 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAP: Learning Speaker and Health-Related Representations from Natural Language Supervision
Oct 02, 2025Speech encodes paralinguistic information such as demographics, voice quality, and health. Yet no audio foundation model supports zero-shot or out-of-distribution (OOD) generalization to these tasks. We introduce SLAP (Speaker contrastive Language-Audio Pretraining), the first model aligning speech with natural language descriptions of speaker and health metadata through contrastive learning. SLAP combines a Vision Transformer audio encoder with text encoders, trained on more than 3400 hours across 9 datasets with diverse speaker annotations. We evaluated on 38 binary classification tasks spanning demographics, voice characteristics, and clinical assessments across 14 datasets in 7 languages. SLAP achieves 62.9% average F1 in zero-shot evaluation, a 48% relative improvement over CLAP (42.4%), while demonstrating strong OOD generalization to unseen languages and clinical populations. When fine-tuned with linear probing, SLAP reaches 69.3% F1 overall and achieves best-in-class performance on health tasks (57.9% F1), surpassing larger foundation models.
Robust fine-tuning of speech recognition models via model merging: application to disordered speech
May 26, 2025Automatic Speech Recognition (ASR) has advanced with Speech Foundation Models (SFMs), yet performance degrades on dysarthric speech due to variability and limited data. This study as part of the submission to the Speech Accessibility challenge, explored model merging to improve ASR generalization using Whisper as the base SFM. We compared fine-tuning with single-trajectory merging, combining models from one fine-tuning path, and multi-run merging, merging independently trained models. Our best multi-run merging approach achieved a 12% relative decrease of WER over classic fine-tuning, and a 16.2% relative decrease on long-form audios, a major loss contributor in dysarthric ASR. Merging more and more models led to continuous gains, remained effective in low-data regimes, and generalized across model architectures. These results highlight model merging as an easily replicable adaptation method that consistently improves ASR without additional inference cost or hyperparameter tuning.
In-context learning capabilities of Large Language Models to detect suicide risk among adolescents from speech transcripts
May 26, 2025Early suicide risk detection in adolescents is critical yet hindered by scalability challenges of current assessments. This paper presents our approach to the first SpeechWellness Challenge (SW1), which aims to assess suicide risk in Chinese adolescents through speech analysis. Due to speech anonymization constraints, we focused on linguistic features, leveraging Large Language Models (LLMs) for transcript-based classification. Using DSPy for systematic prompt engineering, we developed a robust in-context learning approach that outperformed traditional fine-tuning on both linguistic and acoustic markers. Our systems achieved third and fourth places among 180+ submissions, with 0.68 accuracy (F1=0.7) using only transcripts. Ablation analyses showed that increasing prompt example improved performance (p=0.003), with varying effects across model types and sizes. These findings advance automated suicide risk assessment and demonstrate LLMs' value in mental health applications.
Quantized Approximate Signal Processing (QASP): Towards Homomorphic Encryption for audio
May 15, 2025



Audio and speech data are increasingly used in machine learning applications such as speech recognition, speaker identification, and mental health monitoring. However, the passive collection of this data by audio listening devices raises significant privacy concerns. Fully homomorphic encryption (FHE) offers a promising solution by enabling computations on encrypted data and preserving user privacy. Despite its potential, prior attempts to apply FHE to audio processing have faced challenges, particularly in securely computing time frequency representations, a critical step in many audio tasks. Here, we addressed this gap by introducing a fully secure pipeline that computes, with FHE and quantized neural network operations, four fundamental time-frequency representations: Short-Time Fourier Transform (STFT), Mel filterbanks, Mel-frequency cepstral coefficients (MFCCs), and gammatone filters. Our methods also support the private computation of audio descriptors and convolutional neural network (CNN) classifiers. Besides, we proposed approximate STFT algorithms that lighten computation and bit use for statistical and machine learning analyses. We ran experiments on the VocalSet and OxVoc datasets demonstrating the fully private computation of our approach. We showed significant performance improvements with STFT approximation in private statistical analysis of audio markers, and for vocal exercise classification with CNNs. Our results reveal that our approximations substantially reduce error rates compared to conventional STFT implementations in FHE. We also demonstrated a fully private classification based on the raw audio for gender and vocal exercise classification. Finally, we provided a practical heuristic for parameter selection, making quantized approximate signal processing accessible to researchers and practitioners aiming to protect sensitive audio data.
Probing mental health information in speech foundation models
Sep 27, 2024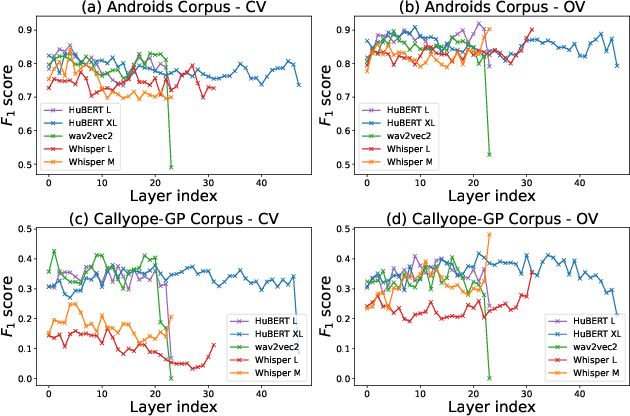
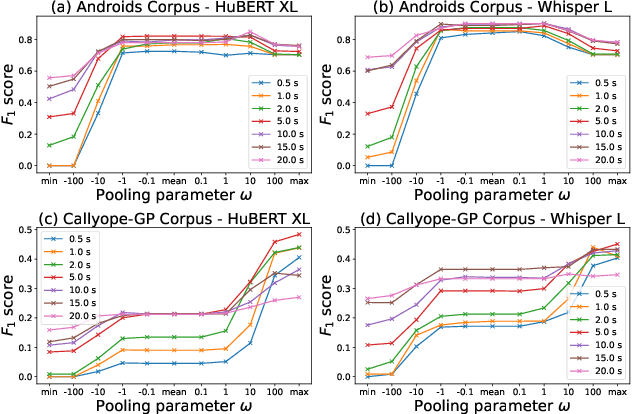
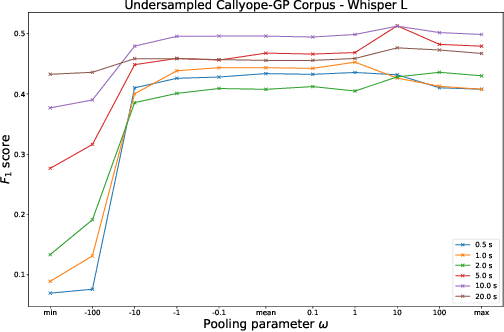
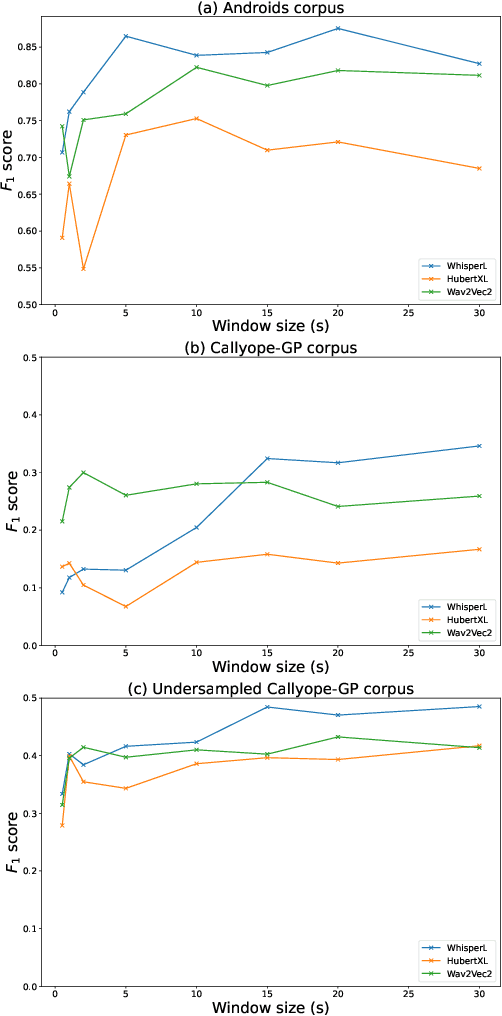
Non-invasive methods for diagnosing mental health conditions, such as speech analysis, offer promising potential in modern medicine. Recent advancements in machine learning, particularly speech foundation models, have shown significant promise in detecting mental health states by capturing diverse features. This study investigates which pretext tasks in these models best transfer to mental health detection and examines how different model layers encode features relevant to mental health conditions. We also probed the optimal length of audio segments and the best pooling strategies to improve detection accuracy. Using the Callyope-GP and Androids datasets, we evaluated the models' effectiveness across different languages and speech tasks, aiming to enhance the generalizability of speech-based mental health diagnostics. Our approach achieved SOTA scores in depression detection on the Androids dataset.
Learning strides in convolutional neural networks
Feb 03, 2022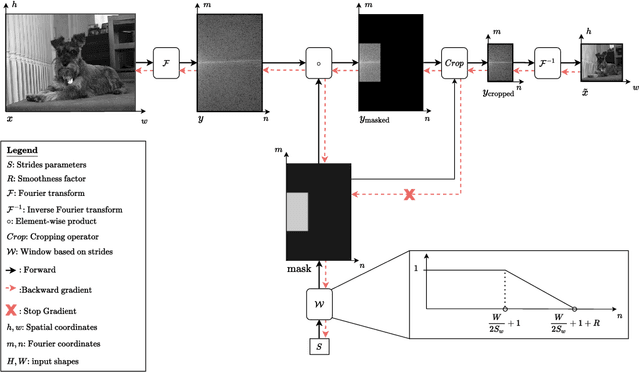
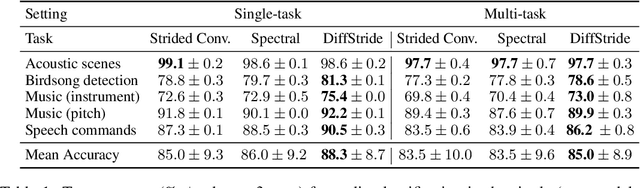
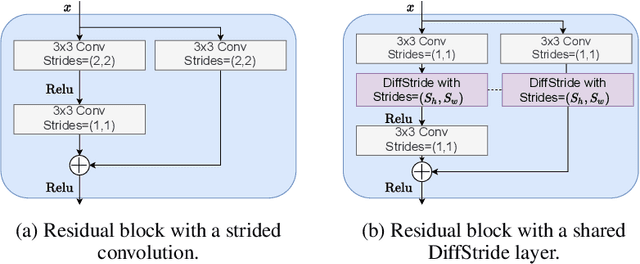
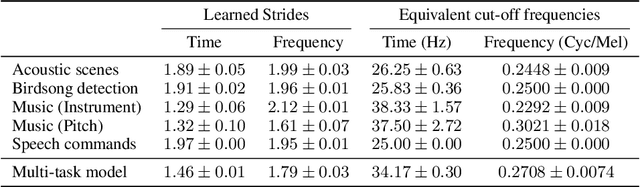
Convolutional neural networks typically contain several downsampling operators, such as strided convolutions or pooling layers, that progressively reduce the resolution of intermediate representations. This provides some shift-invariance while reducing the computational complexity of the whole architecture. A critical hyperparameter of such layers is their stride: the integer factor of downsampling. As strides are not differentiable, finding the best configuration either requires cross-validation or discrete optimization (e.g. architecture search), which rapidly become prohibitive as the search space grows exponentially with the number of downsampling layers. Hence, exploring this search space by gradient descent would allow finding better configurations at a lower computational cost. This work introduces DiffStride, the first downsampling layer with learnable strides. Our layer learns the size of a cropping mask in the Fourier domain, that effectively performs resizing in a differentiable way. Experiments on audio and image classification show the generality and effectiveness of our solution: we use DiffStride as a drop-in replacement to standard downsampling layers and outperform them. In particular, we show that introducing our layer into a ResNet-18 architecture allows keeping consistent high performance on CIFAR10, CIFAR100 and ImageNet even when training starts from poor random stride configurations. Moreover, formulating strides as learnable variables allows us to introduce a regularization term that controls the computational complexity of the architecture. We show how this regularization allows trading off accuracy for efficiency on ImageNet.
Learning spectro-temporal representations of complex sounds with parameterized neural networks
Mar 12, 2021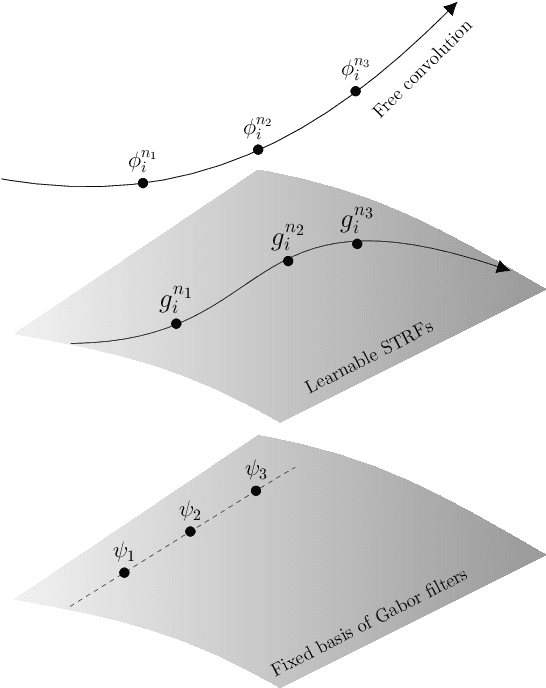
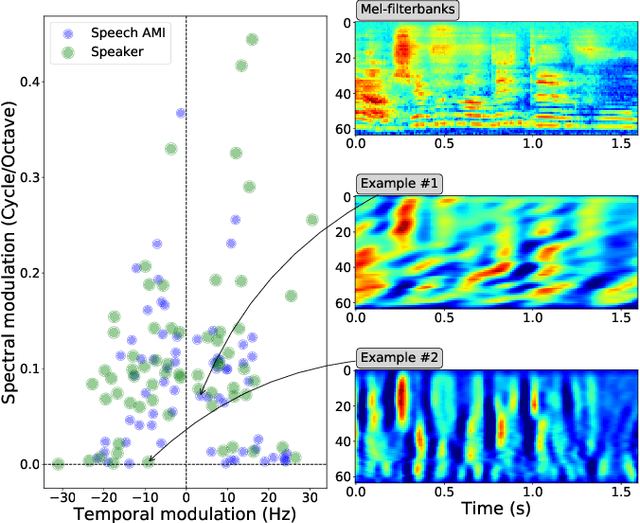
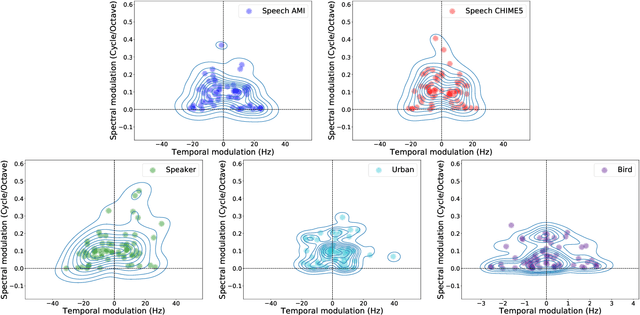
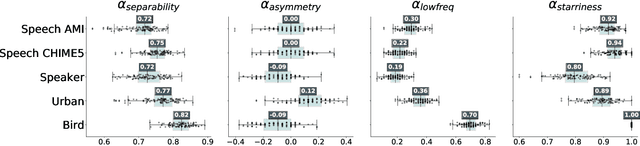
Deep Learning models have become potential candidates for auditory neuroscience research, thanks to their recent successes on a variety of auditory tasks. Yet, these models often lack interpretability to fully understand the exact computations that have been performed. Here, we proposed a parametrized neural network layer, that computes specific spectro-temporal modulations based on Gabor kernels (Learnable STRFs) and that is fully interpretable. We evaluated predictive capabilities of this layer on Speech Activity Detection, Speaker Verification, Urban Sound Classification and Zebra Finch Call Type Classification. We found out that models based on Learnable STRFs are on par for all tasks with different toplines, and obtain the best performance for Speech Activity Detection. As this layer is fully interpretable, we used quantitative measures to describe the distribution of the learned spectro-temporal modulations. The filters adapted to each task and focused mostly on low temporal and spectral modulations. The analyses show that the filters learned on human speech have similar spectro-temporal parameters as the ones measured directly in the human auditory cortex. Finally, we observed that the tasks organized in a meaningful way: the human vocalizations tasks closer to each other and bird vocalizations far away from human vocalizations and urban sounds tasks.
Comparison of Speaker Role Recognition and Speaker Enrollment Protocol for conversational Clinical Interviews
Nov 05, 2020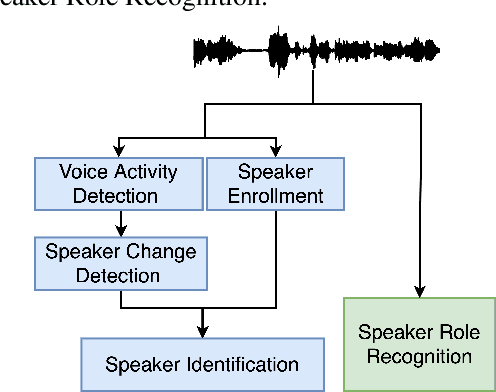
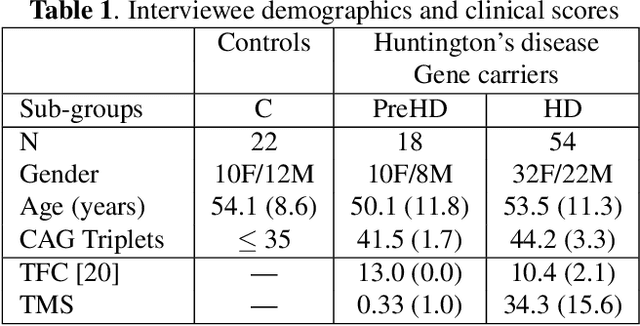
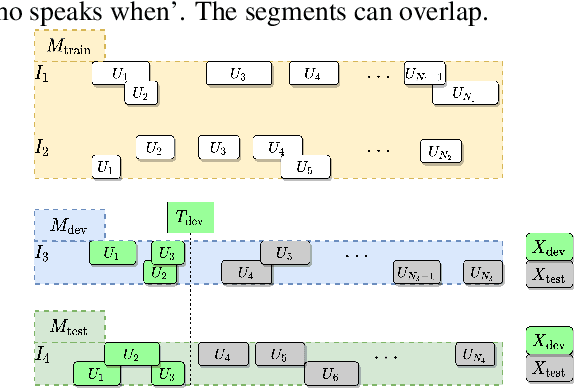
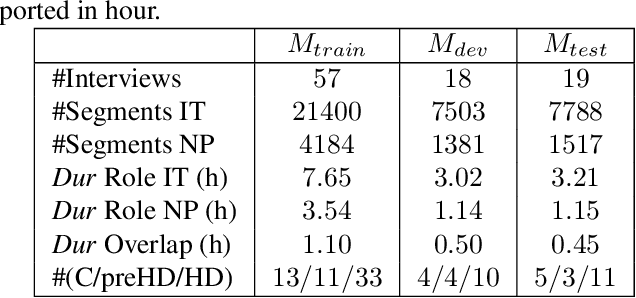
Conversations between a clinician and a patient, in natural conditions, are valuable sources of information for medical follow-up. The automatic analysis of these dialogues could help extract new language markers and speed-up the clinicians' reports. Yet, it is not clear which speech processing pipeline is the most performing to detect and identify the speaker turns, especially for individuals with speech and language disorders. Here, we proposed a split of the data that allows conducting a comparative evaluation of speaker role recognition and speaker enrollment methods to solve this task. We trained end-to-end neural network architectures to adapt to each task and evaluate each approach under the same metric. Experimental results are reported on naturalistic clinical conversations between Neuropsychologist and Interviewees, at different stages of Huntington's disease. We found that our Speaker Role Recognition model gave the best performances. In addition, our study underlined the importance of retraining models with in-domain data. Finally, we observed that results do not depend on the demographics of the Interviewee, highlighting the clinical relevance of our methods.
Vocal markers from sustained phonation in Huntington's Disease
Jun 09, 2020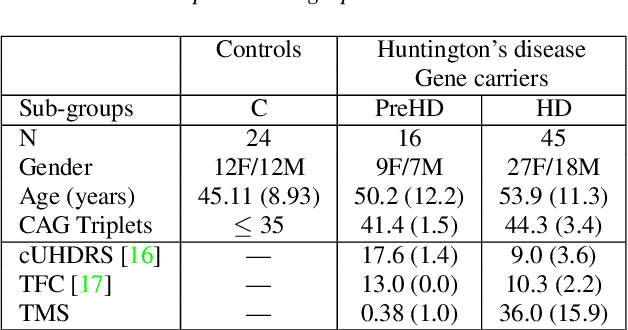
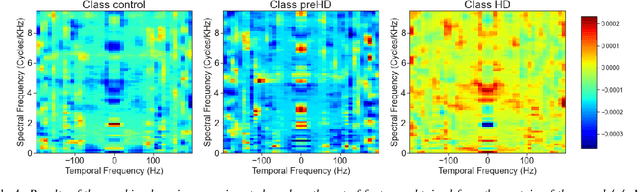
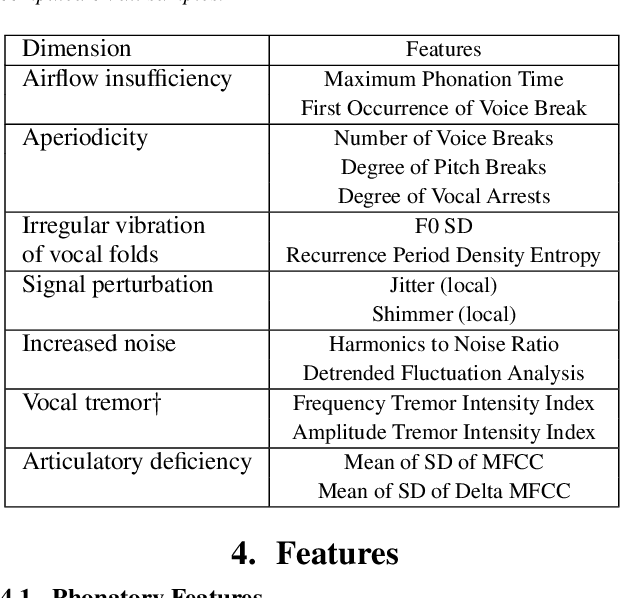
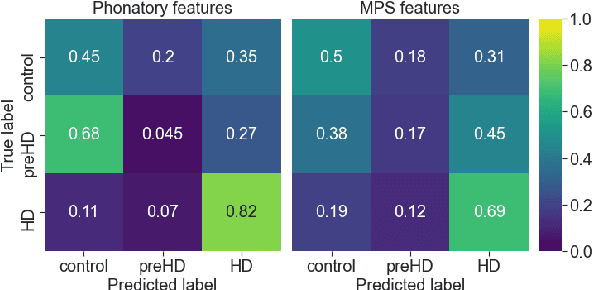
Disease-modifying treatments are currently assessed in neurodegenerative diseases. Huntington's Disease represents a unique opportunity to design automatic sub-clinical markers, even in premanifest gene carriers. We investigated phonatory impairments as potential clinical markers and propose them for both diagnosis and gene carriers follow-up. We used two sets of features: Phonatory features and Modulation Power Spectrum Features. We found that phonation is not sufficient for the identification of sub-clinical disorders of premanifest gene carriers. According to our regression results, Phonatory features are suitable for the predictions of clinical performance in Huntington's Disease.
Seshat: A tool for managing and verifying annotation campaigns of audio data
Mar 03, 2020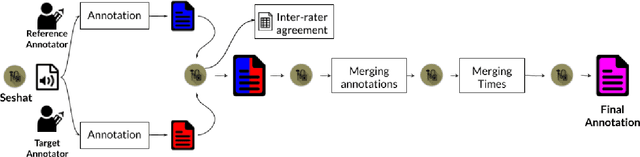
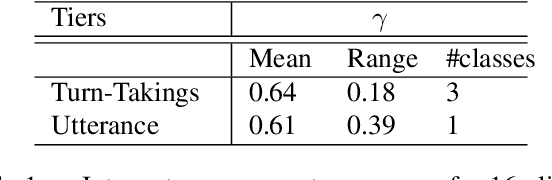


We introduce Seshat, a new, simple and open-source software to efficiently manage annotations of speech corpora. The Seshat software allows users to easily customise and manage annotations of large audio corpora while ensuring compliance with the formatting and naming conventions of the annotated output files. In addition, it includes procedures for checking the content of annotations following specific rules are implemented in personalised parsers. Finally, we propose a double-annotation mode, for which Seshat computes automatically an associated inter-annotator agreement with the $\gamma$ measure taking into account the categorisation and segmentation discrepancies.