 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Splitting of Language Models from Mixtures to Specialized Domains
Mar 19, 2026Language models achieve impressive performance on a variety of knowledge, language, and reasoning tasks due to the scale and diversity of pretraining data available. The standard training recipe is a two-stage paradigm: pretraining first on the full corpus of data followed by specialization on a subset of high quality, specialized data from the full corpus. In the multi-domain setting, this involves continued pretraining of multiple models on each specialized domain, referred to as split model training. We propose a method for pretraining multiple models independently over a general pretraining corpus, and determining the optimal compute allocation between pretraining and continued pretraining using scaling laws. Our approach accurately predicts the loss of a model of size N with D pretraining and D' specialization tokens, and extrapolates to larger model sizes and number of tokens. Applied to language model training, our approach improves performance consistently across common sense knowledge and reasoning benchmarks across different model sizes and compute budgets.
The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining
Oct 02, 2025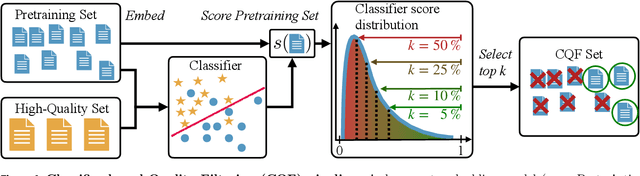
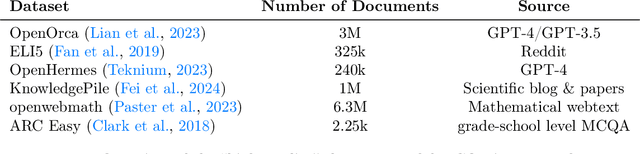
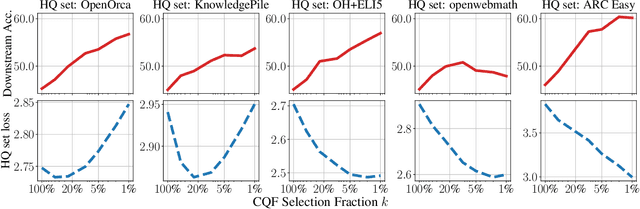
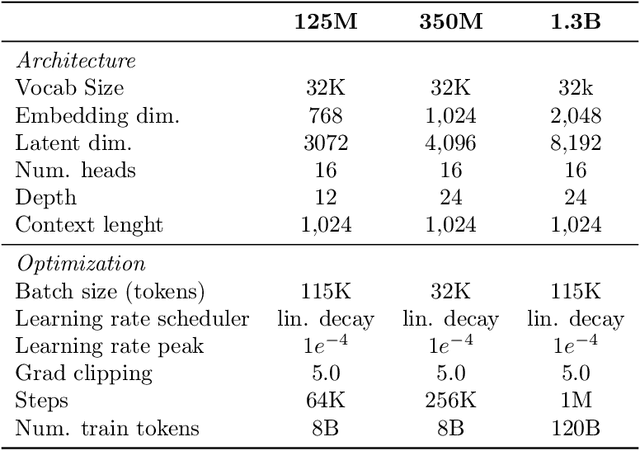
Large-scale models are pretrained on massive web-crawled datasets containing documents of mixed quality, making data filtering essential. A popular method is Classifier-based Quality Filtering (CQF), which trains a binary classifier to distinguish between pretraining data and a small, high-quality set. It assigns each pretraining document a quality score defined as the classifier's score and retains only the top-scoring ones. We provide an in-depth analysis of CQF. We show that while CQF improves downstream task performance, it does not necessarily enhance language modeling on the high-quality dataset. We explain this paradox by the fact that CQF implicitly filters the high-quality dataset as well. We further compare the behavior of models trained with CQF to those trained on synthetic data of increasing quality, obtained via random token permutations, and find starkly different trends. Our results challenge the view that CQF captures a meaningful notion of data quality.
Partial Parameter Updates for Efficient Distributed Training
Sep 26, 2025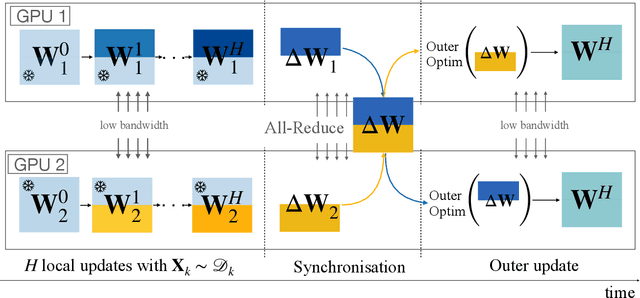
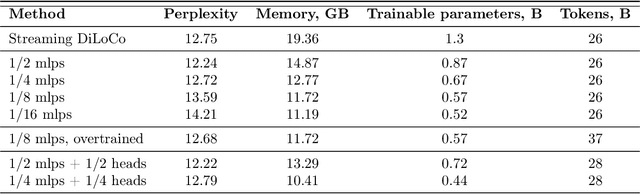
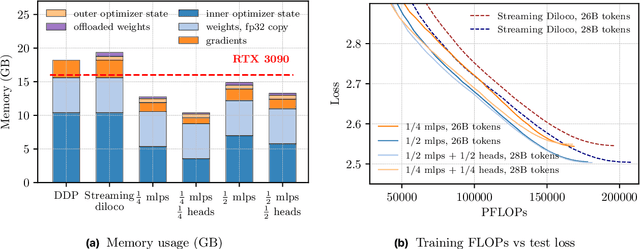
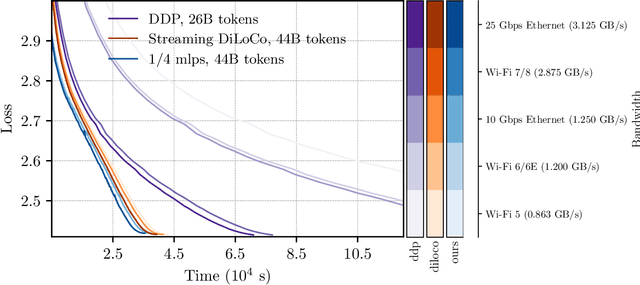
We introduce a memory- and compute-efficient method for low-communication distributed training. Existing methods reduce communication by performing multiple local updates between infrequent global synchronizations. We demonstrate that their efficiency can be significantly improved by restricting backpropagation: instead of updating all the parameters, each node updates only a fixed subset while keeping the remainder frozen during local steps. This constraint substantially reduces peak memory usage and training FLOPs, while a full forward pass over all parameters eliminates the need for cross-node activation exchange. Experiments on a $1.3$B-parameter language model trained across $32$ nodes show that our method matches the perplexity of prior low-communication approaches under identical token and bandwidth budgets while reducing training FLOPs and peak memory.
Assessing the Role of Data Quality in Training Bilingual Language Models
Jun 15, 2025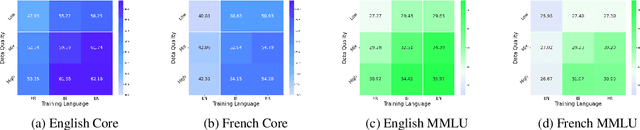
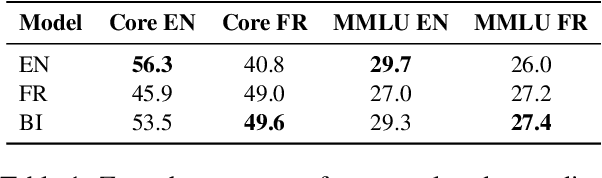
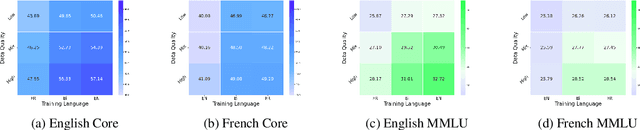
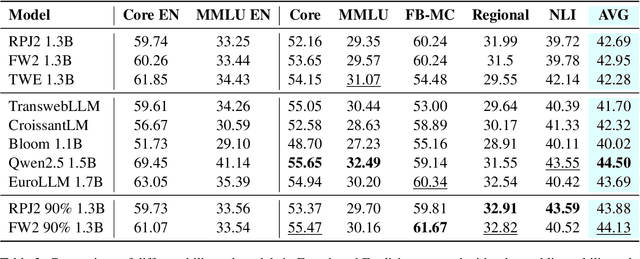
Bilingual and multilingual language models offer a promising path toward scaling NLP systems across diverse languages and users. However, their performance often varies wildly between languages as prior works show that adding more languages can degrade performance for some languages (such as English), while improving others (typically more data constrained languages). In this work, we investigate causes of these inconsistencies by comparing bilingual and monolingual language models. Our analysis reveals that unequal data quality, not just data quantity, is a major driver of performance degradation in bilingual settings. We propose a simple yet effective data filtering strategy to select higher-quality bilingual training data with only high quality English data. Applied to French, German, and Chinese, our approach improves monolingual performance by 2-4% and reduces bilingual model performance gaps to 1%. These results highlight the overlooked importance of data quality in multilingual pretraining and offer a practical recipe for balancing performance.
Scaling Laws for Forgetting during Finetuning with Pretraining Data Injection
Feb 09, 2025A widespread strategy to obtain a language model that performs well on a target domain is to finetune a pretrained model to perform unsupervised next-token prediction on data from that target domain. Finetuning presents two challenges: (i) if the amount of target data is limited, as in most practical applications, the model will quickly overfit, and (ii) the model will drift away from the original model, forgetting the pretraining data and the generic knowledge that comes with it. We aim to derive scaling laws that quantify these two phenomena for various target domains, amounts of available target data, and model scales. We measure the efficiency of injecting pretraining data into the finetuning data mixture to avoid forgetting and mitigate overfitting. A key practical takeaway from our study is that injecting as little as 1% of pretraining data in the finetuning data mixture prevents the model from forgetting the pretraining set.
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
Feb 03, 2025Machine learning models are routinely trained on a mixture of different data domains. Different domain weights yield very different downstream performances. We propose the Soup-of-Experts, a novel architecture that can instantiate a model at test time for any domain weights with minimal computational cost and without re-training the model. Our architecture consists of a bank of expert parameters, which are linearly combined to instantiate one model. We learn the linear combination coefficients as a function of the input domain weights. To train this architecture, we sample random domain weights, instantiate the corresponding model, and backprop through one batch of data sampled with these domain weights. We demonstrate how our approach obtains small specialized models on several language modeling tasks quickly. Soup-of-Experts are particularly appealing when one needs to ship many different specialist models quickly under a model size constraint.
Training Bilingual LMs with Data Constraints in the Targeted Language
Nov 20, 2024



Large language models are trained on massive scrapes of the web, as required by current scaling laws. Most progress is made for English, given its abundance of high-quality pretraining data. For most other languages, however, such high quality pretraining data is unavailable. In this work, we study how to boost pretrained model performance in a data constrained target language by enlisting data from an auxiliary language for which high quality data is available. We study this by quantifying the performance gap between training with data in a data-rich auxiliary language compared with training in the target language, exploring the benefits of translation systems, studying the limitations of model scaling for data constrained languages, and proposing new methods for upsampling data from the auxiliary language. Our results show that stronger auxiliary datasets result in performance gains without modification to the model or training objective for close languages, and, in particular, that performance gains due to the development of more information-rich English pretraining datasets can extend to targeted language settings with limited data.
Aggregate-and-Adapt Natural Language Prompts for Downstream Generalization of CLIP
Oct 31, 2024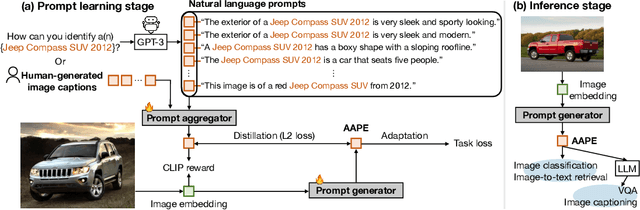
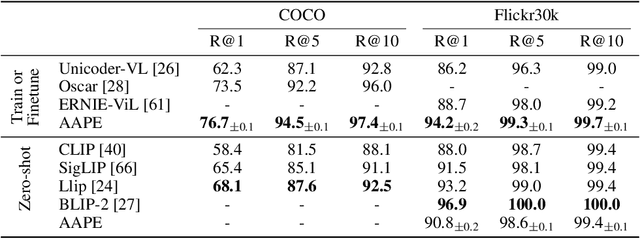

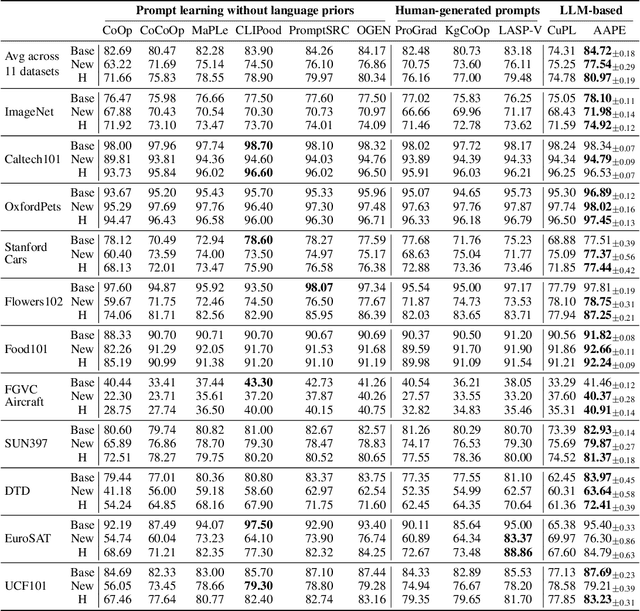
Large pretrained vision-language models like CLIP have shown promising generalization capability, but may struggle in specialized domains (e.g., satellite imagery) or fine-grained classification (e.g., car models) where the visual concepts are unseen or under-represented during pretraining. Prompt learning offers a parameter-efficient finetuning framework that can adapt CLIP to downstream tasks even when limited annotation data are available. In this paper, we improve prompt learning by distilling the textual knowledge from natural language prompts (either human- or LLM-generated) to provide rich priors for those under-represented concepts. We first obtain a prompt ``summary'' aligned to each input image via a learned prompt aggregator. Then we jointly train a prompt generator, optimized to produce a prompt embedding that stays close to the aggregated summary while minimizing task loss at the same time. We dub such prompt embedding as Aggregate-and-Adapted Prompt Embedding (AAPE). AAPE is shown to be able to generalize to different downstream data distributions and tasks, including vision-language understanding tasks (e.g., few-shot classification, VQA) and generation tasks (image captioning) where AAPE achieves competitive performance. We also show AAPE is particularly helpful to handle non-canonical and OOD examples. Furthermore, AAPE learning eliminates LLM-based inference cost as required by baselines, and scales better with data and LLM model size.
No Need to Talk: Asynchronous Mixture of Language Models
Oct 04, 2024

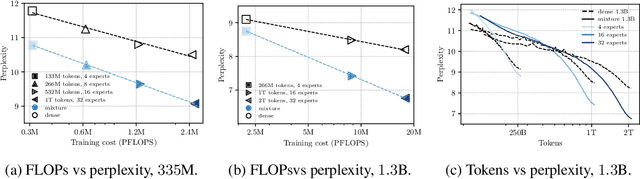
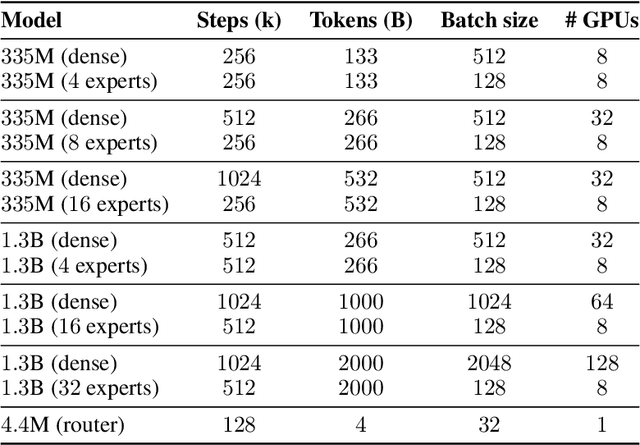
We introduce SmallTalk LM, an innovative method for training a mixture of language models in an almost asynchronous manner. Each model of the mixture specializes in distinct parts of the data distribution, without the need of high-bandwidth communication between the nodes training each model. At inference, a lightweight router directs a given sequence to a single expert, according to a short prefix. This inference scheme naturally uses a fraction of the parameters from the overall mixture model. Our experiments on language modeling demonstrate tha SmallTalk LM achieves significantly lower perplexity than dense model baselines for the same total training FLOPs and an almost identical inference cost. Finally, in our downstream evaluations we outperform the dense baseline on $75\%$ of the tasks.
Dynamic Gradient Alignment for Online Data Mixing
Oct 03, 2024



The composition of training data mixtures is critical for effectively training large language models (LLMs), as it directly impacts their performance on downstream tasks. Our goal is to identify an optimal data mixture to specialize an LLM for a specific task with access to only a few examples. Traditional approaches to this problem include ad-hoc reweighting methods, importance sampling, and gradient alignment techniques. This paper focuses on gradient alignment and introduces Dynamic Gradient Alignment (DGA), a scalable online gradient alignment algorithm. DGA dynamically estimates the pre-training data mixture on which the models' gradients align as well as possible with those of the model on the specific task. DGA is the first gradient alignment approach that incurs minimal overhead compared to standard pre-training and outputs a competitive model, eliminating the need for retraining the model. Experimentally, we demonstrate significant improvements over importance sampling in two key scenarios: (i) when the pre-training set is small and importance sampling overfits due to limited data; and (ii) when there is insufficient specialized data, trapping importance sampling on narrow pockets of data. Our findings underscore the effectiveness of gradient alignment methods in optimizing training data mixtures, particularly in data-constrained environments, and offer a practical solution for enhancing LLM performance on specific tasks with limited data availability.