 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023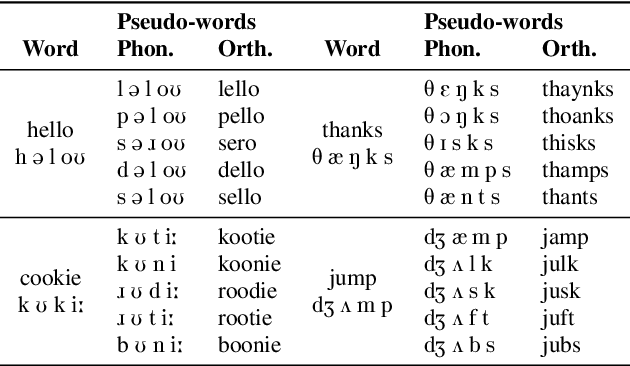
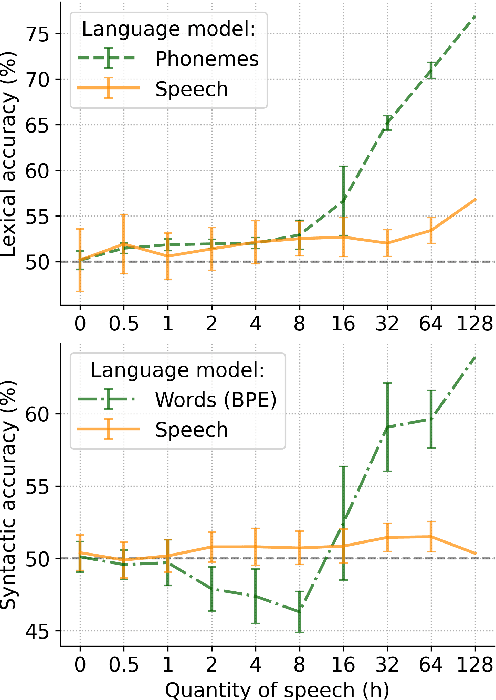
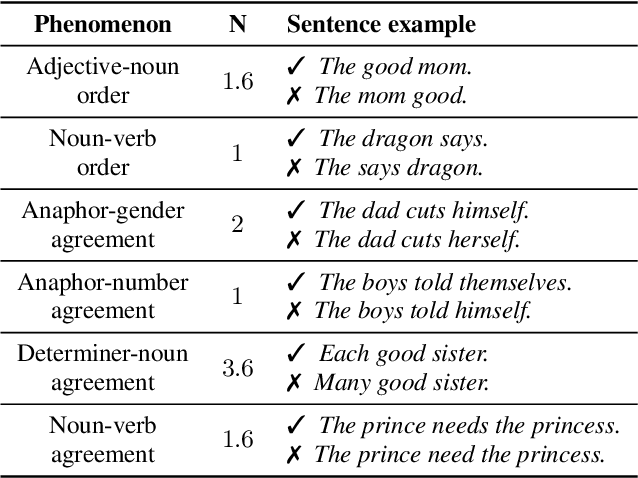
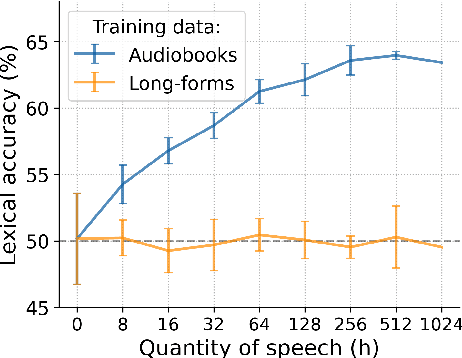
Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
ProsAudit, a prosodic benchmark for self-supervised speech models
Feb 24, 2023



We present ProsAudit, a benchmark in English to assess structural prosodic knowledge in self-supervised learning (SSL) speech models. It consists of two subtasks, their corresponding metrics, an evaluation dataset. In the protosyntax task, the model must correctly identify strong versus weak prosodic boundaries. In the lexical task, the model needs to correctly distinguish between pauses inserted between words and within words. We also provide human evaluation scores on this benchmark. We evaluated a series of SSL models and found that they were all able to perform above chance on both tasks, even when trained on an unseen language. However, non-native models performed significantly worse than native ones on the lexical task, highlighting the importance of lexical knowledge in this task. We also found a clear effect of size with models trained on more data performing better in the two subtasks.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Comparison of Speaker Role Recognition and Speaker Enrollment Protocol for conversational Clinical Interviews
Nov 05, 2020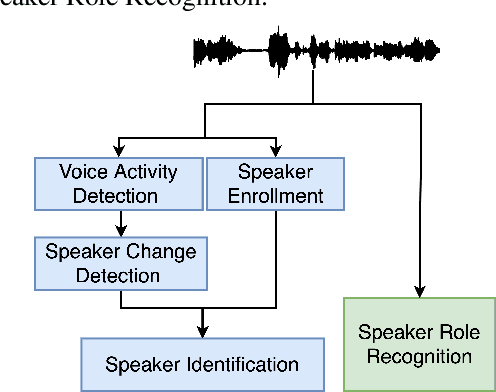
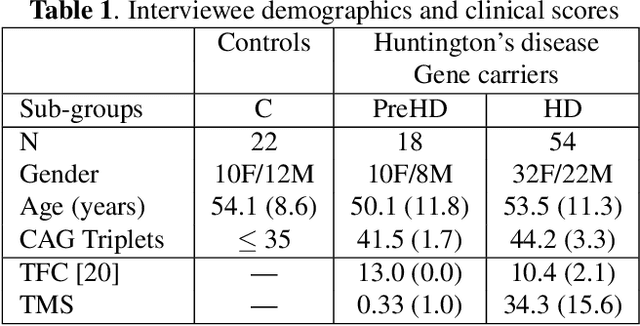
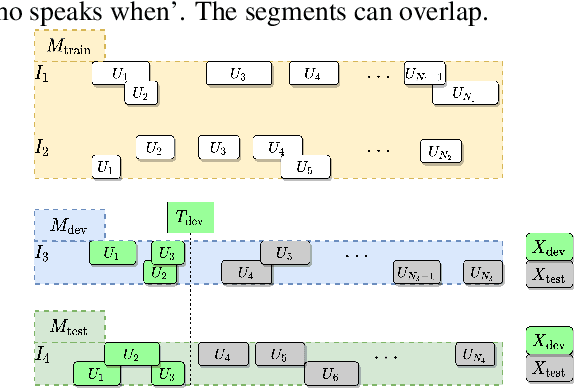
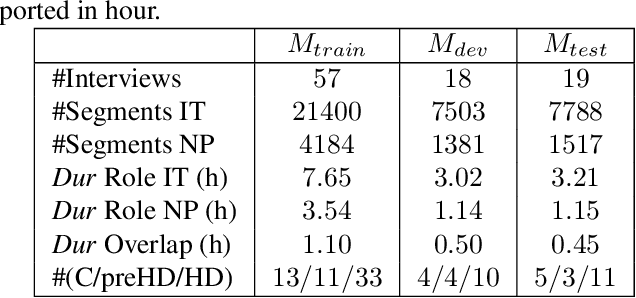
Conversations between a clinician and a patient, in natural conditions, are valuable sources of information for medical follow-up. The automatic analysis of these dialogues could help extract new language markers and speed-up the clinicians' reports. Yet, it is not clear which speech processing pipeline is the most performing to detect and identify the speaker turns, especially for individuals with speech and language disorders. Here, we proposed a split of the data that allows conducting a comparative evaluation of speaker role recognition and speaker enrollment methods to solve this task. We trained end-to-end neural network architectures to adapt to each task and evaluate each approach under the same metric. Experimental results are reported on naturalistic clinical conversations between Neuropsychologist and Interviewees, at different stages of Huntington's disease. We found that our Speaker Role Recognition model gave the best performances. In addition, our study underlined the importance of retraining models with in-domain data. Finally, we observed that results do not depend on the demographics of the Interviewee, highlighting the clinical relevance of our methods.
Vocal markers from sustained phonation in Huntington's Disease
Jun 09, 2020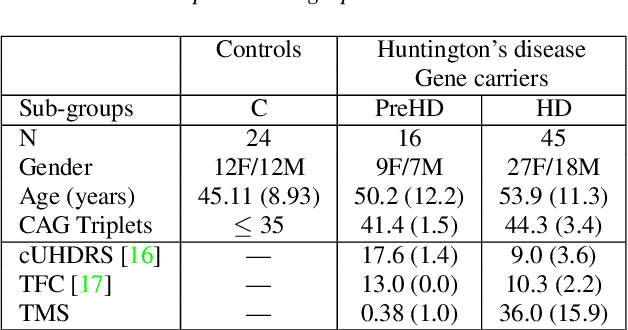
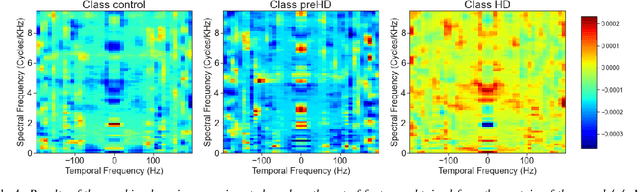
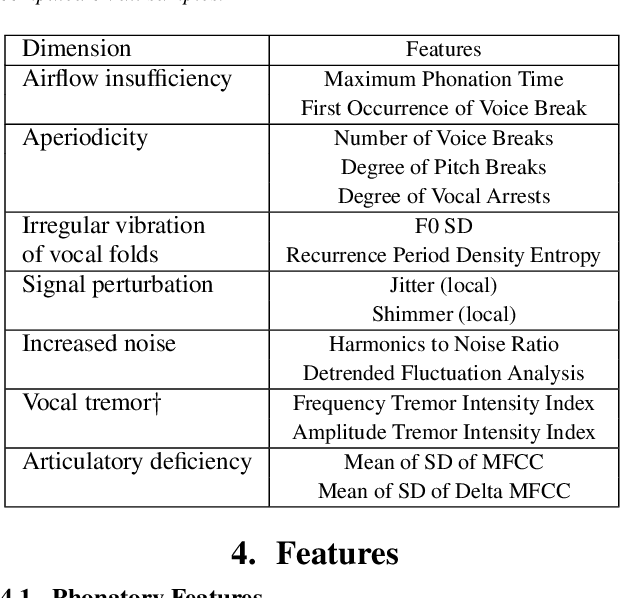
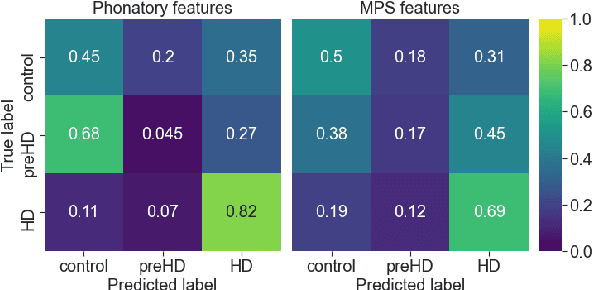
Disease-modifying treatments are currently assessed in neurodegenerative diseases. Huntington's Disease represents a unique opportunity to design automatic sub-clinical markers, even in premanifest gene carriers. We investigated phonatory impairments as potential clinical markers and propose them for both diagnosis and gene carriers follow-up. We used two sets of features: Phonatory features and Modulation Power Spectrum Features. We found that phonation is not sufficient for the identification of sub-clinical disorders of premanifest gene carriers. According to our regression results, Phonatory features are suitable for the predictions of clinical performance in Huntington's Disease.
Seshat: A tool for managing and verifying annotation campaigns of audio data
Mar 03, 2020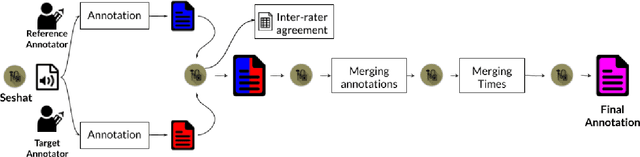
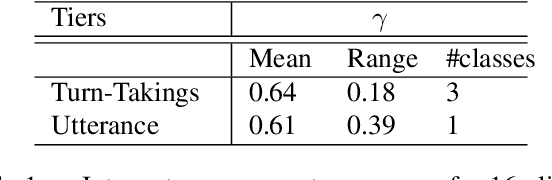


We introduce Seshat, a new, simple and open-source software to efficiently manage annotations of speech corpora. The Seshat software allows users to easily customise and manage annotations of large audio corpora while ensuring compliance with the formatting and naming conventions of the annotated output files. In addition, it includes procedures for checking the content of annotations following specific rules are implemented in personalised parsers. Finally, we propose a double-annotation mode, for which Seshat computes automatically an associated inter-annotator agreement with the $\gamma$ measure taking into account the categorisation and segmentation discrepancies.