 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Knowledge Transfer under Data Constraints via Lexical Interventions
May 22, 2026Cross-lingual knowledge transfer is critical for building high-performing multilingual language models for languages with insufficient training data. When target language data is scarce, the knowledge required for many downstream tasks involving scientific reasoning, commonsense inference, and world knowledge must be acquired primarily from the high-resource language, making effective knowledge transfer essential. Existing methods for improving such cross-lingual knowledge transfer require large amounts of parallel data, translation systems, auxiliary models, or additional training stages that are largely unavailable for many languages. We propose LINK - a data-level intervention method that improves knowledge transfer during model pretraining through lexical substitutions in high-resource part of pretraining data using bilingual vocabularies. For a given replacement ratio, randomly selected words in a portion of the high-resource (English) training corpus are swapped with their word-level translations, requiring no additional model training and only a bilingual vocabulary, which can be obtained at near-zero cost for virtually any language. Evaluation on eight languages across five model sizes shows notable improvements on downstream tasks in the target language, with up to a 2x speedup in training to reach equivalent performance.
Assessing the Role of Data Quality in Training Bilingual Language Models
Jun 15, 2025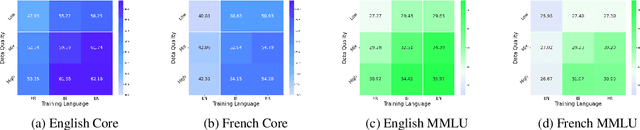
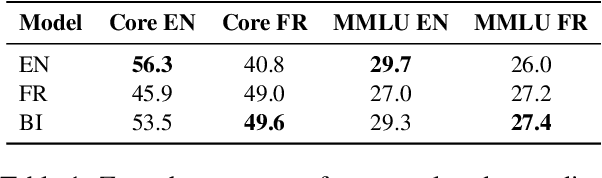
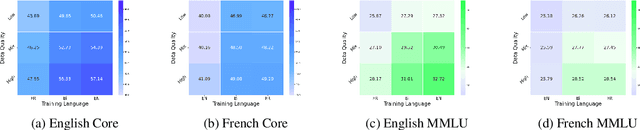
Bilingual and multilingual language models offer a promising path toward scaling NLP systems across diverse languages and users. However, their performance often varies wildly between languages as prior works show that adding more languages can degrade performance for some languages (such as English), while improving others (typically more data constrained languages). In this work, we investigate causes of these inconsistencies by comparing bilingual and monolingual language models. Our analysis reveals that unequal data quality, not just data quantity, is a major driver of performance degradation in bilingual settings. We propose a simple yet effective data filtering strategy to select higher-quality bilingual training data with only high quality English data. Applied to French, German, and Chinese, our approach improves monolingual performance by 2-4% and reduces bilingual model performance gaps to 1%. These results highlight the overlooked importance of data quality in multilingual pretraining and offer a practical recipe for balancing performance.
Discriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks
May 23, 2025We introduce a set of training-free ABX-style discrimination tasks to evaluate how multilingual language models represent language identity (form) and semantic content (meaning). Inspired from speech processing, these zero-shot tasks measure whether minimal differences in representation can be reliably detected. This offers a flexible and interpretable alternative to probing. Applied to XLM-R (Conneau et al, 2020) across pretraining checkpoints and layers, we find that language discrimination declines over training and becomes concentrated in lower layers, while meaning discrimination strengthens over time and stabilizes in deeper layers. We then explore probing tasks, showing some alignment between our metrics and linguistic learning performance. Our results position ABX tasks as a lightweight framework for analyzing the structure of multilingual representations.
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
Jan 24, 2025Cross-lingual transfer is a popular approach to increase the amount of training data for NLP tasks in a low-resource context. However, the best strategy to decide which cross-lingual data to include is unclear. Prior research often focuses on a small set of languages from a few language families and/or a single task. It is still an open question how these findings extend to a wider variety of languages and tasks. In this work, we analyze cross-lingual transfer for 266 languages from a wide variety of language families. Moreover, we include three popular NLP tasks: POS tagging, dependency parsing, and topic classification. Our findings indicate that the effect of linguistic similarity on transfer performance depends on a range of factors: the NLP task, the (mono- or multilingual) input representations, and the definition of linguistic similarity.
On the Way to LLM Personalization: Learning to Remember User Conversations
Nov 20, 2024



Large Language Models (LLMs) have quickly become an invaluable assistant for a variety of tasks. However, their effectiveness is constrained by their ability to tailor responses to human preferences and behaviors via personalization. Prior work in LLM personalization has largely focused on style transfer or incorporating small factoids about the user, as knowledge injection remains an open challenge. In this paper, we explore injecting knowledge of prior conversations into LLMs to enable future work on less redundant, personalized conversations. We identify two real-world constraints: (1) conversations are sequential in time and must be treated as such during training, and (2) per-user personalization is only viable in parameter-efficient settings. To this aim, we propose PLUM, a pipeline performing data augmentation for up-sampling conversations as question-answer pairs, that are then used to finetune a low-rank adaptation adapter with a weighted cross entropy loss. Even in this first exploration of the problem, we perform competitively with baselines such as RAG, attaining an accuracy of 81.5% across 100 conversations.
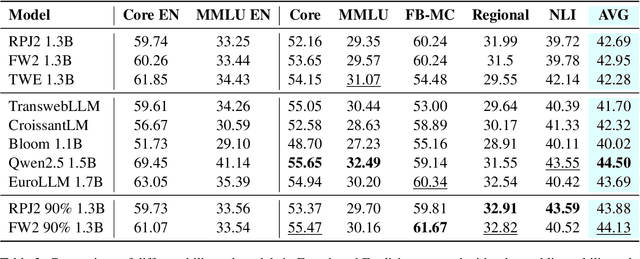
Training Bilingual LMs with Data Constraints in the Targeted Language
Nov 20, 2024



Large language models are trained on massive scrapes of the web, as required by current scaling laws. Most progress is made for English, given its abundance of high-quality pretraining data. For most other languages, however, such high quality pretraining data is unavailable. In this work, we study how to boost pretrained model performance in a data constrained target language by enlisting data from an auxiliary language for which high quality data is available. We study this by quantifying the performance gap between training with data in a data-rich auxiliary language compared with training in the target language, exploring the benefits of translation systems, studying the limitations of model scaling for data constrained languages, and proposing new methods for upsampling data from the auxiliary language. Our results show that stronger auxiliary datasets result in performance gains without modification to the model or training objective for close languages, and, in particular, that performance gains due to the development of more information-rich English pretraining datasets can extend to targeted language settings with limited data.
GrammaMT: Improving Machine Translation with Grammar-Informed In-Context Learning
Oct 24, 2024We introduce GrammaMT, a grammatically-aware prompting approach for machine translation that uses Interlinear Glossed Text (IGT), a common form of linguistic description providing morphological and lexical annotations for source sentences. GrammaMT proposes three prompting strategies: gloss-shot, chain-gloss and model-gloss. All are training-free, requiring only a few examples that involve minimal effort to collect, and making them well-suited for low-resource setups. Experiments show that GrammaMT enhances translation performance on open-source instruction-tuned LLMs for various low- to high-resource languages across three benchmarks: (1) the largest IGT corpus, (2) the challenging 2023 SIGMORPHON Shared Task data over endangered languages, and (3) even in an out-of-domain setting with FLORES. Moreover, ablation studies reveal that leveraging gloss resources could substantially boost MT performance (by over 17 BLEU points) if LLMs accurately generate or access input sentence glosses.
On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
Sep 05, 2024



Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an EXplicit Reward Model (EXRM) as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown that the implicit reward model of DPO (denoted as DPORM) can approximate an EXRM in the limit. DPORM's effectiveness directly implies the optimality of the learned policy, and also has practical implication for LLM alignment methods including iterative DPO. However, it is unclear how well DPORM empirically matches the performance of EXRM. This work studies the accuracy at distinguishing preferred and rejected answers for both DPORM and EXRM. Our findings indicate that even though DPORM fits the training dataset comparably, it generalizes less effectively than EXRM, especially when the validation datasets contain distribution shifts. Across five out-of-distribution settings, DPORM has a mean drop in accuracy of 3% and a maximum drop of 7%. These findings highlight that DPORM has limited generalization ability and substantiates the integration of an explicit reward model in iterative DPO approaches.
High-Resource Methodological Bias in Low-Resource Investigations
Nov 14, 2022The central bottleneck for low-resource NLP is typically regarded to be the quantity of accessible data, overlooking the contribution of data quality. This is particularly seen in the development and evaluation of low-resource systems via down sampling of high-resource language data. In this work we investigate the validity of this approach, and we specifically focus on two well-known NLP tasks for our empirical investigations: POS-tagging and machine translation. We show that down sampling from a high-resource language results in datasets with different properties than the low-resource datasets, impacting the model performance for both POS-tagging and machine translation. Based on these results we conclude that naive down sampling of datasets results in a biased view of how well these systems work in a low-resource scenario.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.