 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeltzGLUE: Luxembourgish General Language Understanding Evaluation
Apr 20, 2026This paper presents ltzGLUE, the first Natural Language Understanding (NLU) benchmark for Luxembourgish (LTZ) based on the popular GLUE benchmark for English. Although NLU tasks are available for many European languages nowadays, LTZ is one of the official national languages that is often overlooked. We construct new tasks and reuse existing ones to introduce the first official NLU benchmark and accompanying evaluation of encoder models for the language. Our tasks include common natural language processing tasks in binary and multi-class classification settings, including named entity recognition, topic classification, and intent classification. We evaluate various pre-trained language models for LTZ to present an overview of the current capabilities of these models on the LTZ language.
MUNIChus: Multilingual News Image Captioning Benchmark
Mar 11, 2026The goal of news image captioning is to generate captions by integrating news article content with corresponding images, highlighting the relationship between textual context and visual elements. The majority of research on news image captioning focuses on English, primarily because datasets in other languages are scarce. To address this limitation, we create the first multilingual news image captioning benchmark, MUNIChus, comprising 9 languages, including several low-resource languages such as Sinhala and Urdu. We evaluate various state-of-the-art neural news image captioning models on MUNIChus and find that news image captioning remains challenging. We also make MUNIChus publicly available with over 20 models already benchmarked. MUNIChus opens new avenues for further advancements in developing and evaluating multilingual news image captioning models.
Exploring the Performance of Large Language Models on Subjective Span Identification Tasks
Jan 02, 2026Identifying relevant text spans is important for several downstream tasks in NLP, as it contributes to model explainability. While most span identification approaches rely on relatively smaller pre-trained language models like BERT, a few recent approaches have leveraged the latest generation of Large Language Models (LLMs) for the task. Current work has focused on explicit span identification like Named Entity Recognition (NER), while more subjective span identification with LLMs in tasks like Aspect-based Sentiment Analysis (ABSA) has been underexplored. In this paper, we fill this important gap by presenting an evaluation of the performance of various LLMs on text span identification in three popular tasks, namely sentiment analysis, offensive language identification, and claim verification. We explore several LLM strategies like instruction tuning, in-context learning, and chain of thought. Our results indicate underlying relationships within text aid LLMs in identifying precise text spans.
Do LLMs Judge Distantly Supervised Named Entity Labels Well? Constructing the JudgeWEL Dataset
Jan 01, 2026We present judgeWEL, a dataset for named entity recognition (NER) in Luxembourgish, automatically labelled and subsequently verified using large language models (LLM) in a novel pipeline. Building datasets for under-represented languages remains one of the major bottlenecks in natural language processing, where the scarcity of resources and linguistic particularities make large-scale annotation costly and potentially inconsistent. To address these challenges, we propose and evaluate a novel approach that leverages Wikipedia and Wikidata as structured sources of weak supervision. By exploiting internal links within Wikipedia articles, we infer entity types based on their corresponding Wikidata entries, thereby generating initial annotations with minimal human intervention. Because such links are not uniformly reliable, we mitigate noise by employing and comparing several LLMs to identify and retain only high-quality labelled sentences. The resulting corpus is approximately five times larger than the currently available Luxembourgish NER dataset and offers broader and more balanced coverage across entity categories, providing a substantial new resource for multilingual and low-resource NER research.
AHaSIS: Shared Task on Sentiment Analysis for Arabic Dialects
Nov 17, 2025The hospitality industry in the Arab world increasingly relies on customer feedback to shape services, driving the need for advanced Arabic sentiment analysis tools. To address this challenge, the Sentiment Analysis on Arabic Dialects in the Hospitality Domain shared task focuses on Sentiment Detection in Arabic Dialects. This task leverages a multi-dialect, manually curated dataset derived from hotel reviews originally written in Modern Standard Arabic (MSA) and translated into Saudi and Moroccan (Darija) dialects. The dataset consists of 538 sentiment-balanced reviews spanning positive, neutral, and negative categories. Translations were validated by native speakers to ensure dialectal accuracy and sentiment preservation. This resource supports the development of dialect-aware NLP systems for real-world applications in customer experience analysis. More than 40 teams have registered for the shared task, with 12 submitting systems during the evaluation phase. The top-performing system achieved an F1 score of 0.81, demonstrating the feasibility and ongoing challenges of sentiment analysis across Arabic dialects.
A Survey on Multilingual Mental Disorders Detection from Social Media Data
May 21, 2025The increasing prevalence of mental health disorders globally highlights the urgent need for effective digital screening methods that can be used in multilingual contexts. Most existing studies, however, focus on English data, overlooking critical mental health signals that may be present in non-English texts. To address this important gap, we present the first survey on the detection of mental health disorders using multilingual social media data. We investigate the cultural nuances that influence online language patterns and self-disclosure behaviors, and how these factors can impact the performance of NLP tools. Additionally, we provide a comprehensive list of multilingual data collections that can be used for developing NLP models for mental health screening. Our findings can inform the design of effective multilingual mental health screening tools that can meet the needs of diverse populations, ultimately improving mental health outcomes on a global scale.
Overview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
Text Generation Models for Luxembourgish with Limited Data: A Balanced Multilingual Strategy
Dec 12, 2024



This paper addresses the challenges in developing language models for less-represented languages, with a focus on Luxembourgish. Despite its active development, Luxembourgish faces a digital data scarcity, exacerbated by Luxembourg's multilingual context. We propose a novel text generation model based on the T5 architecture, combining limited Luxembourgish data with equal amounts, in terms of size and type, of German and French data. We hypothesise that a model trained on Luxembourgish, German, and French will improve the model's cross-lingual transfer learning capabilities and outperform monolingual and large multilingual models. To verify this, the study at hand explores whether multilingual or monolingual training is more beneficial for Luxembourgish language generation. For the evaluation, we introduce LuxGen, a text generation benchmark that is the first of its kind for Luxembourgish.
A Survey of Multimodal Sarcasm Detection
Oct 24, 2024



Sarcasm is a rhetorical device that is used to convey the opposite of the literal meaning of an utterance. Sarcasm is widely used on social media and other forms of computer-mediated communication motivating the use of computational models to identify it automatically. While the clear majority of approaches to sarcasm detection have been carried out on text only, sarcasm detection often requires additional information present in tonality, facial expression, and contextual images. This has led to the introduction of multimodal models, opening the possibility to detect sarcasm in multiple modalities such as audio, images, text, and video. In this paper, we present the first comprehensive survey on multimodal sarcasm detection - henceforth MSD - to date. We survey papers published between 2018 and 2023 on the topic, and discuss the models and datasets used for this task. We also present future research directions in MSD.
What do Large Language Models Need for Machine Translation Evaluation?
Oct 04, 2024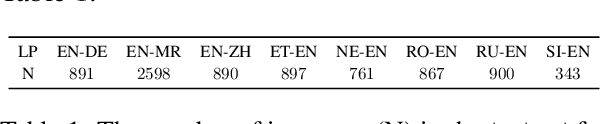
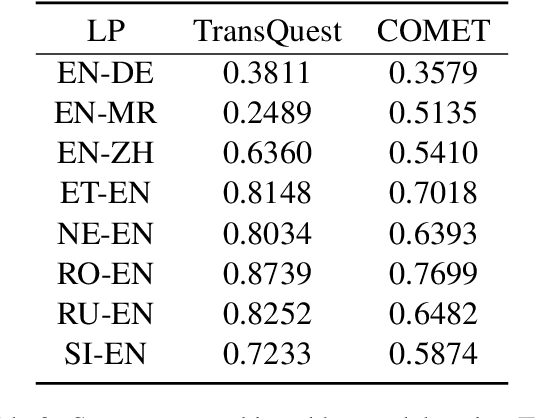
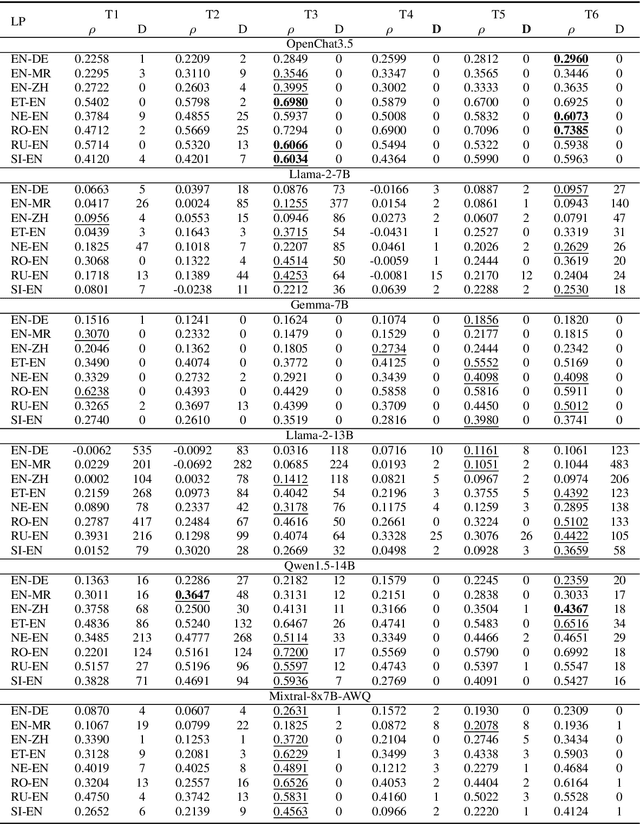
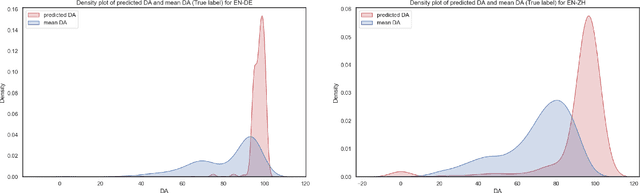
Leveraging large language models (LLMs) for various natural language processing tasks has led to superlative claims about their performance. For the evaluation of machine translation (MT), existing research shows that LLMs are able to achieve results comparable to fine-tuned multilingual pre-trained language models. In this paper, we explore what translation information, such as the source, reference, translation errors and annotation guidelines, is needed for LLMs to evaluate MT quality. In addition, we investigate prompting techniques such as zero-shot, Chain of Thought (CoT) and few-shot prompting for eight language pairs covering high-, medium- and low-resource languages, leveraging varying LLM variants. Our findings indicate the importance of reference translations for an LLM-based evaluation. While larger models do not necessarily fare better, they tend to benefit more from CoT prompting, than smaller models. We also observe that LLMs do not always provide a numerical score when generating evaluations, which poses a question on their reliability for the task. Our work presents a comprehensive analysis for resource-constrained and training-less LLM-based evaluation of machine translation. We release the accrued prompt templates, code and data publicly for reproducibility.