 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandard-to-Dialect Transfer Trends Differ across Text and Speech: A Case Study on Intent and Topic Classification in German Dialects
Oct 09, 2025

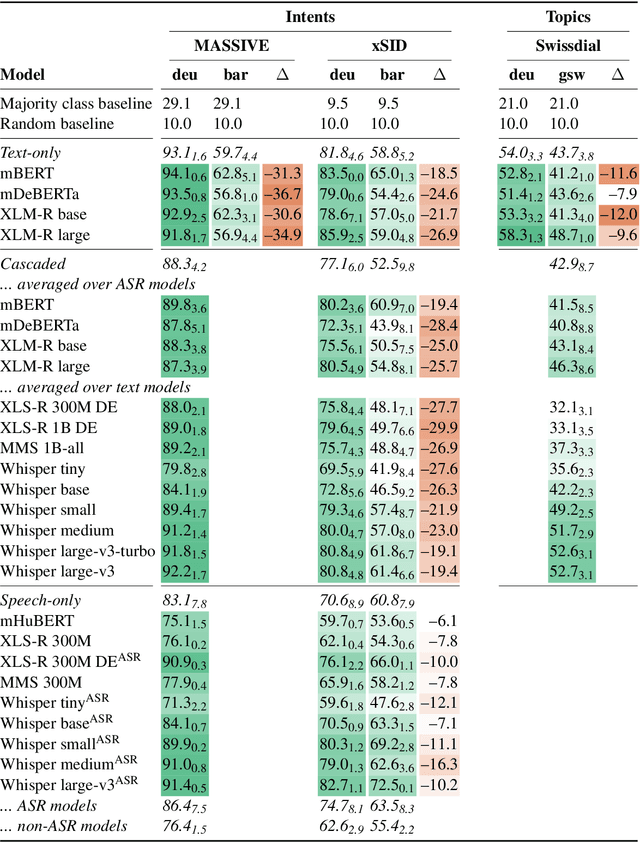

Research on cross-dialectal transfer from a standard to a non-standard dialect variety has typically focused on text data. However, dialects are primarily spoken, and non-standard spellings are known to cause issues in text processing. We compare standard-to-dialect transfer in three settings: text models, speech models, and cascaded systems where speech first gets automatically transcribed and then further processed by a text model. In our experiments, we focus on German and multiple German dialects in the context of written and spoken intent and topic classification. To that end, we release the first dialectal audio intent classification dataset. We find that the speech-only setup provides the best results on the dialect data while the text-only setup works best on the standard data. While the cascaded systems lag behind the text-only models for German, they perform relatively well on the dialectal data if the transcription system generates normalized, standard-like output.
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
Jan 24, 2025Cross-lingual transfer is a popular approach to increase the amount of training data for NLP tasks in a low-resource context. However, the best strategy to decide which cross-lingual data to include is unclear. Prior research often focuses on a small set of languages from a few language families and/or a single task. It is still an open question how these findings extend to a wider variety of languages and tasks. In this work, we analyze cross-lingual transfer for 266 languages from a wide variety of language families. Moreover, we include three popular NLP tasks: POS tagging, dependency parsing, and topic classification. Our findings indicate that the effect of linguistic similarity on transfer performance depends on a range of factors: the NLP task, the (mono- or multilingual) input representations, and the definition of linguistic similarity.
Improving Dialectal Slot and Intent Detection with Auxiliary Tasks: A Multi-Dialectal Bavarian Case Study
Jan 07, 2025



Reliable slot and intent detection (SID) is crucial in natural language understanding for applications like digital assistants. Encoder-only transformer models fine-tuned on high-resource languages generally perform well on SID. However, they struggle with dialectal data, where no standardized form exists and training data is scarce and costly to produce. We explore zero-shot transfer learning for SID, focusing on multiple Bavarian dialects, for which we release a new dataset for the Munich dialect. We evaluate models trained on auxiliary tasks in Bavarian, and compare joint multi-task learning with intermediate-task training. We also compare three types of auxiliary tasks: token-level syntactic tasks, named entity recognition (NER), and language modelling. We find that the included auxiliary tasks have a more positive effect on slot filling than intent classification (with NER having the most positive effect), and that intermediate-task training yields more consistent performance gains. Our best-performing approach improves intent classification performance on Bavarian dialects by 5.1 and slot filling F1 by 8.4 percentage points.
Add Noise, Tasks, or Layers? MaiNLP at the VarDial 2025 Shared Task on Norwegian Dialectal Slot and Intent Detection
Jan 07, 2025



Slot and intent detection (SID) is a classic natural language understanding task. Despite this, research has only more recently begun focusing on SID for dialectal and colloquial varieties. Many approaches for low-resource scenarios have not yet been applied to dialectal SID data, or compared to each other on the same datasets. We participate in the VarDial 2025 shared task on slot and intent detection in Norwegian varieties, and compare multiple set-ups: varying the training data (English, Norwegian, or dialectal Norwegian), injecting character-level noise, training on auxiliary tasks, and applying Layer Swapping, a technique in which layers of models fine-tuned on different datasets are assembled into a model. We find noise injection to be beneficial while the effects of auxiliary tasks are mixed. Though some experimentation was required to successfully assemble a model from layers, it worked surprisingly well; a combination of models trained on English and small amounts of dialectal data produced the most robust slot predictions. Our best models achieve 97.6% intent accuracy and 85.6% slot F1 in the shared task.
Cross-Dialect Information Retrieval: Information Access in Low-Resource and High-Variance Languages
Dec 17, 2024



A large amount of local and culture-specific knowledge (e.g., people, traditions, food) can only be found in documents written in dialects. While there has been extensive research conducted on cross-lingual information retrieval (CLIR), the field of cross-dialect retrieval (CDIR) has received limited attention. Dialect retrieval poses unique challenges due to the limited availability of resources to train retrieval models and the high variability in non-standardized languages. We study these challenges on the example of German dialects and introduce the first German dialect retrieval dataset, dubbed WikiDIR, which consists of seven German dialects extracted from Wikipedia. Using WikiDIR, we demonstrate the weakness of lexical methods in dealing with high lexical variation in dialects. We further show that commonly used zero-shot cross-lingual transfer approach with multilingual encoders do not transfer well to extremely low-resource setups, motivating the need for resource-lean and dialect-specific retrieval models. We finally demonstrate that (document) translation is an effective way to reduce the dialect gap in CDIR.
Evaluating Pixel Language Models on Non-Standardized Languages
Dec 12, 2024
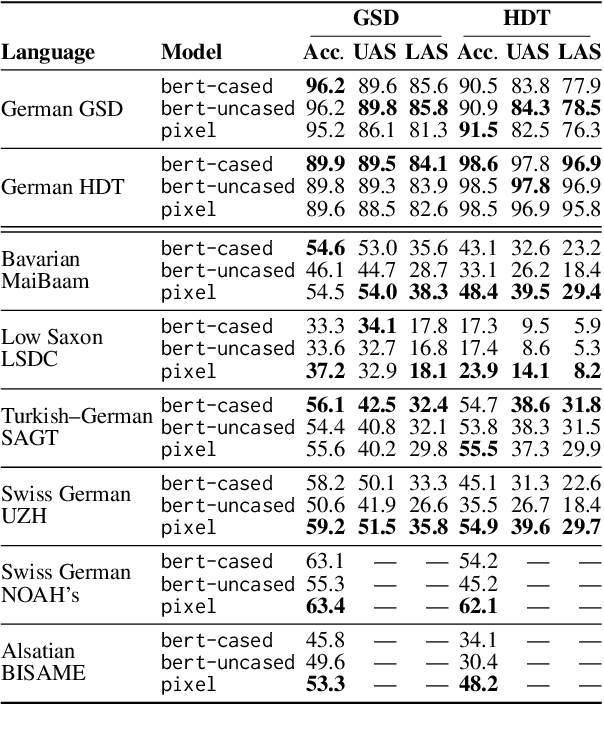

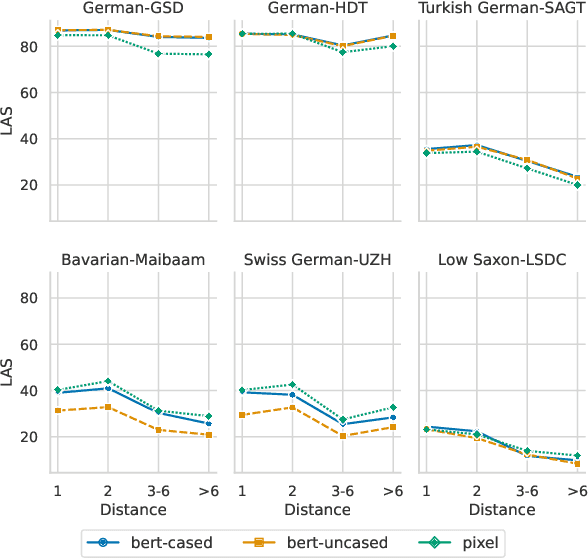
We explore the potential of pixel-based models for transfer learning from standard languages to dialects. These models convert text into images that are divided into patches, enabling a continuous vocabulary representation that proves especially useful for out-of-vocabulary words common in dialectal data. Using German as a case study, we compare the performance of pixel-based models to token-based models across various syntactic and semantic tasks. Our results show that pixel-based models outperform token-based models in part-of-speech tagging, dependency parsing and intent detection for zero-shot dialect evaluation by up to 26 percentage points in some scenarios, though not in Standard German. However, pixel-based models fall short in topic classification. These findings emphasize the potential of pixel-based models for handling dialectal data, though further research should be conducted to assess their effectiveness in various linguistic contexts.
Sebastian, Basti, Wastl?! Recognizing Named Entities in Bavarian Dialectal Data
Mar 19, 2024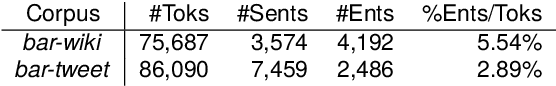



Named Entity Recognition (NER) is a fundamental task to extract key information from texts, but annotated resources are scarce for dialects. This paper introduces the first dialectal NER dataset for German, BarNER, with 161K tokens annotated on Bavarian Wikipedia articles (bar-wiki) and tweets (bar-tweet), using a schema adapted from German CoNLL 2006 and GermEval. The Bavarian dialect differs from standard German in lexical distribution, syntactic construction, and entity information. We conduct in-domain, cross-domain, sequential, and joint experiments on two Bavarian and three German corpora and present the first comprehensive NER results on Bavarian. Incorporating knowledge from the larger German NER (sub-)datasets notably improves on bar-wiki and moderately on bar-tweet. Inversely, training first on Bavarian contributes slightly to the seminal German CoNLL 2006 corpus. Moreover, with gold dialect labels on Bavarian tweets, we assess multi-task learning between five NER and two Bavarian-German dialect identification tasks and achieve NER SOTA on bar-wiki. We substantiate the necessity of our low-resource BarNER corpus and the importance of diversity in dialects, genres, and topics in enhancing model performance.
MaiBaam: A Multi-Dialectal Bavarian Universal Dependency Treebank
Mar 15, 2024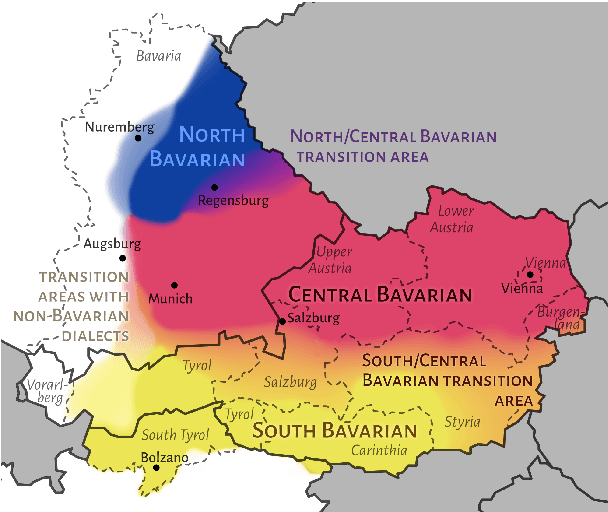
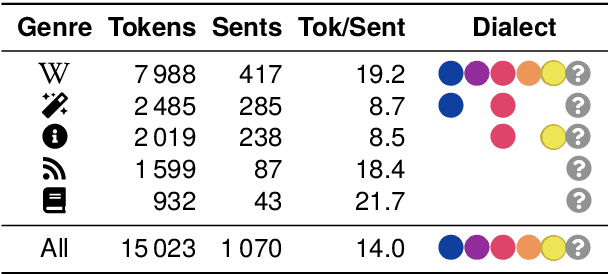
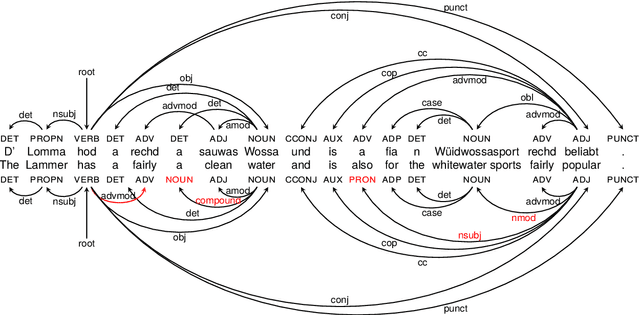
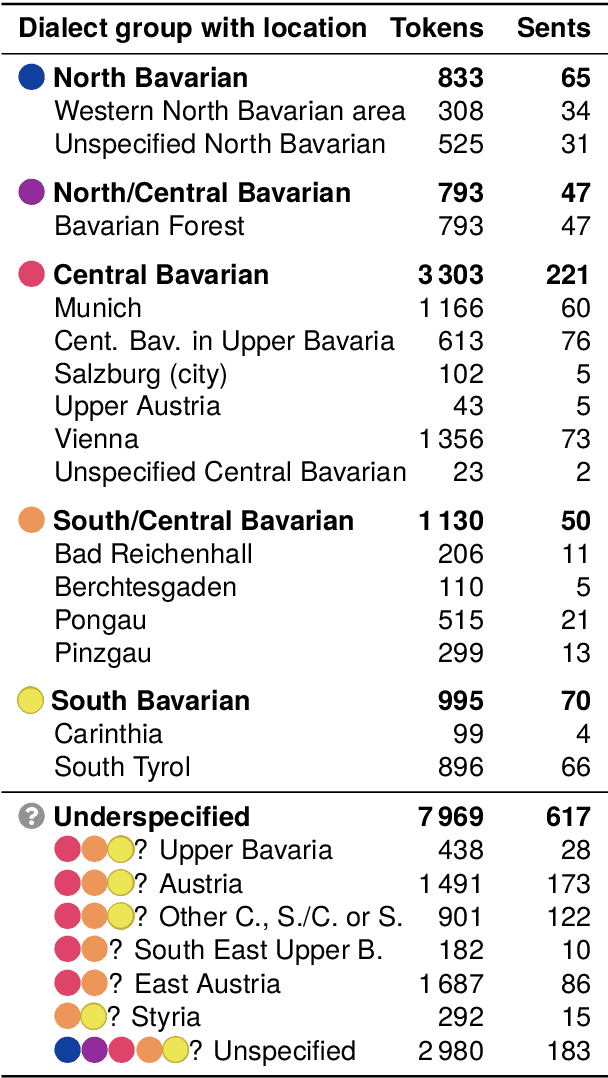
Despite the success of the Universal Dependencies (UD) project exemplified by its impressive language breadth, there is still a lack in `within-language breadth': most treebanks focus on standard languages. Even for German, the language with the most annotations in UD, so far no treebank exists for one of its language varieties spoken by over 10M people: Bavarian. To contribute to closing this gap, we present the first multi-dialect Bavarian treebank (MaiBaam) manually annotated with part-of-speech and syntactic dependency information in UD, covering multiple text genres (wiki, fiction, grammar examples, social, non-fiction). We highlight the morphosyntactic differences between the closely-related Bavarian and German and showcase the rich variability of speakers' orthographies. Our corpus includes 15k tokens, covering dialects from all Bavarian-speaking areas spanning three countries. We provide baseline parsing and POS tagging results, which are lower than results obtained on German and vary substantially between different graph-based parsers. To support further research on Bavarian syntax, we make our dataset, language-specific guidelines and code publicly available.
MaiBaam Annotation Guidelines
Mar 09, 2024This document provides the annotation guidelines for MaiBaam, a Bavarian corpus annotated with part-of-speech (POS) tags and syntactic dependencies. MaiBaam belongs to the Universal Dependencies (UD) project, and our annotations elaborate on the general and German UD version 2 guidelines. In this document, we detail how to preprocess and tokenize Bavarian data, provide an overview of the POS tags and dependencies we use, explain annotation decisions that would also apply to closely related languages like German, and lastly we introduce and motivate decisions that are specific to Bavarian grammar.
What Do Dialect Speakers Want? A Survey of Attitudes Towards Language Technology for German Dialects
Feb 19, 2024



Natural language processing (NLP) has largely focused on modelling standardized languages. More recently, attention has increasingly shifted to local, non-standardized languages and dialects. However, the relevant speaker populations' needs and wishes with respect to NLP tools are largely unknown. In this paper, we focus on dialects and regional languages related to German -- a group of varieties that is heterogeneous in terms of prestige and standardization. We survey speakers of these varieties (N=327) and present their opinions on hypothetical language technologies for their dialects. Although attitudes vary among subgroups of our respondents, we find that respondents are especially in favour of potential NLP tools that work with dialectal input (especially audio input) such as virtual assistants, and less so for applications that produce dialectal output such as machine translation or spellcheckers.