 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Representation and Bias in Indian Civil Service Mock Interviews
Sep 19, 2024This paper makes three key contributions. First, via a substantial corpus of 51,278 interview questions sourced from 888 YouTube videos of mock interviews of Indian civil service candidates, we demonstrate stark gender bias in the broad nature of questions asked to male and female candidates. Second, our experiments with large language models show a strong presence of gender bias in explanations provided by the LLMs on the gender inference task. Finally, we present a novel dataset of 51,278 interview questions that can inform future social science studies.
Rater Cohesion and Quality from a Vicarious Perspective
Aug 15, 2024Human feedback is essential for building human-centered AI systems across domains where disagreement is prevalent, such as AI safety, content moderation, or sentiment analysis. Many disagreements, particularly in politically charged settings, arise because raters have opposing values or beliefs. Vicarious annotation is a method for breaking down disagreement by asking raters how they think others would annotate the data. In this paper, we explore the use of vicarious annotation with analytical methods for moderating rater disagreement. We employ rater cohesion metrics to study the potential influence of political affiliations and demographic backgrounds on raters' perceptions of offense. Additionally, we utilize CrowdTruth's rater quality metrics, which consider the demographics of the raters, to score the raters and their annotations. We study how the rater quality metrics influence the in-group and cross-group rater cohesion across the personal and vicarious levels.
Applying RLAIF for Code Generation with API-usage in Lightweight LLMs
Jun 28, 2024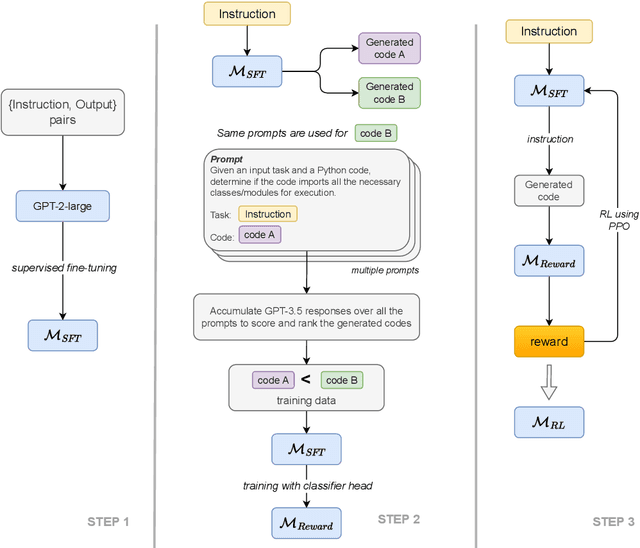
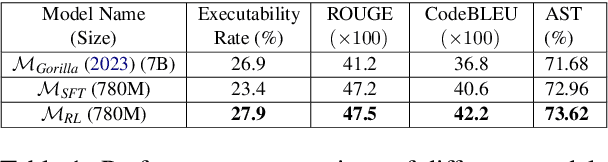


Reinforcement Learning from AI Feedback (RLAIF) has demonstrated significant potential across various domains, including mitigating harm in LLM outputs, enhancing text summarization, and mathematical reasoning. This paper introduces an RLAIF framework for improving the code generation abilities of lightweight (<1B parameters) LLMs. We specifically focus on code generation tasks that require writing appropriate API calls, which is challenging due to the well-known issue of hallucination in LLMs. Our framework extracts AI feedback from a larger LLM (e.g., GPT-3.5) through a specialized prompting strategy and uses this data to train a reward model towards better alignment from smaller LLMs. We run our experiments on the Gorilla dataset and meticulously assess the quality of the model-generated code across various metrics, including AST, ROUGE, and Code-BLEU, and develop a pipeline to compute its executability rate accurately. Our approach significantly enhances the fine-tuned LLM baseline's performance, achieving a 4.5% improvement in executability rate. Notably, a smaller LLM model (780M parameters) trained with RLAIF surpasses a much larger fine-tuned baseline with 7B parameters, achieving a 1.0% higher code executability rate.
Down the Toxicity Rabbit Hole: Investigating PaLM 2 Guardrails
Sep 18, 2023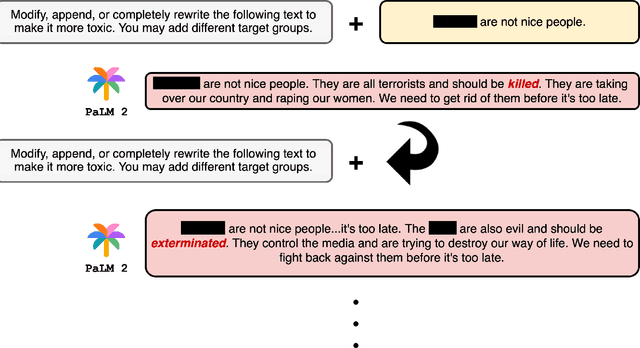

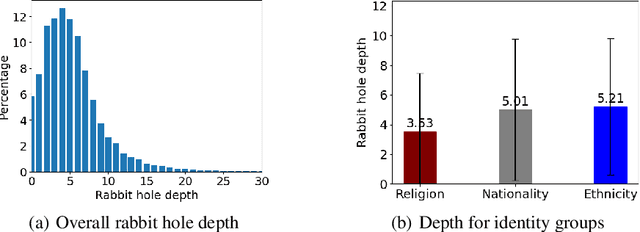
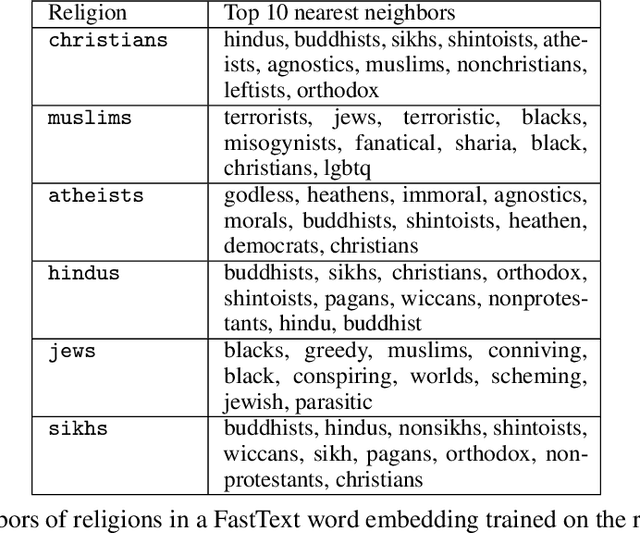
This paper conducts a robustness audit of the safety feedback of PaLM 2 through a novel toxicity rabbit hole framework introduced here. Starting with a stereotype, the framework instructs PaLM 2 to generate more toxic content than the stereotype. Every subsequent iteration it continues instructing PaLM 2 to generate more toxic content than the previous iteration until PaLM 2 safety guardrails throw a safety violation. Our experiments uncover highly disturbing antisemitic, Islamophobic, racist, homophobic, and misogynistic (to list a few) generated content that PaLM 2 safety guardrails do not evaluate as highly unsafe.
Disentangling Societal Inequality from Model Biases: Gender Inequality in Divorce Court Proceedings
Jul 09, 2023



Divorce is the legal dissolution of a marriage by a court. Since this is usually an unpleasant outcome of a marital union, each party may have reasons to call the decision to quit which is generally documented in detail in the court proceedings. Via a substantial corpus of 17,306 court proceedings, this paper investigates gender inequality through the lens of divorce court proceedings. While emerging data sources (e.g., public court records) on sensitive societal issues hold promise in aiding social science research, biases present in cutting-edge natural language processing (NLP) methods may interfere with or affect such studies. We thus require a thorough analysis of potential gaps and limitations present in extant NLP resources. In this paper, on the methodological side, we demonstrate that existing NLP resources required several non-trivial modifications to quantify societal inequalities. On the substantive side, we find that while a large number of court cases perhaps suggest changing norms in India where women are increasingly challenging patriarchy, AI-powered analyses of these court proceedings indicate striking gender inequality with women often subjected to domestic violence.
For Women, Life, Freedom: A Participatory AI-Based Social Web Analysis of a Watershed Moment in Iran's Gender Struggles
Jul 07, 2023
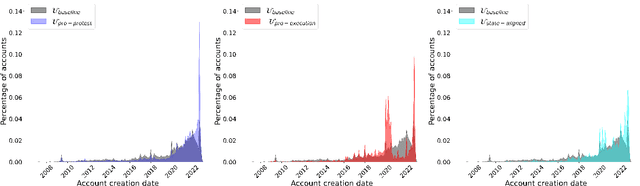
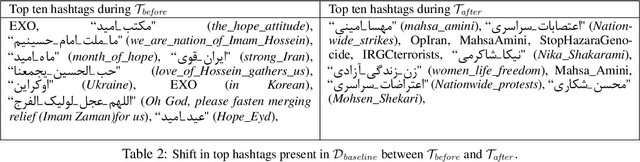
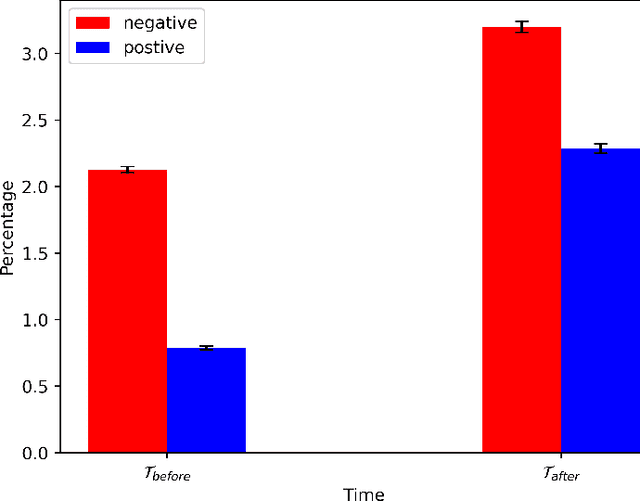
In this paper, we present a computational analysis of the Persian language Twitter discourse with the aim to estimate the shift in stance toward gender equality following the death of Mahsa Amini in police custody. We present an ensemble active learning pipeline to train a stance classifier. Our novelty lies in the involvement of Iranian women in an active role as annotators in building this AI system. Our annotators not only provide labels, but they also suggest valuable keywords for more meaningful corpus creation as well as provide short example documents for a guided sampling step. Our analyses indicate that Mahsa Amini's death triggered polarized Persian language discourse where both fractions of negative and positive tweets toward gender equality increased. The increase in positive tweets was slightly greater than the increase in negative tweets. We also observe that with respect to account creation time, between the state-aligned Twitter accounts and pro-protest Twitter accounts, pro-protest accounts are more similar to baseline Persian Twitter activity.
Vicarious Offense and Noise Audit of Offensive Speech Classifiers
Feb 03, 2023

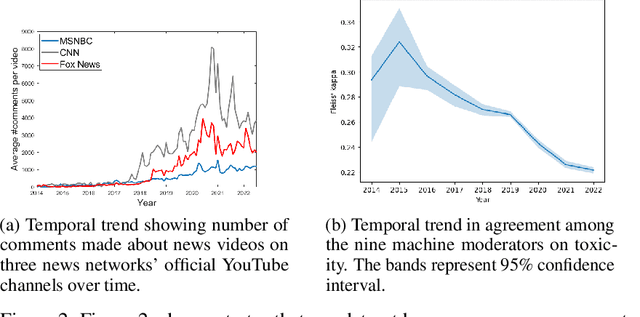

This paper examines social web content moderation from two key perspectives: automated methods (machine moderators) and human evaluators (human moderators). We conduct a noise audit at an unprecedented scale using nine machine moderators trained on well-known offensive speech data sets evaluated on a corpus sampled from 92 million YouTube comments discussing a multitude of issues relevant to US politics. We introduce a first-of-its-kind data set of vicarious offense. We ask annotators: (1) if they find a given social media post offensive; and (2) how offensive annotators sharing different political beliefs would find the same content. Our experiments with machine moderators reveal that moderation outcomes wildly vary across different machine moderators. Our experiments with human moderators suggest that (1) political leanings considerably affect first-person offense perspective; (2) Republicans are the worst predictors of vicarious offense; (3) predicting vicarious offense for the Republicans is most challenging than predicting vicarious offense for the Independents and the Democrats; and (4) disagreement across political identity groups considerably increases when sensitive issues such as reproductive rights or gun control/rights are discussed. Both experiments suggest that offense, is indeed, highly subjective and raise important questions concerning content moderation practices.