 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabAR: from phoneme recognition to developmental measures of young children's speech production
Mar 05, 2026Studying early speech development at scale requires automatic tools, yet automatic phoneme recognition, especially for young children, remains largely unsolved. Building on decades of data collection, we curate TinyVox, a corpus of more than half a million phonetically transcribed child vocalizations in English, French, Portuguese, German, and Spanish. We use TinyVox to train BabAR, a cross-linguistic phoneme recognition system for child speech. We find that pretraining the system on multilingual child-centered daylong recordings substantially outperforms alternatives, and that providing 20 seconds of surrounding audio context during fine-tuning further improves performance. Error analyses show that substitutions predominantly fall within the same broad phonetic categories, suggesting suitability for coarse-grained developmental analyses. We validate BabAR by showing that its automatic measures of speech maturity align with developmental estimates from the literature.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
How Adults Understand What Young Children Say
Jun 15, 2022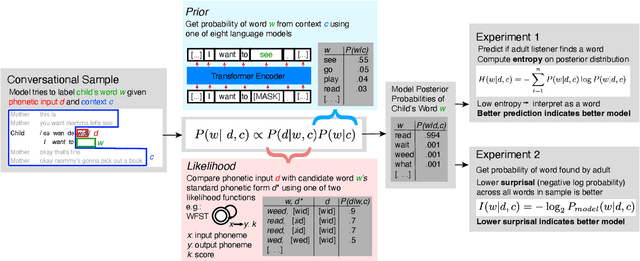
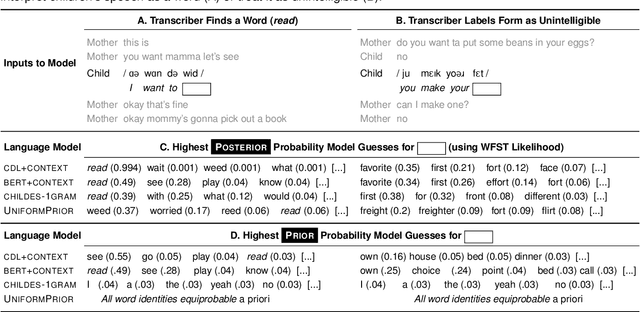
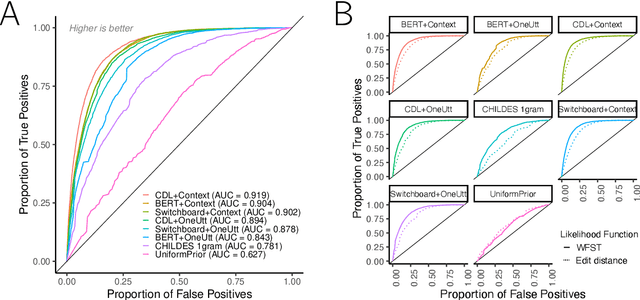
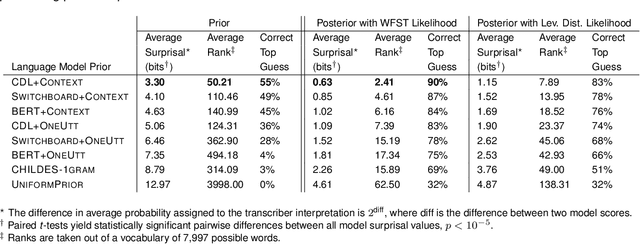
Children's early speech often bears little resemblance to adult speech in form or content, and yet caregivers often find meaning in young children's utterances. Precisely how caregivers are able to do this remains poorly understood. We propose that successful early communication (an essential building block of language development) relies not just on children's growing linguistic knowledge, but also on adults' sophisticated inferences. These inferences, we further propose, are optimized for fine-grained details of how children speak. We evaluate these ideas using a set of candidate computational models of spoken word recognition based on deep learning and Bayesian inference, which instantiate competing hypotheses regarding the information sources used by adults to understand children. We find that the best-performing models (evaluated on datasets of adult interpretations of child speech) are those that have strong prior expectations about what children are likely to want to communicate, rather than the actual phonetic contents of what children say. We further find that adults' behavior is best characterized as well-tuned to specific children: the more closely a word recognition model is tuned to the particulars of an individual child's actual linguistic behavior, the better it predicts adults' inferences about what the child has said. These results offer a comprehensive investigation into the role of caregivers as child-directed listeners, with broader consequences for theories of language acquisition.
Child-directed Listening: How Caregiver Inference Enables Children's Early Verbal Communication
Feb 09, 2021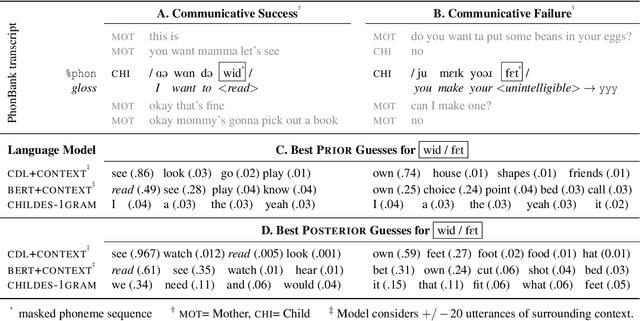
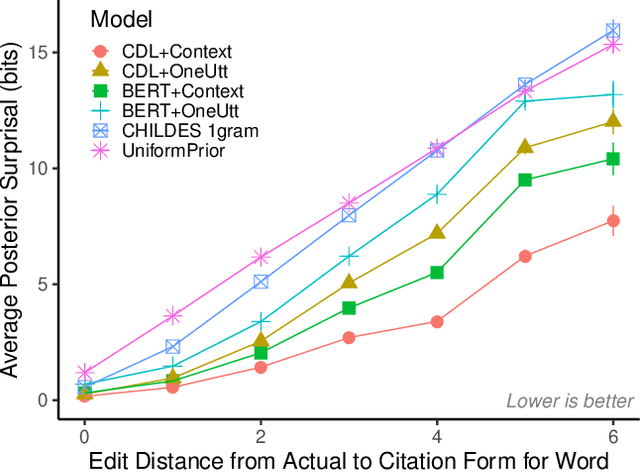
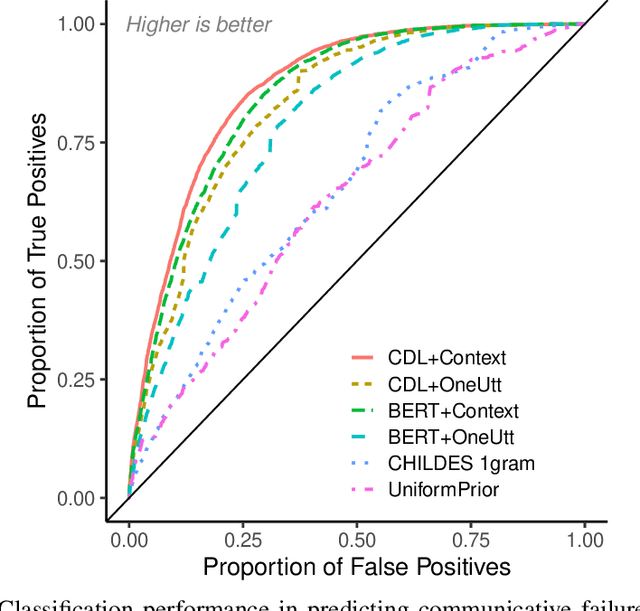
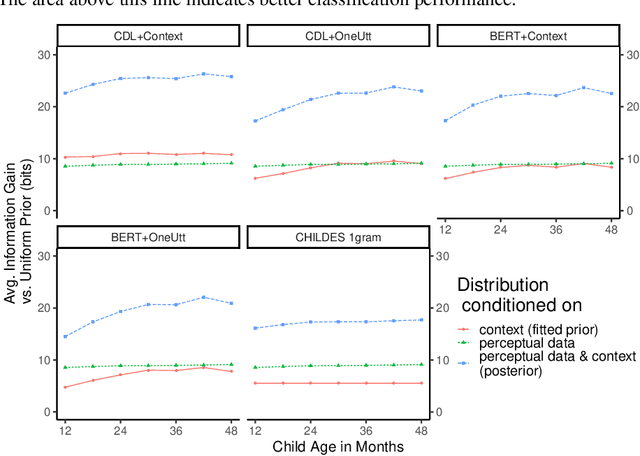
How do adults understand children's speech? Children's productions over the course of language development often bear little resemblance to typical adult pronunciations, yet caregivers nonetheless reliably recover meaning from them. Here, we employ a suite of Bayesian models of spoken word recognition to understand how adults overcome the noisiness of child language, showing that communicative success between children and adults relies heavily on adult inferential processes. By evaluating competing models on phonetically-annotated corpora, we show that adults' recovered meanings are best predicted by prior expectations fitted specifically to the child language environment, rather than to typical adult-adult language. After quantifying the contribution of this "child-directed listening" over developmental time, we discuss the consequences for theories of language acquisition, as well as the implications for commonly-used methods for assessing children's linguistic proficiency.
Preserved Structure Across Vector Space Representations
May 14, 2018
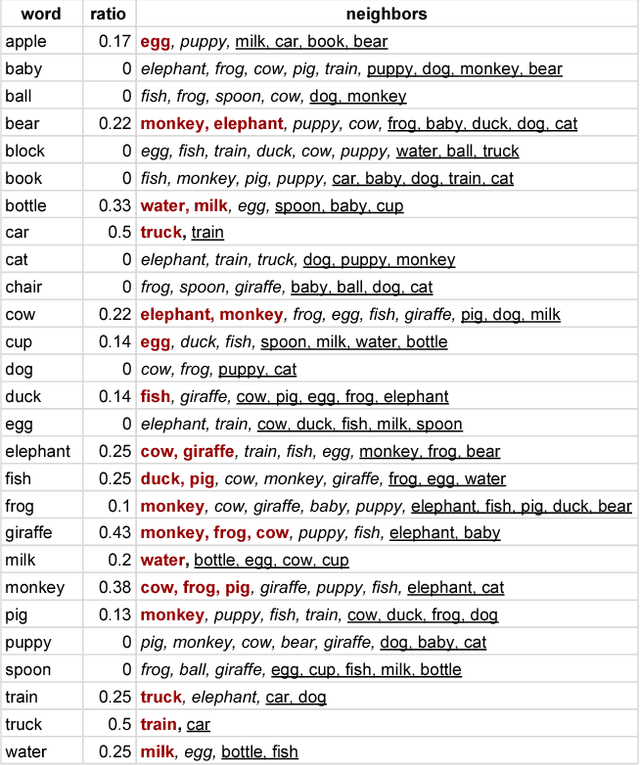
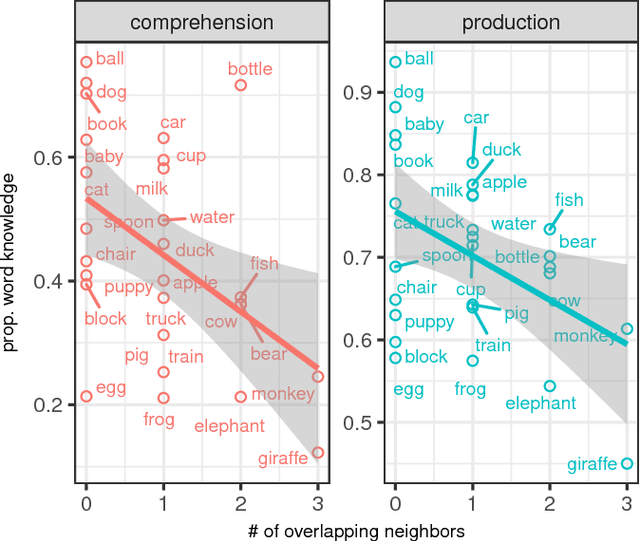
Certain concepts, words, and images are intuitively more similar than others (dog vs. cat, dog vs. spoon), though quantifying such similarity is notoriously difficult. Indeed, this kind of computation is likely a critical part of learning the category boundaries for words within a given language. Here, we use a set of 27 items (e.g. 'dog') that are highly common in infants' input, and use both image- and word-based algorithms to independently compute similarity among them. We find three key results. First, the pairwise item similarities derived within image-space and word-space are correlated, suggesting preserved structure among these extremely different representational formats. Second, the closest 'neighbors' for each item, within each space, showed significant overlap (e.g. both found 'egg' as a neighbor of 'apple'). Third, items with the most overlapping neighbors are later-learned by infants and toddlers. We conclude that this approach, which does not rely on human ratings of similarity, may nevertheless reflect stable within-class structure across these two spaces. We speculate that such invariance might aid lexical acquisition, by serving as an informative marker of category boundaries.