 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyHuBERT: Multilingual Self-Supervised Learning for Segmenting Speakers in Child-Centered Long-Form Recordings
Sep 18, 2025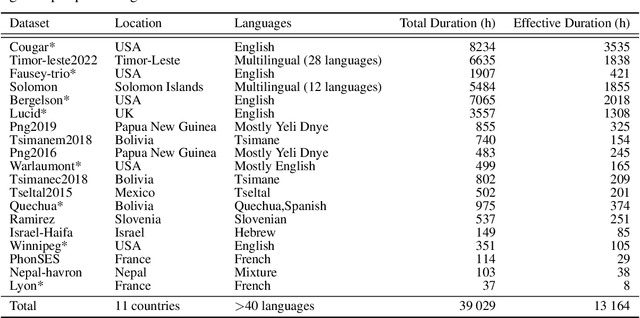
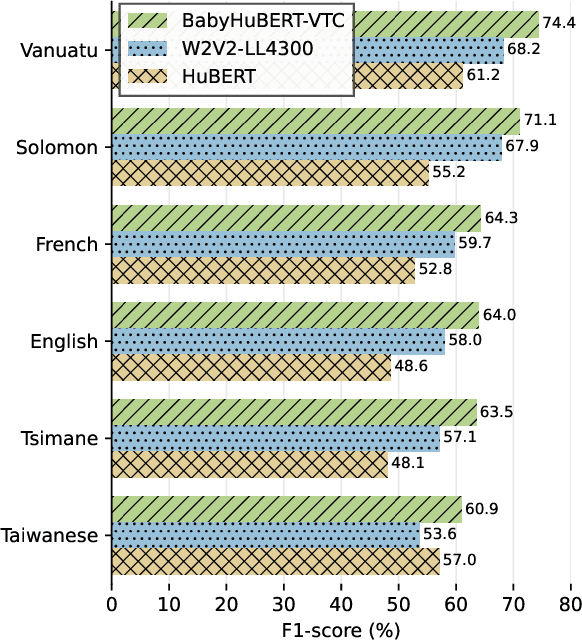
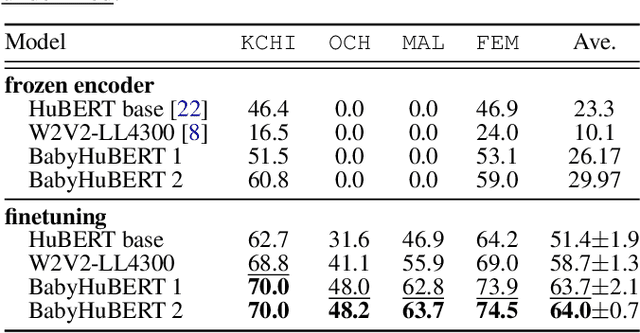
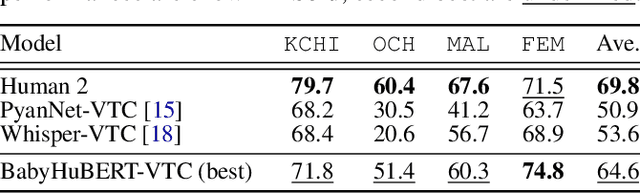
Child-centered long-form recordings are essential for studying early language development, but existing speech models trained on clean adult data perform poorly due to acoustic and linguistic differences. We introduce BabyHuBERT, the first self-supervised speech representation model trained on 13,000 hours of multilingual child-centered long-form recordings spanning over 40 languages. We evaluate BabyHuBERT on speaker segmentation, identifying when target children speak versus female adults, male adults, or other children -- a fundamental preprocessing step for analyzing naturalistic language experiences. BabyHuBERT achieves F1-scores from 52.1% to 74.4% across six diverse datasets, consistently outperforming W2V2-LL4300 (trained on English long-forms) and standard HuBERT (trained on clean adult speech). Notable improvements include 13.2 absolute F1 points over HuBERT on Vanuatu and 15.9 points on Solomon Islands corpora, demonstrating effectiveness on underrepresented languages. By sharing code and models, BabyHuBERT serves as a foundation model for child speech research, enabling fine-tuning on diverse downstream tasks.
Employing self-supervised learning models for cross-linguistic child speech maturity classification
Jun 10, 2025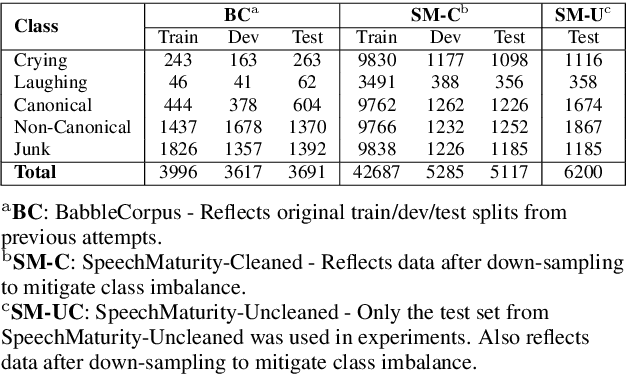
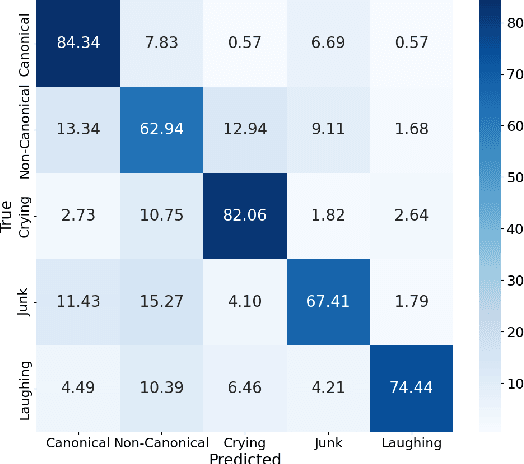
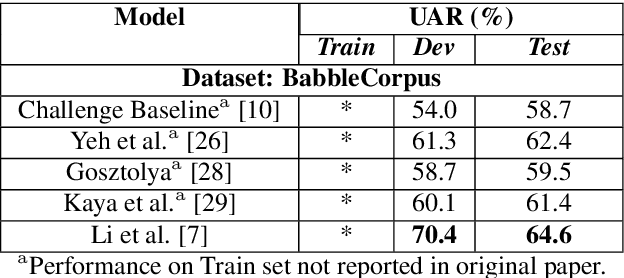
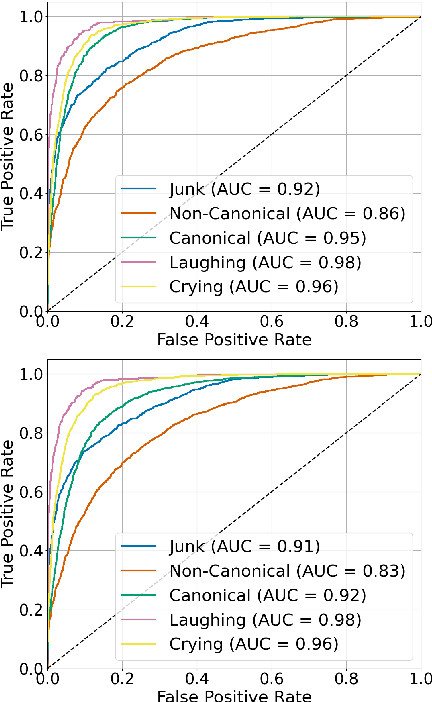
Speech technology systems struggle with many downstream tasks for child speech due to small training corpora and the difficulties that child speech pose. We apply a novel dataset, SpeechMaturity, to state-of-the-art transformer models to address a fundamental classification task: identifying child vocalizations. Unlike previous corpora, our dataset captures maximally ecologically-valid child vocalizations across an unprecedented sample, comprising children acquiring 25+ languages in the U.S., Bolivia, Vanuatu, Papua New Guinea, Solomon Islands, and France. The dataset contains 242,004 labeled vocalizations, magnitudes larger than previous work. Models were trained to distinguish between cry, laughter, mature (consonant+vowel), and immature speech (just consonant or vowel). Models trained on the dataset outperform state-of-the-art models trained on previous datasets, achieved classification accuracy comparable to humans, and were robust across rural and urban settings.
BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023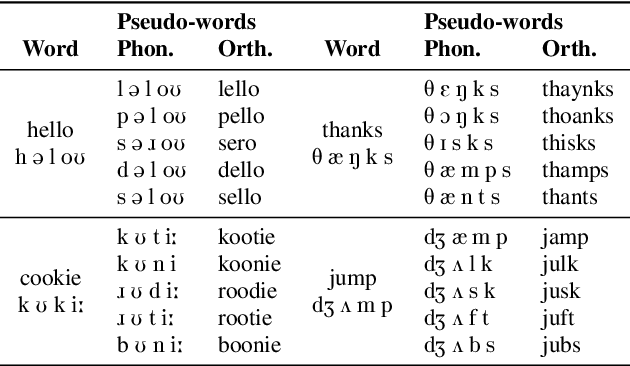
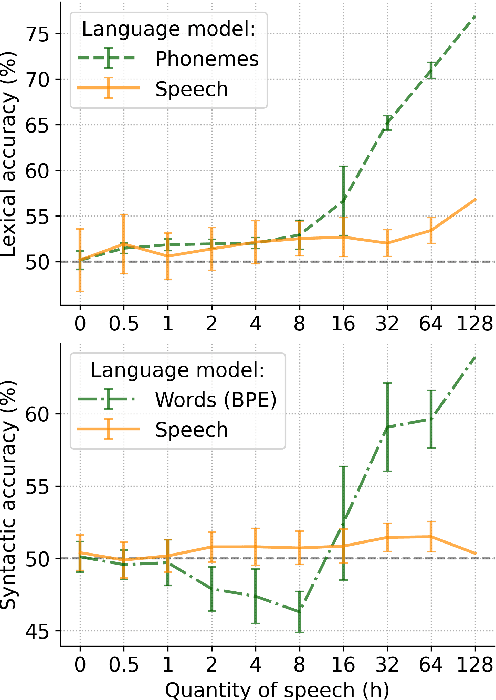
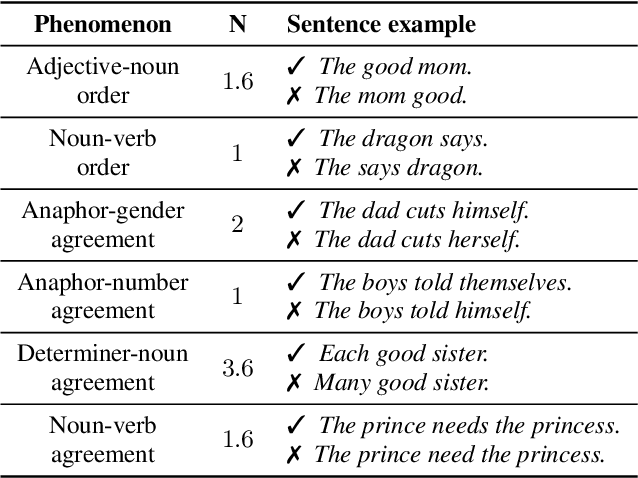
Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
Analysing the Impact of Audio Quality on the Use of Naturalistic Long-Form Recordings for Infant-Directed Speech Research
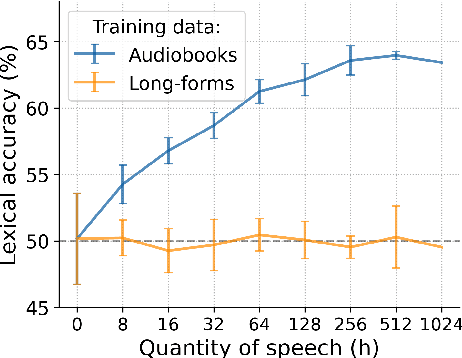
May 03, 2023Modelling of early language acquisition aims to understand how infants bootstrap their language skills. The modelling encompasses properties of the input data used for training the models, the cognitive hypotheses and their algorithmic implementations being tested, and the evaluation methodologies to compare models to human data. Recent developments have enabled the use of more naturalistic training data for computational models. This also motivates development of more naturalistic tests of model behaviour. A crucial step towards such an aim is to develop representative speech datasets consisting of speech heard by infants in their natural environments. However, a major drawback of such recordings is that they are typically noisy, and it is currently unclear how the sound quality could affect analyses and modelling experiments conducted on such data. In this paper, we explore this aspect for the case of infant-directed speech (IDS) and adult-directed speech (ADS) analysis. First, we manually and automatically annotated audio quality of utterances extracted from two corpora of child-centred long-form recordings (in English and French). We then compared acoustic features of IDS and ADS in an in-lab dataset and across different audio quality subsets of naturalistic data. Finally, we assessed how the audio quality and recording environment may change the conclusions of a modelling analysis using a recent self-supervised learning model. Our results show that the use of modest and high audio quality naturalistic speech data result in largely similar conclusions on IDS and ADS in terms of acoustic analyses and modelling experiments. We also found that an automatic sound quality assessment tool can be used to screen out useful parts of long-form recordings for a closer analysis with comparable results to that of manual quality annotation.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
ZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021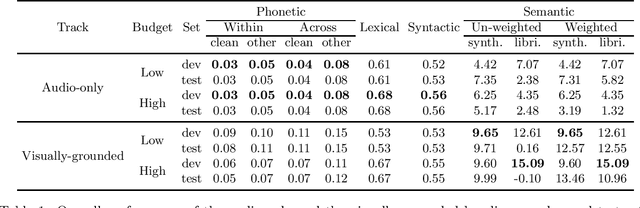
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.
Seshat: A tool for managing and verifying annotation campaigns of audio data
Mar 03, 2020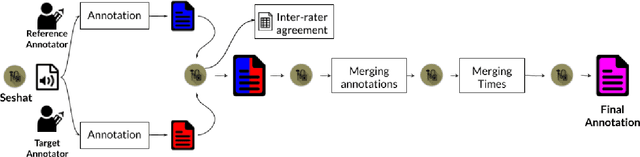
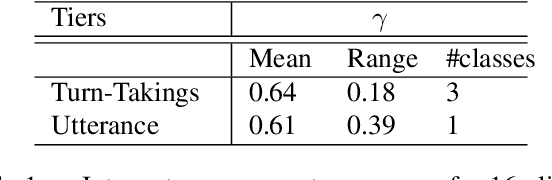


We introduce Seshat, a new, simple and open-source software to efficiently manage annotations of speech corpora. The Seshat software allows users to easily customise and manage annotations of large audio corpora while ensuring compliance with the formatting and naming conventions of the annotated output files. In addition, it includes procedures for checking the content of annotations following specific rules are implemented in personalised parsers. Finally, we propose a double-annotation mode, for which Seshat computes automatically an associated inter-annotator agreement with the $\gamma$ measure taking into account the categorisation and segmentation discrepancies.
The Second DIHARD Diarization Challenge: Dataset, task, and baselines
Jun 18, 2019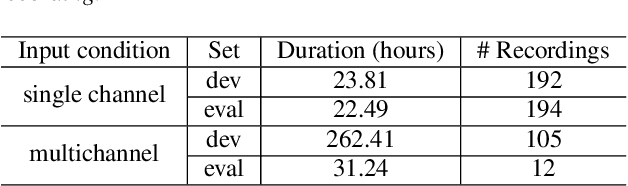
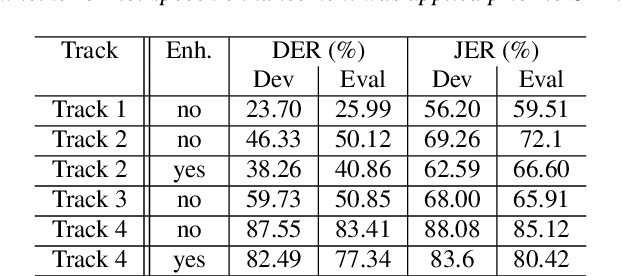
This paper introduces the second DIHARD challenge, the second in a series of speaker diarization challenges intended to improve the robustness of diarization systems to variation in recording equipment, noise conditions, and conversational domain. The challenge comprises four tracks evaluating diarization performance under two input conditions (single channel vs. multi-channel) and two segmentation conditions (diarization from a reference speech segmentation vs. diarization from scratch). In order to prevent participants from overtuning to a particular combination of recording conditions and conversational domain, recordings are drawn from a variety of sources ranging from read audiobooks to meeting speech, to child language acquisition recordings, to dinner parties, to web video. We describe the task and metrics, challenge design, datasets, and baseline systems for speech enhancement, speech activity detection, and diarization.
Are words easier to learn from infant- than adult-directed speech? A quantitative corpus-based investigation
Dec 23, 2017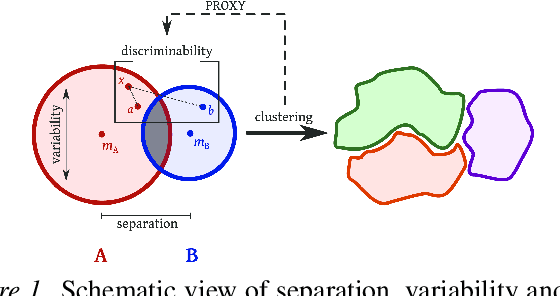
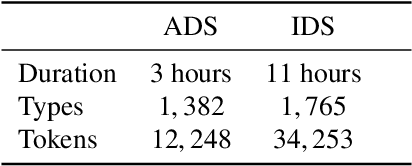
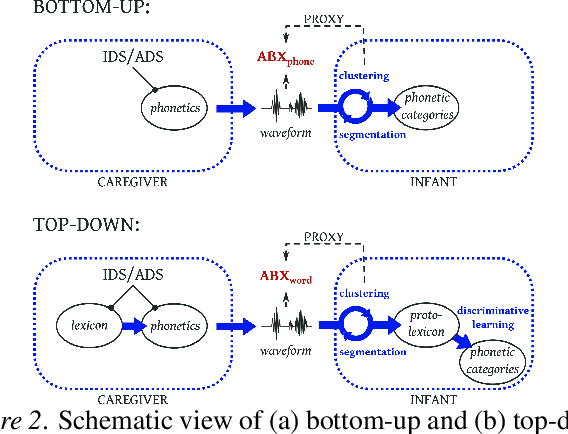
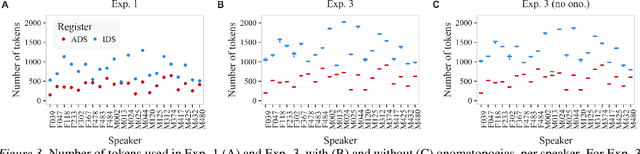
We investigate whether infant-directed speech (IDS) could facilitate word form learning when compared to adult-directed speech (ADS). To study this, we examine the distribution of word forms at two levels, acoustic and phonological, using a large database of spontaneous speech in Japanese. At the acoustic level we show that, as has been documented before for phonemes, the realizations of words are more variable and less discriminable in IDS than in ADS. At the phonological level, we find an effect in the opposite direction: the IDS lexicon contains more distinctive words (such as onomatopoeias) than the ADS counterpart. Combining the acoustic and phonological metrics together in a global discriminability score reveals that the bigger separation of lexical categories in the phonological space does not compensate for the opposite effect observed at the acoustic level. As a result, IDS word forms are still globally less discriminable than ADS word forms, even though the effect is numerically small. We discuss the implication of these findings for the view that the functional role of IDS is to improve language learnability.