 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
A Federated Learning Approach to Privacy Preserving Offensive Language Identification
Apr 17, 2024



The spread of various forms of offensive speech online is an important concern in social media. While platforms have been investing heavily in ways of coping with this problem, the question of privacy remains largely unaddressed. Models trained to detect offensive language on social media are trained and/or fine-tuned using large amounts of data often stored in centralized servers. Since most social media data originates from end users, we propose a privacy preserving decentralized architecture for identifying offensive language online by introducing Federated Learning (FL) in the context of offensive language identification. FL is a decentralized architecture that allows multiple models to be trained locally without the need for data sharing hence preserving users' privacy. We propose a model fusion approach to perform FL. We trained multiple deep learning models on four publicly available English benchmark datasets (AHSD, HASOC, HateXplain, OLID) and evaluated their performance in detail. We also present initial cross-lingual experiments in English and Spanish. We show that the proposed model fusion approach outperforms baselines in all the datasets while preserving privacy.
NSINA: A News Corpus for Sinhala
Mar 25, 2024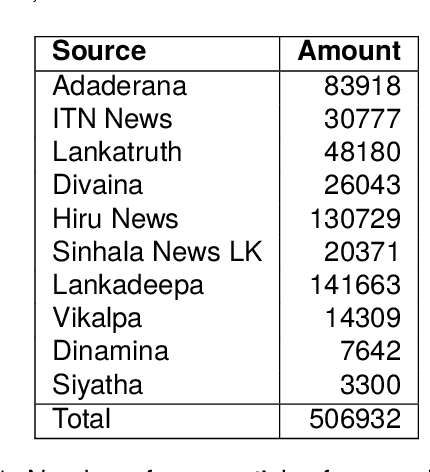
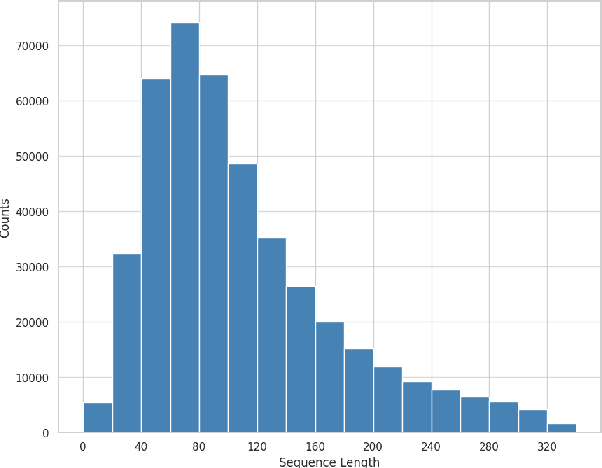
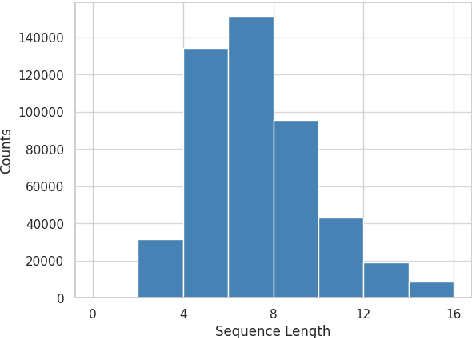
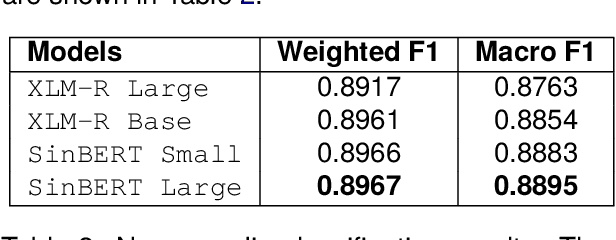
The introduction of large language models (LLMs) has advanced natural language processing (NLP), but their effectiveness is largely dependent on pre-training resources. This is especially evident in low-resource languages, such as Sinhala, which face two primary challenges: the lack of substantial training data and limited benchmarking datasets. In response, this study introduces NSINA, a comprehensive news corpus of over 500,000 articles from popular Sinhala news websites, along with three NLP tasks: news media identification, news category prediction, and news headline generation. The release of NSINA aims to provide a solution to challenges in adapting LLMs to Sinhala, offering valuable resources and benchmarks for improving NLP in the Sinhala language. NSINA is the largest news corpus for Sinhala, available up to date.
Can Model Fusing Help Transformers in Long Document Classification? An Empirical Study
Jul 18, 2023



Text classification is an area of research which has been studied over the years in Natural Language Processing (NLP). Adapting NLP to multiple domains has introduced many new challenges for text classification and one of them is long document classification. While state-of-the-art transformer models provide excellent results in text classification, most of them have limitations in the maximum sequence length of the input sequence. The majority of the transformer models are limited to 512 tokens, and therefore, they struggle with long document classification problems. In this research, we explore on employing Model Fusing for long document classification while comparing the results with well-known BERT and Longformer architectures.
Deep Learning Methods for Extracting Metaphorical Names of Flowers and Plants
May 21, 2023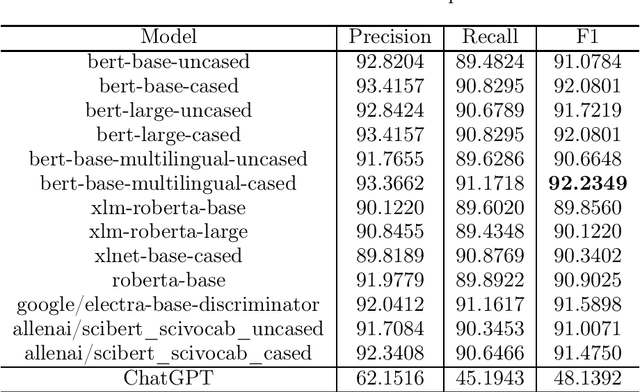
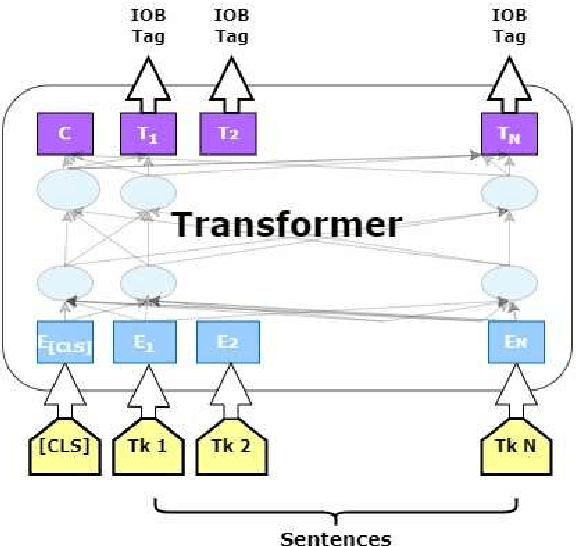
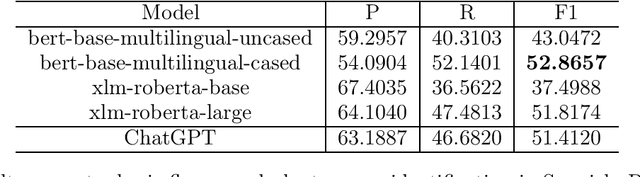
The domain of Botany is rich with metaphorical terms. Those terms play an important role in the description and identification of flowers and plants. However, the identification of such terms in discourse is an arduous task. This leads in some cases to committing errors during translation processes and lexicographic tasks. The process is even more challenging when it comes to machine translation, both in the cases of single-word terms and multi-word terms. One of the recent concerns of Natural Language Processing (NLP) applications and Machine Translation (MT) technologies is the automatic identification of metaphor-based words in discourse through Deep Learning (DL). In this study, we seek to fill this gap through the use of thirteen popular transformer based models, as well as ChatGPT, and we show that discriminative models perform better than GPT-3.5 model with our best performer reporting 92.2349% F1 score in metaphoric flower and plant names identification task.
SOLD: Sinhala Offensive Language Dataset
Dec 01, 2022The widespread of offensive content online, such as hate speech and cyber-bullying, is a global phenomenon. This has sparked interest in the artificial intelligence (AI) and natural language processing (NLP) communities, motivating the development of various systems trained to detect potentially harmful content automatically. These systems require annotated datasets to train the machine learning (ML) models. However, with a few notable exceptions, most datasets on this topic have dealt with English and a few other high-resource languages. As a result, the research in offensive language identification has been limited to these languages. This paper addresses this gap by tackling offensive language identification in Sinhala, a low-resource Indo-Aryan language spoken by over 17 million people in Sri Lanka. We introduce the Sinhala Offensive Language Dataset (SOLD) and present multiple experiments on this dataset. SOLD is a manually annotated dataset containing 10,000 posts from Twitter annotated as offensive and not offensive at both sentence-level and token-level, improving the explainability of the ML models. SOLD is the first large publicly available offensive language dataset compiled for Sinhala. We also introduce SemiSOLD, a larger dataset containing more than 145,000 Sinhala tweets, annotated following a semi-supervised approach.
Overview of the HASOC Subtrack at FIRE 2022: Offensive Language Identification in Marathi
Nov 18, 2022



The widespread of offensive content online has become a reason for great concern in recent years, motivating researchers to develop robust systems capable of identifying such content automatically. With the goal of carrying out a fair evaluation of these systems, several international competitions have been organized, providing the community with important benchmark data and evaluation methods for various languages. Organized since 2019, the HASOC (Hate Speech and Offensive Content Identification) shared task is one of these initiatives. In its fourth iteration, HASOC 2022 included three subtracks for English, Hindi, and Marathi. In this paper, we report the results of the HASOC 2022 Marathi subtrack which provided participants with a dataset containing data from Twitter manually annotated using the popular OLID taxonomy. The Marathi track featured three additional subtracks, each corresponding to one level of the taxonomy: Task A - offensive content identification (offensive vs. non-offensive); Task B - categorization of offensive types (targeted vs. untargeted), and Task C - offensive target identification (individual vs. group vs. others). Overall, 59 runs were submitted by 10 teams. The best systems obtained an F1 of 0.9745 for Subtrack 3A, an F1 of 0.9207 for Subtrack 3B, and F1 of 0.9607 for Subtrack 3C. The best performing algorithms were a mixture of traditional and deep learning approaches.
Transformer-based Detection of Multiword Expressions in Flower and Plant Names
Sep 20, 2022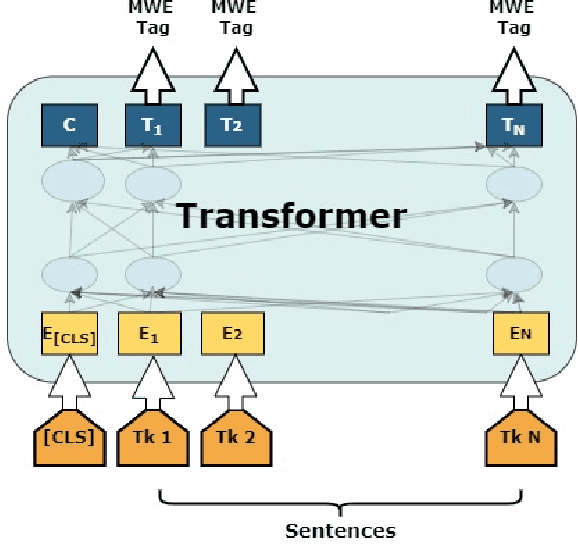
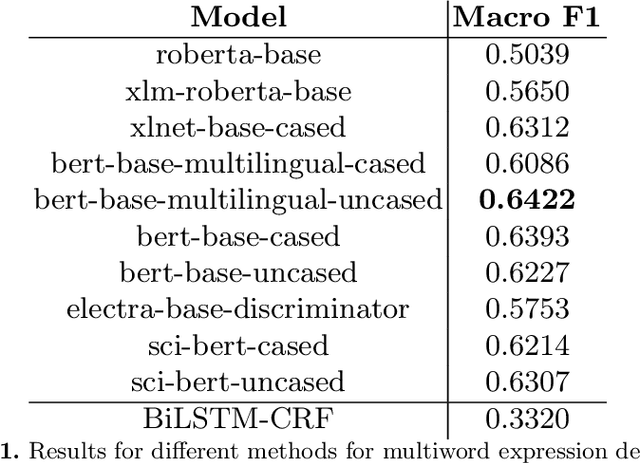
Multiword expression (MWE) is a sequence of words which collectively present a meaning which is not derived from its individual words. The task of processing MWEs is crucial in many natural language processing (NLP) applications, including machine translation and terminology extraction. Therefore, detecting MWEs in different domains is an important research topic. In this paper, we explore state-of-the-art neural transformers in the task of detecting MWEs in flower and plant names. We evaluate different transformer models on a dataset created from Encyclopedia of Plants and Flower. We empirically show that transformer models outperform the previous neural models based on long short-term memory (LSTM).
BERT(s) to Detect Multiword Expressions
Aug 16, 2022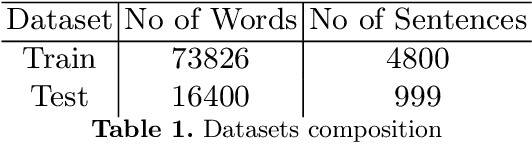
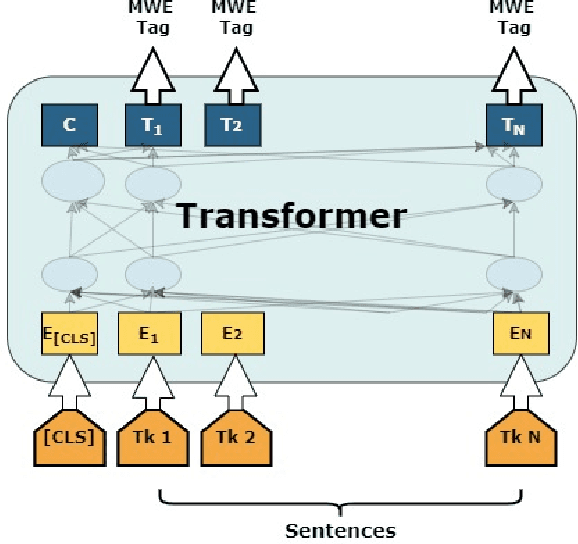
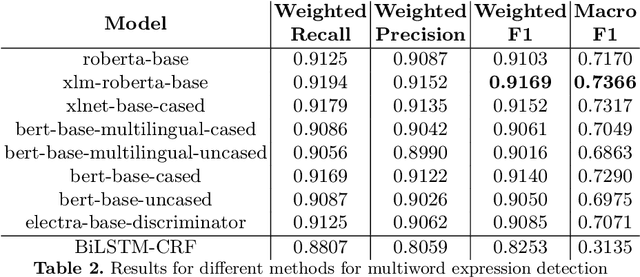
Multiword expressions (MWEs) present groups of words in which the meaning of the whole is not derived from the meaning of its parts. The task of processing MWEs is crucial in many natural language processing (NLP) applications, including machine translation and terminology extraction. Therefore, detecting MWEs is a popular research theme. In this paper, we explore state-of-the-art neural transformers in the task of detecting MWEs.We empirically evaluate several transformer models in the dataset for SemEval-2016 Task 10: Detecting Minimal Semantic Units and their Meanings (DiMSUM). We show that transformer models outperform the previous neural models based on long short-term memory (LSTM). The code and pre-trained model will be made freely available to the community.
DTW at Qur'an QA 2022: Utilising Transfer Learning with Transformers for Question Answering in a Low-resource Domain
May 12, 2022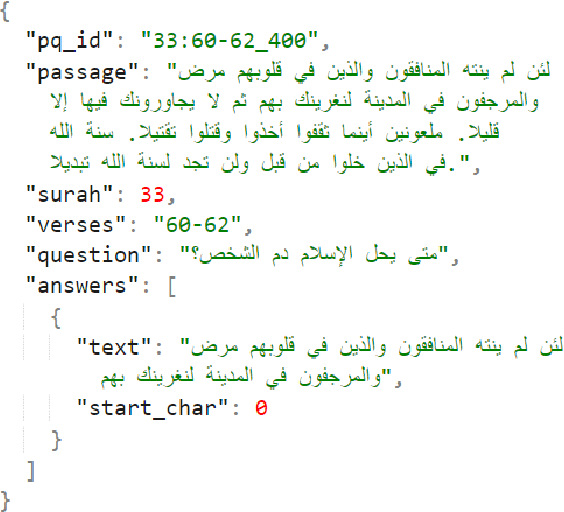
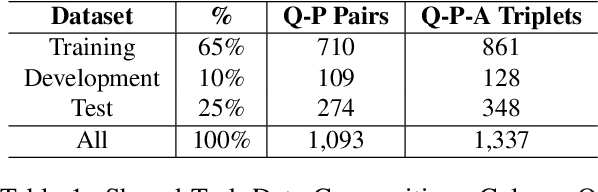
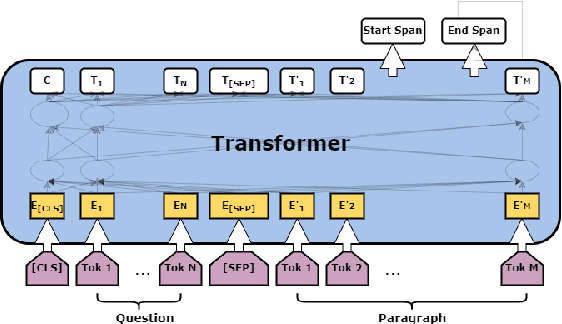
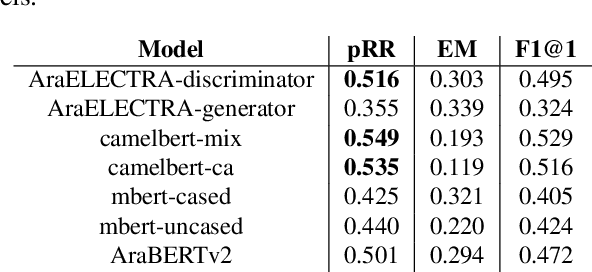
The task of machine reading comprehension (MRC) is a useful benchmark to evaluate the natural language understanding of machines. It has gained popularity in the natural language processing (NLP) field mainly due to the large number of datasets released for many languages. However, the research in MRC has been understudied in several domains, including religious texts. The goal of the Qur'an QA 2022 shared task is to fill this gap by producing state-of-the-art question answering and reading comprehension research on Qur'an. This paper describes the DTW entry to the Quran QA 2022 shared task. Our methodology uses transfer learning to take advantage of available Arabic MRC data. We further improve the results using various ensemble learning strategies. Our approach provided a partial Reciprocal Rank (pRR) score of 0.49 on the test set, proving its strong performance on the task.