 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeltzGLUE: Luxembourgish General Language Understanding Evaluation
Apr 20, 2026This paper presents ltzGLUE, the first Natural Language Understanding (NLU) benchmark for Luxembourgish (LTZ) based on the popular GLUE benchmark for English. Although NLU tasks are available for many European languages nowadays, LTZ is one of the official national languages that is often overlooked. We construct new tasks and reuse existing ones to introduce the first official NLU benchmark and accompanying evaluation of encoder models for the language. Our tasks include common natural language processing tasks in binary and multi-class classification settings, including named entity recognition, topic classification, and intent classification. We evaluate various pre-trained language models for LTZ to present an overview of the current capabilities of these models on the LTZ language.
Variation is the Norm: Embracing Sociolinguistics in NLP
Mar 25, 2026In Natural Language Processing (NLP), variation is typically seen as noise and "normalised away" before processing, even though it is an integral part of language. Conversely, studying language variation in social contexts is central to sociolinguistics. We present a framework to combine the sociolinguistic dimension of language with the technical dimension of NLP. We argue that by embracing sociolinguistics, variation can actively be included in a research setup, in turn informing the NLP side. To illustrate this, we provide a case study on Luxembourgish, an evolving language featuring a large amount of orthographic variation, demonstrating how NLP performance is impacted. The results show large discrepancies in the performance of models tested and fine-tuned on data with a large amount of orthographic variation in comparison to data closer to the (orthographic) standard. Furthermore, we provide a possible solution to improve the performance by including variation in the fine-tuning process. This case study highlights the importance of including variation in the research setup, as models are currently not robust to occurring variation. Our framework facilitates the inclusion of variation in the thought-process while also being grounded in the theoretical framework of sociolinguistics.
A Subword Embedding Approach for Variation Detection in Luxembourgish User Comments
Feb 12, 2026This paper presents an embedding-based approach to detecting variation without relying on prior normalisation or predefined variant lists. The method trains subword embeddings on raw text and groups related forms through combined cosine and n-gram similarity. This allows spelling and morphological diversity to be examined and analysed as linguistic structure rather than treated as noise. Using a large corpus of Luxembourgish user comments, the approach uncovers extensive lexical and orthographic variation that aligns with patterns described in dialectal and sociolinguistic research. The induced families capture systematic correspondences and highlight areas of regional and stylistic differentiation. The procedure does not strictly require manual annotation, but does produce transparent clusters that support both quantitative and qualitative analysis. The results demonstrate that distributional modelling can reveal meaningful patterns of variation even in ''noisy'' or low-resource settings, offering a reproducible methodological framework for studying language variety in multilingual and small-language contexts.
Neural Text Normalization for Luxembourgish using Real-Life Variation Data
Dec 13, 2024



Orthographic variation is very common in Luxembourgish texts due to the absence of a fully-fledged standard variety. Additionally, developing NLP tools for Luxembourgish is a difficult task given the lack of annotated and parallel data, which is exacerbated by ongoing standardization. In this paper, we propose the first sequence-to-sequence normalization models using the ByT5 and mT5 architectures with training data obtained from word-level real-life variation data. We perform a fine-grained, linguistically-motivated evaluation to test byte-based, word-based and pipeline-based models for their strengths and weaknesses in text normalization. We show that our sequence model using real-life variation data is an effective approach for tailor-made normalization in Luxembourgish.
Text Generation Models for Luxembourgish with Limited Data: A Balanced Multilingual Strategy
Dec 12, 2024



This paper addresses the challenges in developing language models for less-represented languages, with a focus on Luxembourgish. Despite its active development, Luxembourgish faces a digital data scarcity, exacerbated by Luxembourg's multilingual context. We propose a novel text generation model based on the T5 architecture, combining limited Luxembourgish data with equal amounts, in terms of size and type, of German and French data. We hypothesise that a model trained on Luxembourgish, German, and French will improve the model's cross-lingual transfer learning capabilities and outperform monolingual and large multilingual models. To verify this, the study at hand explores whether multilingual or monolingual training is more beneficial for Luxembourgish language generation. For the evaluation, we introduce LuxGen, a text generation benchmark that is the first of its kind for Luxembourgish.
LuxBank: The First Universal Dependency Treebank for Luxembourgish
Nov 07, 2024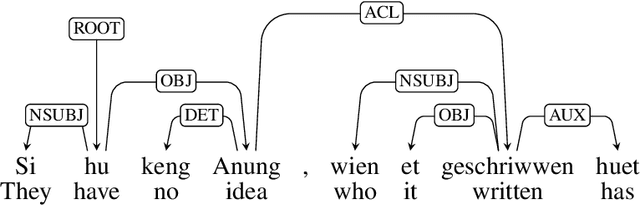
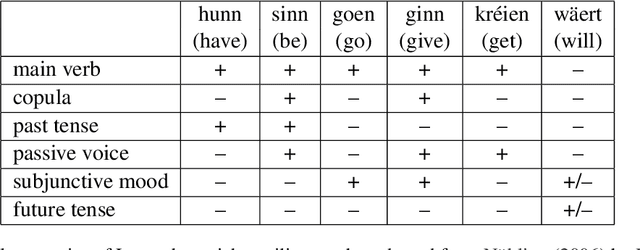
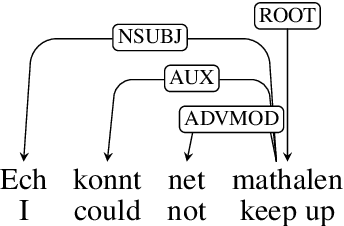

The Universal Dependencies (UD) project has significantly expanded linguistic coverage across 161 languages, yet Luxembourgish, a West Germanic language spoken by approximately 400,000 people, has remained absent until now. In this paper, we introduce LuxBank, the first UD Treebank for Luxembourgish, addressing the gap in syntactic annotation and analysis for this `low-research' language. We establish formal guidelines for Luxembourgish language annotation, providing the foundation for the first large-scale quantitative analysis of its syntax. LuxBank serves not only as a resource for linguists and language learners but also as a tool for developing spell checkers and grammar checkers, organising existing text archives and even training large language models. By incorporating Luxembourgish into the UD framework, we aim to enhance the understanding of syntactic variation within West Germanic languages and offer a model for documenting smaller, semi-standardised languages. This work positions Luxembourgish as a valuable resource in the broader linguistic and NLP communities, contributing to the study of languages with limited research and resources.
Guided Distant Supervision for Multilingual Relation Extraction Data: Adapting to a New Language
Mar 27, 2024



Relation extraction is essential for extracting and understanding biographical information in the context of digital humanities and related subjects. There is a growing interest in the community to build datasets capable of training machine learning models to extract relationships. However, annotating such datasets can be expensive and time-consuming, in addition to being limited to English. This paper applies guided distant supervision to create a large biographical relationship extraction dataset for German. Our dataset, composed of more than 80,000 instances for nine relationship types, is the largest biographical German relationship extraction dataset. We also create a manually annotated dataset with 2000 instances to evaluate the models and release it together with the dataset compiled using guided distant supervision. We train several state-of-the-art machine learning models on the automatically created dataset and release them as well. Furthermore, we experiment with multilingual and cross-lingual experiments that could benefit many low-resource languages.
What Do Dialect Speakers Want? A Survey of Attitudes Towards Language Technology for German Dialects
Feb 19, 2024



Natural language processing (NLP) has largely focused on modelling standardized languages. More recently, attention has increasingly shifted to local, non-standardized languages and dialects. However, the relevant speaker populations' needs and wishes with respect to NLP tools are largely unknown. In this paper, we focus on dialects and regional languages related to German -- a group of varieties that is heterogeneous in terms of prestige and standardization. We survey speakers of these varieties (N=327) and present their opinions on hypothetical language technologies for their dialects. Although attitudes vary among subgroups of our respondents, we find that respondents are especially in favour of potential NLP tools that work with dialectal input (especially audio input) such as virtual assistants, and less so for applications that produce dialectal output such as machine translation or spellcheckers.