 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Speaker Role Recognition and Speaker Enrollment Protocol for conversational Clinical Interviews
Nov 05, 2020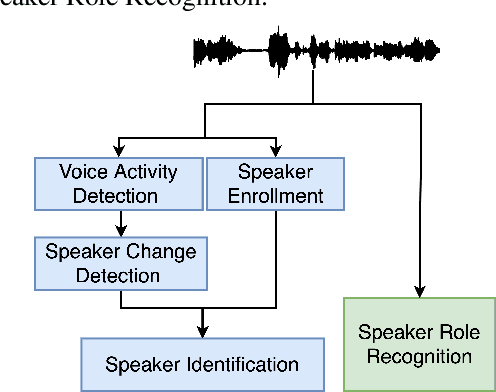
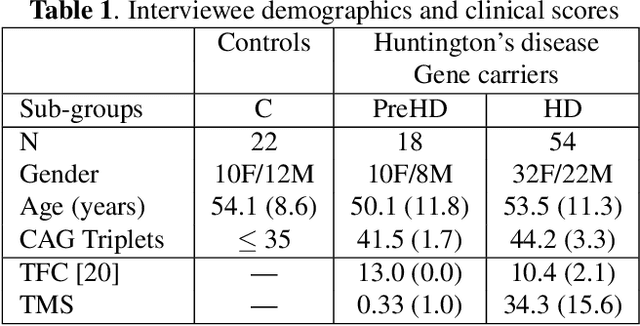
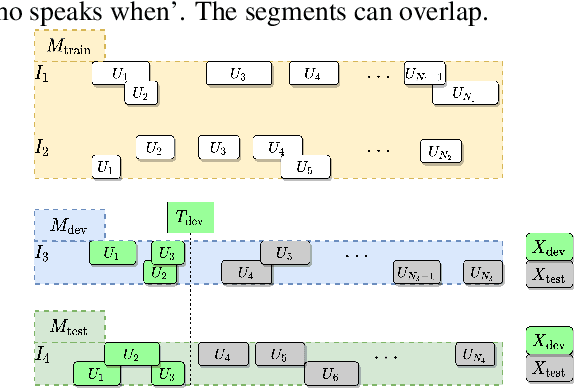
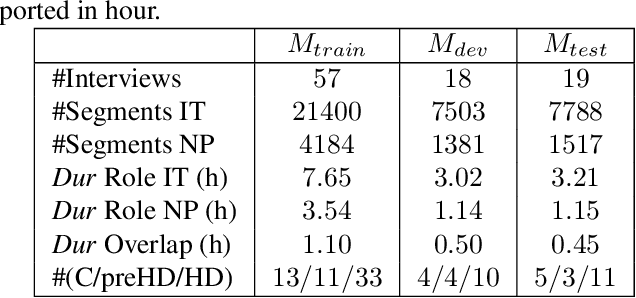
Conversations between a clinician and a patient, in natural conditions, are valuable sources of information for medical follow-up. The automatic analysis of these dialogues could help extract new language markers and speed-up the clinicians' reports. Yet, it is not clear which speech processing pipeline is the most performing to detect and identify the speaker turns, especially for individuals with speech and language disorders. Here, we proposed a split of the data that allows conducting a comparative evaluation of speaker role recognition and speaker enrollment methods to solve this task. We trained end-to-end neural network architectures to adapt to each task and evaluate each approach under the same metric. Experimental results are reported on naturalistic clinical conversations between Neuropsychologist and Interviewees, at different stages of Huntington's disease. We found that our Speaker Role Recognition model gave the best performances. In addition, our study underlined the importance of retraining models with in-domain data. Finally, we observed that results do not depend on the demographics of the Interviewee, highlighting the clinical relevance of our methods.