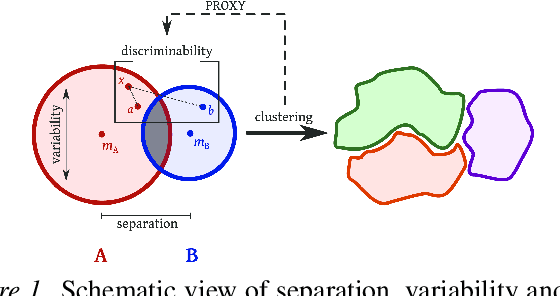
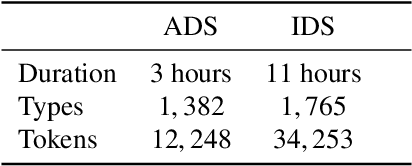
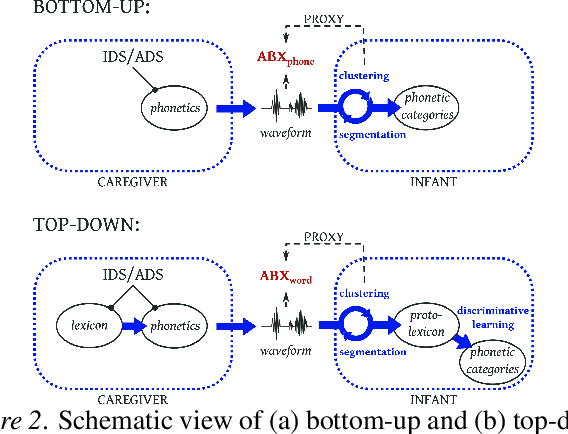
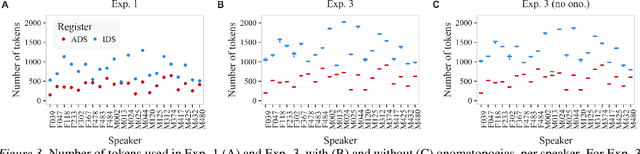
We investigate whether infant-directed speech (IDS) could facilitate word form learning when compared to adult-directed speech (ADS). To study this, we examine the distribution of word forms at two levels, acoustic and phonological, using a large database of spontaneous speech in Japanese. At the acoustic level we show that, as has been documented before for phonemes, the realizations of words are more variable and less discriminable in IDS than in ADS. At the phonological level, we find an effect in the opposite direction: the IDS lexicon contains more distinctive words (such as onomatopoeias) than the ADS counterpart. Combining the acoustic and phonological metrics together in a global discriminability score reveals that the bigger separation of lexical categories in the phonological space does not compensate for the opposite effect observed at the acoustic level. As a result, IDS word forms are still globally less discriminable than ADS word forms, even though the effect is numerically small. We discuss the implication of these findings for the view that the functional role of IDS is to improve language learnability.