 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Need to Talk: Asynchronous Mixture of Language Models
Paper and Code
Oct 04, 2024

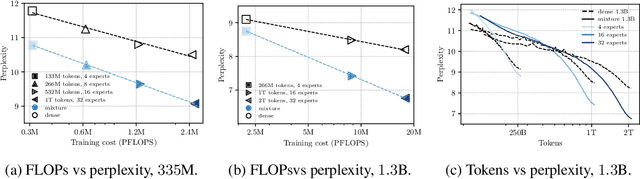
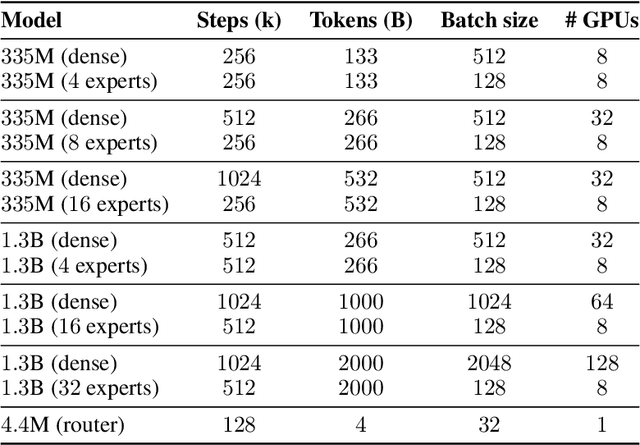
We introduce SmallTalk LM, an innovative method for training a mixture of language models in an almost asynchronous manner. Each model of the mixture specializes in distinct parts of the data distribution, without the need of high-bandwidth communication between the nodes training each model. At inference, a lightweight router directs a given sequence to a single expert, according to a short prefix. This inference scheme naturally uses a fraction of the parameters from the overall mixture model. Our experiments on language modeling demonstrate tha SmallTalk LM achieves significantly lower perplexity than dense model baselines for the same total training FLOPs and an almost identical inference cost. Finally, in our downstream evaluations we outperform the dense baseline on $75\%$ of the tasks.