 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing mental health information in speech foundation models
Paper and Code
Sep 27, 2024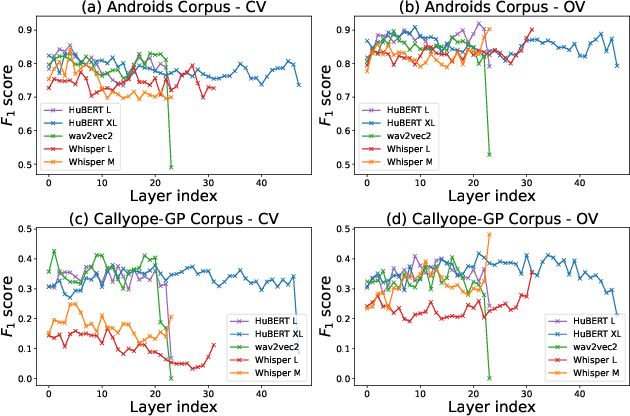
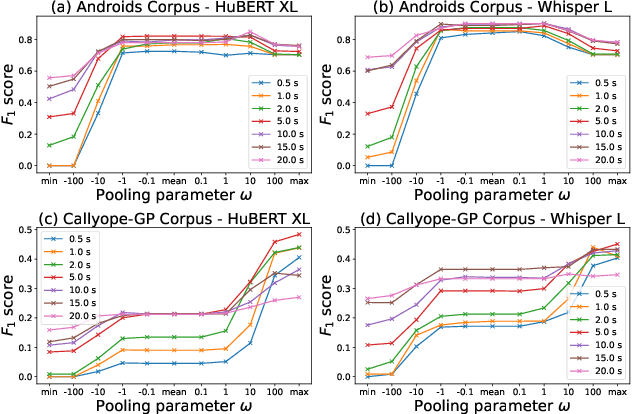
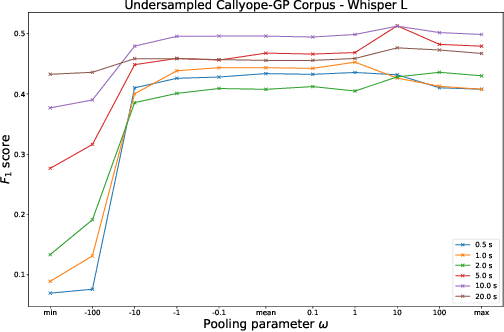
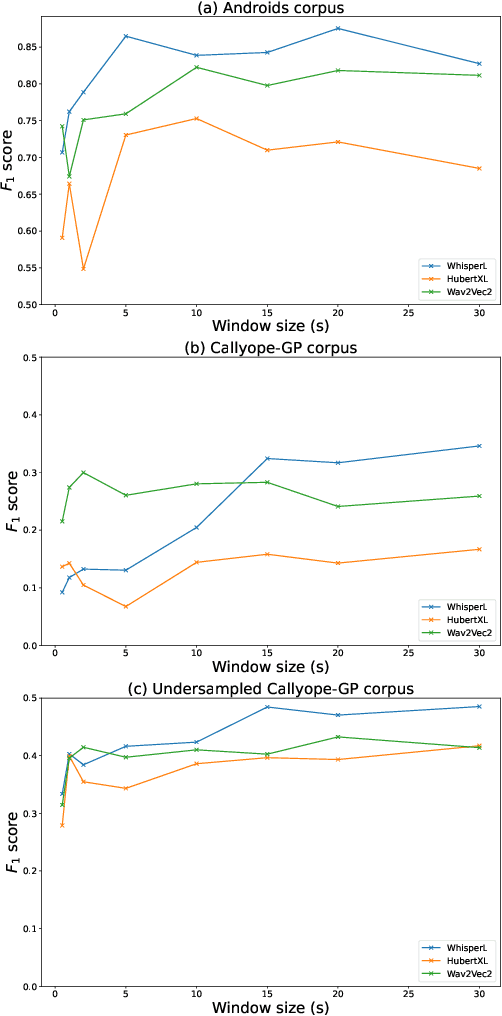
Non-invasive methods for diagnosing mental health conditions, such as speech analysis, offer promising potential in modern medicine. Recent advancements in machine learning, particularly speech foundation models, have shown significant promise in detecting mental health states by capturing diverse features. This study investigates which pretext tasks in these models best transfer to mental health detection and examines how different model layers encode features relevant to mental health conditions. We also probed the optimal length of audio segments and the best pooling strategies to improve detection accuracy. Using the Callyope-GP and Androids datasets, we evaluated the models' effectiveness across different languages and speech tasks, aiming to enhance the generalizability of speech-based mental health diagnostics. Our approach achieved SOTA scores in depression detection on the Androids dataset.