 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning spectro-temporal representations of complex sounds with parameterized neural networks
Mar 12, 2021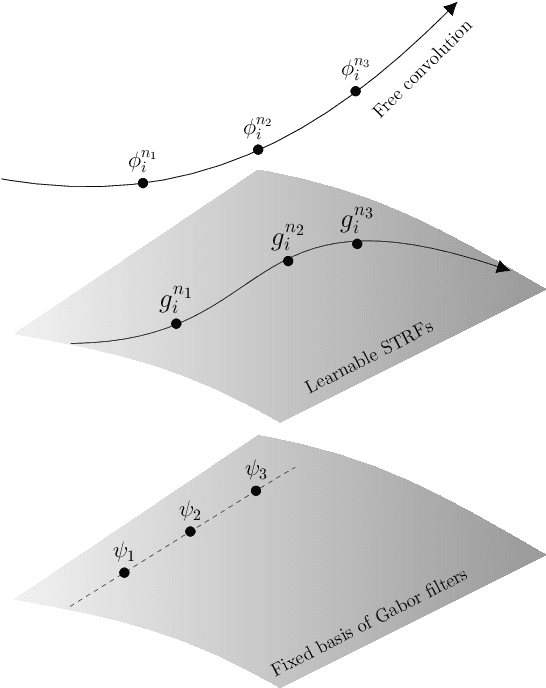
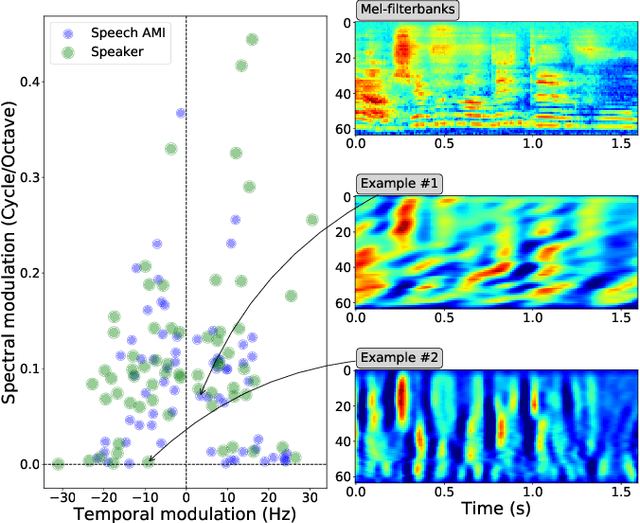
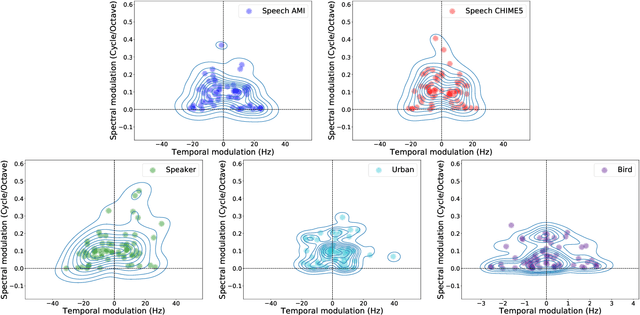
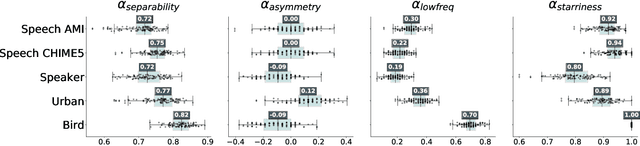
Deep Learning models have become potential candidates for auditory neuroscience research, thanks to their recent successes on a variety of auditory tasks. Yet, these models often lack interpretability to fully understand the exact computations that have been performed. Here, we proposed a parametrized neural network layer, that computes specific spectro-temporal modulations based on Gabor kernels (Learnable STRFs) and that is fully interpretable. We evaluated predictive capabilities of this layer on Speech Activity Detection, Speaker Verification, Urban Sound Classification and Zebra Finch Call Type Classification. We found out that models based on Learnable STRFs are on par for all tasks with different toplines, and obtain the best performance for Speech Activity Detection. As this layer is fully interpretable, we used quantitative measures to describe the distribution of the learned spectro-temporal modulations. The filters adapted to each task and focused mostly on low temporal and spectral modulations. The analyses show that the filters learned on human speech have similar spectro-temporal parameters as the ones measured directly in the human auditory cortex. Finally, we observed that the tasks organized in a meaningful way: the human vocalizations tasks closer to each other and bird vocalizations far away from human vocalizations and urban sounds tasks.
Comparison of Speaker Role Recognition and Speaker Enrollment Protocol for conversational Clinical Interviews
Nov 05, 2020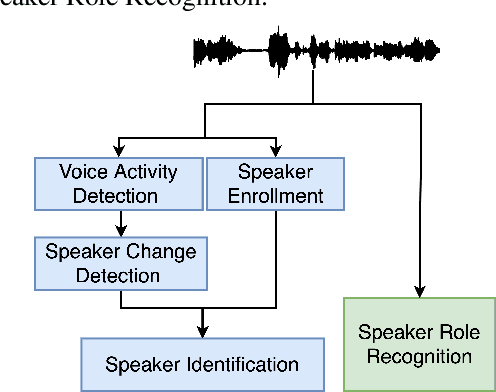
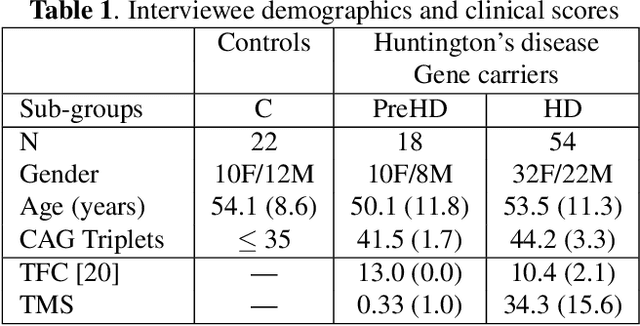
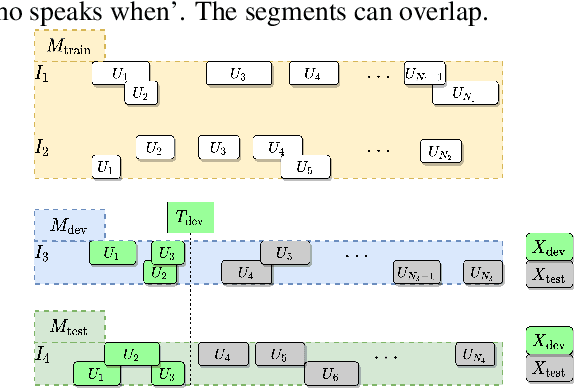
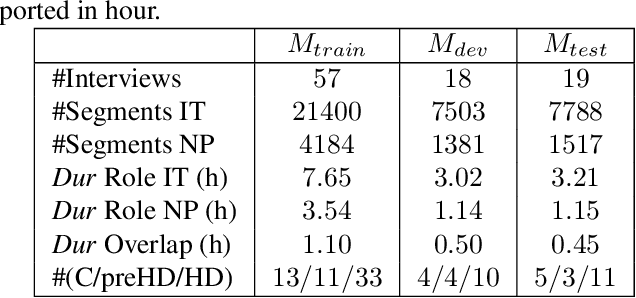
Conversations between a clinician and a patient, in natural conditions, are valuable sources of information for medical follow-up. The automatic analysis of these dialogues could help extract new language markers and speed-up the clinicians' reports. Yet, it is not clear which speech processing pipeline is the most performing to detect and identify the speaker turns, especially for individuals with speech and language disorders. Here, we proposed a split of the data that allows conducting a comparative evaluation of speaker role recognition and speaker enrollment methods to solve this task. We trained end-to-end neural network architectures to adapt to each task and evaluate each approach under the same metric. Experimental results are reported on naturalistic clinical conversations between Neuropsychologist and Interviewees, at different stages of Huntington's disease. We found that our Speaker Role Recognition model gave the best performances. In addition, our study underlined the importance of retraining models with in-domain data. Finally, we observed that results do not depend on the demographics of the Interviewee, highlighting the clinical relevance of our methods.
Vocal markers from sustained phonation in Huntington's Disease
Jun 09, 2020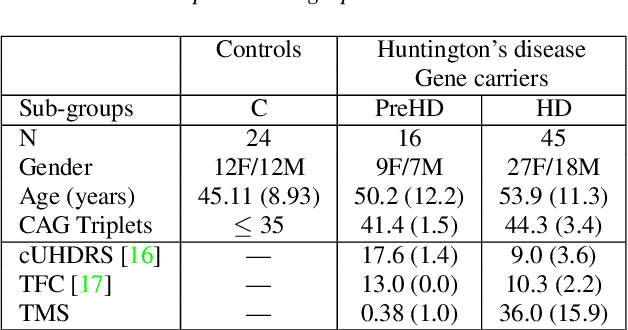
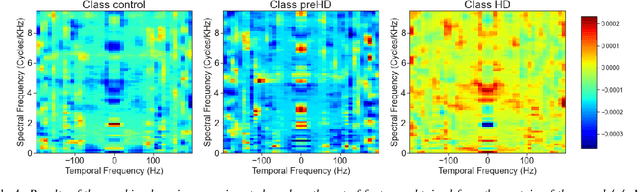
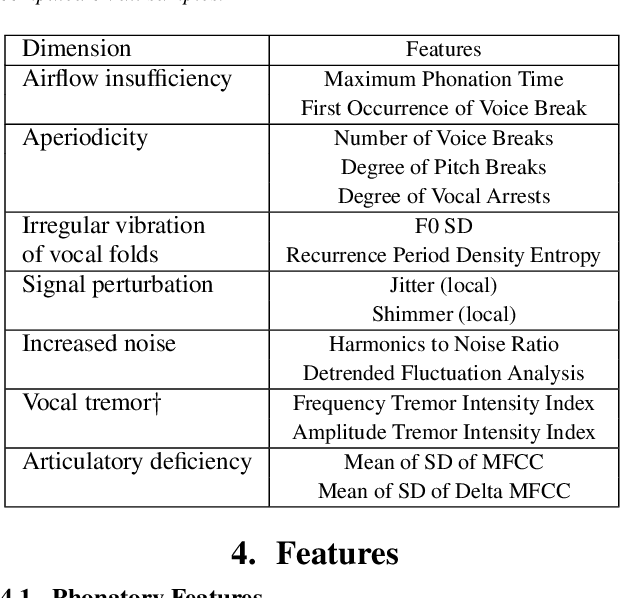
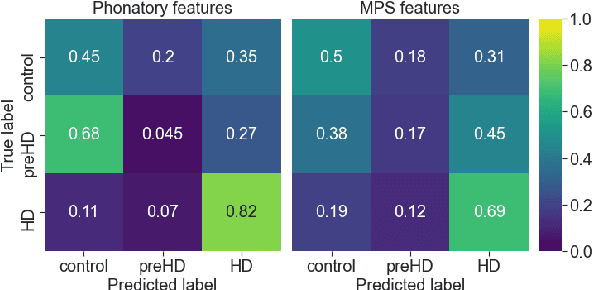
Disease-modifying treatments are currently assessed in neurodegenerative diseases. Huntington's Disease represents a unique opportunity to design automatic sub-clinical markers, even in premanifest gene carriers. We investigated phonatory impairments as potential clinical markers and propose them for both diagnosis and gene carriers follow-up. We used two sets of features: Phonatory features and Modulation Power Spectrum Features. We found that phonation is not sufficient for the identification of sub-clinical disorders of premanifest gene carriers. According to our regression results, Phonatory features are suitable for the predictions of clinical performance in Huntington's Disease.
Seshat: A tool for managing and verifying annotation campaigns of audio data
Mar 03, 2020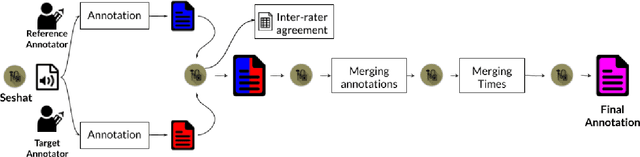
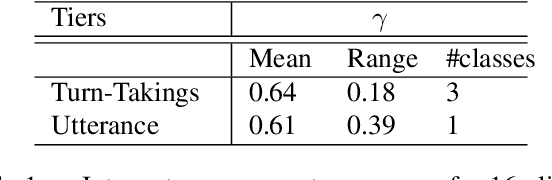


We introduce Seshat, a new, simple and open-source software to efficiently manage annotations of speech corpora. The Seshat software allows users to easily customise and manage annotations of large audio corpora while ensuring compliance with the formatting and naming conventions of the annotated output files. In addition, it includes procedures for checking the content of annotations following specific rules are implemented in personalised parsers. Finally, we propose a double-annotation mode, for which Seshat computes automatically an associated inter-annotator agreement with the $\gamma$ measure taking into account the categorisation and segmentation discrepancies.
Identification of primary and collateral tracks in stuttered speech
Mar 02, 2020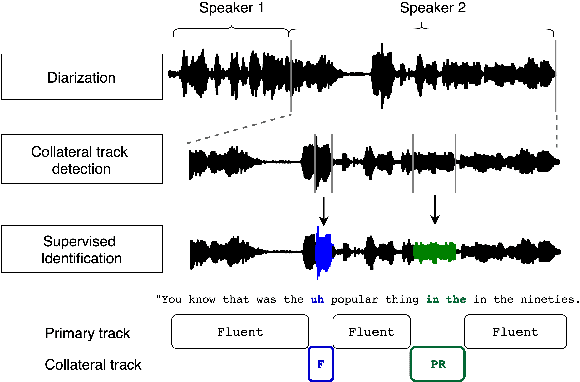

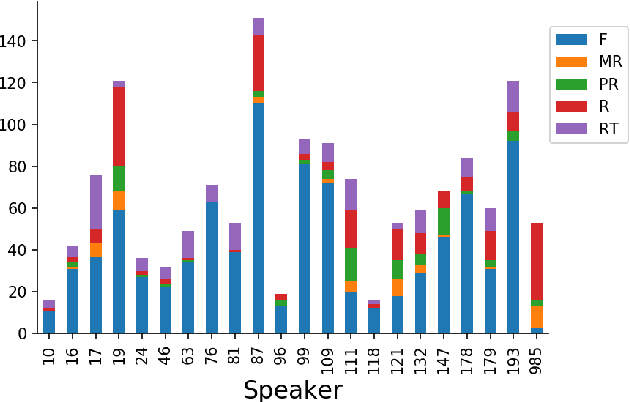

Disfluent speech has been previously addressed from two main perspectives: the clinical perspective focusing on diagnostic, and the Natural Language Processing (NLP) perspective aiming at modeling these events and detect them for downstream tasks. In addition, previous works often used different metrics depending on whether the input features are text or speech, making it difficult to compare the different contributions. Here, we introduce a new evaluation framework for disfluency detection inspired by the clinical and NLP perspective together with the theory of performance from \cite{clark1996using} which distinguishes between primary and collateral tracks. We introduce a novel forced-aligned disfluency dataset from a corpus of semi-directed interviews, and present baseline results directly comparing the performance of text-based features (word and span information) and speech-based (acoustic-prosodic information). Finally, we introduce new audio features inspired by the word-based span features. We show experimentally that using these features outperformed the baselines for speech-based predictions on the present dataset.