 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSINA: A News Corpus for Sinhala
Paper and Code
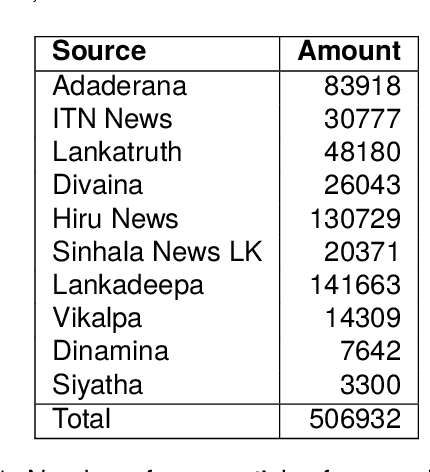
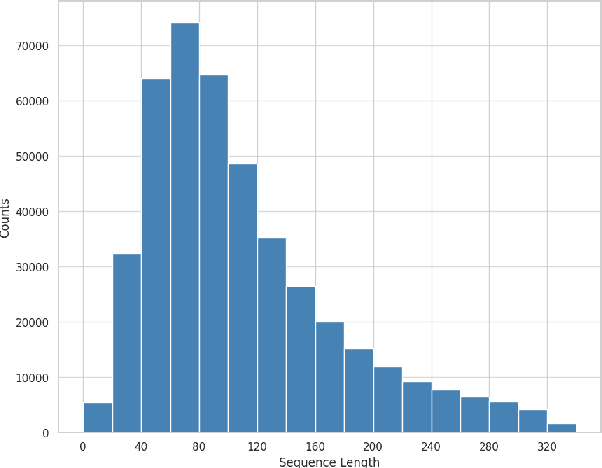
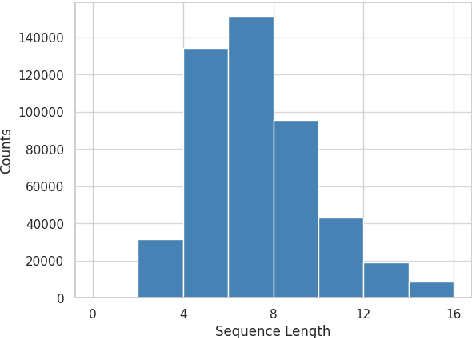
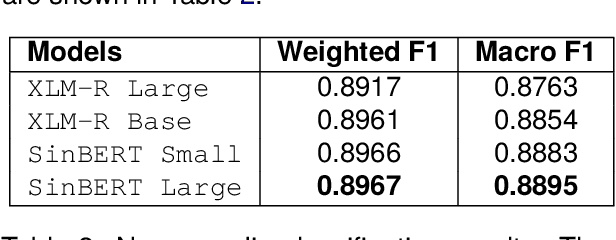
The introduction of large language models (LLMs) has advanced natural language processing (NLP), but their effectiveness is largely dependent on pre-training resources. This is especially evident in low-resource languages, such as Sinhala, which face two primary challenges: the lack of substantial training data and limited benchmarking datasets. In response, this study introduces NSINA, a comprehensive news corpus of over 500,000 articles from popular Sinhala news websites, along with three NLP tasks: news media identification, news category prediction, and news headline generation. The release of NSINA aims to provide a solution to challenges in adapting LLMs to Sinhala, offering valuable resources and benchmarks for improving NLP in the Sinhala language. NSINA is the largest news corpus for Sinhala, available up to date.