 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHaSIS: Shared Task on Sentiment Analysis for Arabic Dialects
Nov 17, 2025The hospitality industry in the Arab world increasingly relies on customer feedback to shape services, driving the need for advanced Arabic sentiment analysis tools. To address this challenge, the Sentiment Analysis on Arabic Dialects in the Hospitality Domain shared task focuses on Sentiment Detection in Arabic Dialects. This task leverages a multi-dialect, manually curated dataset derived from hotel reviews originally written in Modern Standard Arabic (MSA) and translated into Saudi and Moroccan (Darija) dialects. The dataset consists of 538 sentiment-balanced reviews spanning positive, neutral, and negative categories. Translations were validated by native speakers to ensure dialectal accuracy and sentiment preservation. This resource supports the development of dialect-aware NLP systems for real-world applications in customer experience analysis. More than 40 teams have registered for the shared task, with 12 submitting systems during the evaluation phase. The top-performing system achieved an F1 score of 0.81, demonstrating the feasibility and ongoing challenges of sentiment analysis across Arabic dialects.
Overview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
NSINA: A News Corpus for Sinhala
Mar 25, 2024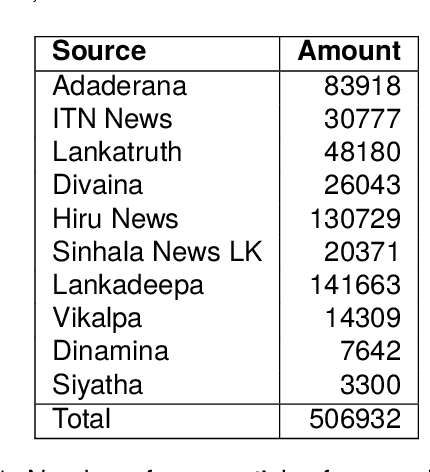
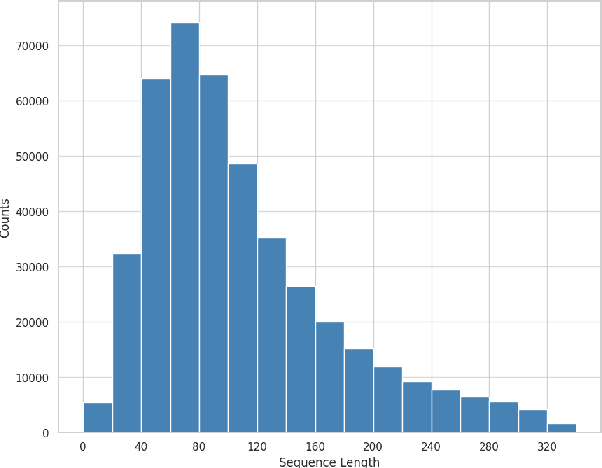
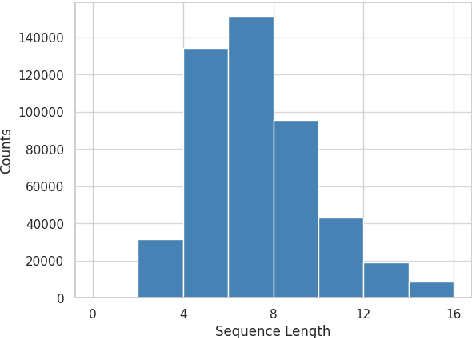
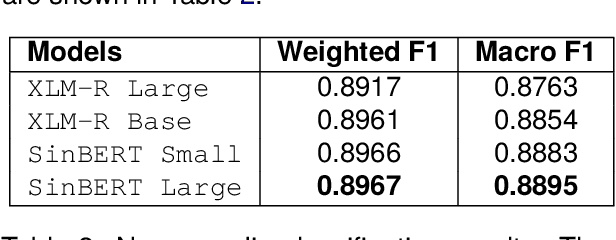
The introduction of large language models (LLMs) has advanced natural language processing (NLP), but their effectiveness is largely dependent on pre-training resources. This is especially evident in low-resource languages, such as Sinhala, which face two primary challenges: the lack of substantial training data and limited benchmarking datasets. In response, this study introduces NSINA, a comprehensive news corpus of over 500,000 articles from popular Sinhala news websites, along with three NLP tasks: news media identification, news category prediction, and news headline generation. The release of NSINA aims to provide a solution to challenges in adapting LLMs to Sinhala, offering valuable resources and benchmarks for improving NLP in the Sinhala language. NSINA is the largest news corpus for Sinhala, available up to date.
CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking
Mar 04, 2024Automatic Compliance Checking (ACC) within the Architecture, Engineering, and Construction (AEC) sector necessitates automating the interpretation of building regulations to achieve its full potential. However, extracting information from textual rules to convert them to a machine-readable format has been a challenge due to the complexities associated with natural language and the limited resources that can support advanced machine-learning techniques. To address this challenge, we introduce CODE-ACCORD, a unique dataset compiled under the EU Horizon ACCORD project. CODE-ACCORD comprises 862 self-contained sentences extracted from the building regulations of England and Finland. Aligned with our core objective of facilitating information extraction from text for machine-readable rule generation, each sentence was annotated with entities and relations. Entities represent specific components such as "window" and "smoke detectors", while relations denote semantic associations between these entities, collectively capturing the conveyed ideas in natural language. We manually annotated all the sentences using a group of 12 annotators. Each sentence underwent annotations by multiple annotators and subsequently careful data curation to finalise annotations, ensuring their accuracy and reliability, thereby establishing the dataset as a solid ground truth. CODE-ACCORD offers a rich resource for diverse machine learning and natural language processing (NLP) related tasks in ACC, including text classification, entity recognition and relation extraction. To the best of our knowledge, this is the first entity and relation-annotated dataset in compliance checking, which is also publicly available.
SOLD: Sinhala Offensive Language Dataset
Dec 01, 2022The widespread of offensive content online, such as hate speech and cyber-bullying, is a global phenomenon. This has sparked interest in the artificial intelligence (AI) and natural language processing (NLP) communities, motivating the development of various systems trained to detect potentially harmful content automatically. These systems require annotated datasets to train the machine learning (ML) models. However, with a few notable exceptions, most datasets on this topic have dealt with English and a few other high-resource languages. As a result, the research in offensive language identification has been limited to these languages. This paper addresses this gap by tackling offensive language identification in Sinhala, a low-resource Indo-Aryan language spoken by over 17 million people in Sri Lanka. We introduce the Sinhala Offensive Language Dataset (SOLD) and present multiple experiments on this dataset. SOLD is a manually annotated dataset containing 10,000 posts from Twitter annotated as offensive and not offensive at both sentence-level and token-level, improving the explainability of the ML models. SOLD is the first large publicly available offensive language dataset compiled for Sinhala. We also introduce SemiSOLD, a larger dataset containing more than 145,000 Sinhala tweets, annotated following a semi-supervised approach.
Event Causality Identification with Causal News Corpus -- Shared Task 3, CASE 2022
Nov 22, 2022



The Event Causality Identification Shared Task of CASE 2022 involved two subtasks working on the Causal News Corpus. Subtask 1 required participants to predict if a sentence contains a causal relation or not. This is a supervised binary classification task. Subtask 2 required participants to identify the Cause, Effect and Signal spans per causal sentence. This could be seen as a supervised sequence labeling task. For both subtasks, participants uploaded their predictions for a held-out test set, and ranking was done based on binary F1 and macro F1 scores for Subtask 1 and 2, respectively. This paper summarizes the work of the 17 teams that submitted their results to our competition and 12 system description papers that were received. The best F1 scores achieved for Subtask 1 and 2 were 86.19% and 54.15%, respectively. All the top-performing approaches involved pre-trained language models fine-tuned to the targeted task. We further discuss these approaches and analyze errors across participants' systems in this paper.
Extended Multilingual Protest News Detection -- Shared Task 1, CASE 2021 and 2022
Nov 21, 2022



We report results of the CASE 2022 Shared Task 1 on Multilingual Protest Event Detection. This task is a continuation of CASE 2021 that consists of four subtasks that are i) document classification, ii) sentence classification, iii) event sentence coreference identification, and iv) event extraction. The CASE 2022 extension consists of expanding the test data with more data in previously available languages, namely, English, Hindi, Portuguese, and Spanish, and adding new test data in Mandarin, Turkish, and Urdu for Sub-task 1, document classification. The training data from CASE 2021 in English, Portuguese and Spanish were utilized. Therefore, predicting document labels in Hindi, Mandarin, Turkish, and Urdu occurs in a zero-shot setting. The CASE 2022 workshop accepts reports on systems developed for predicting test data of CASE 2021 as well. We observe that the best systems submitted by CASE 2022 participants achieve between 79.71 and 84.06 F1-macro for new languages in a zero-shot setting. The winning approaches are mainly ensembling models and merging data in multiple languages. The best two submissions on CASE 2021 data outperform submissions from last year for Subtask 1 and Subtask 2 in all languages. Only the following scenarios were not outperformed by new submissions on CASE 2021: Subtask 3 Portuguese \& Subtask 4 English.
The Causal News Corpus: Annotating Causal Relations in Event Sentences from News
Apr 25, 2022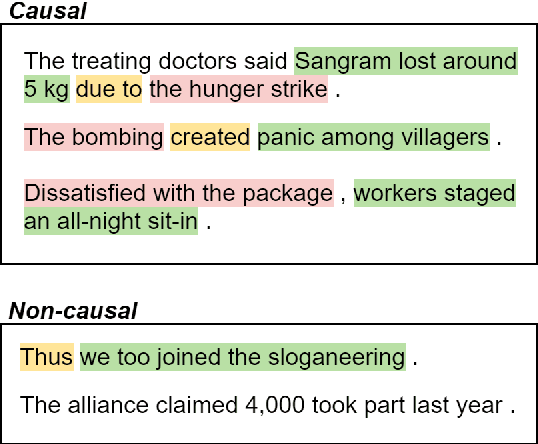
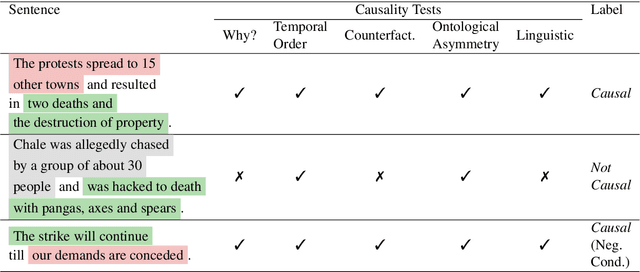
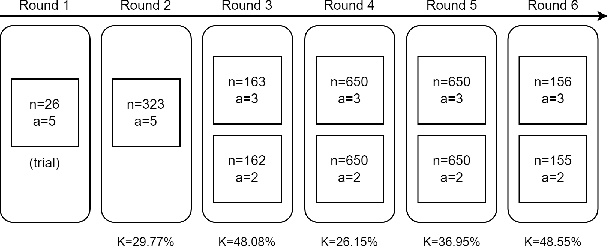
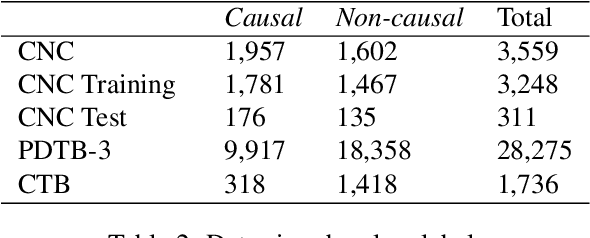
Despite the importance of understanding causality, corpora addressing causal relations are limited. There is a discrepancy between existing annotation guidelines of event causality and conventional causality corpora that focus more on linguistics. Many guidelines restrict themselves to include only explicit relations or clause-based arguments. Therefore, we propose an annotation schema for event causality that addresses these concerns. We annotated 3,559 event sentences from protest event news with labels on whether it contains causal relations or not. Our corpus is known as the Causal News Corpus (CNC). A neural network built upon a state-of-the-art pre-trained language model performed well with 81.20% F1 score on test set, and 83.46% in 5-folds cross-validation. CNC is transferable across two external corpora: CausalTimeBank (CTB) and Penn Discourse Treebank (PDTB). Leveraging each of these external datasets for training, we achieved up to approximately 64% F1 on the CNC test set without additional fine-tuning. CNC also served as an effective training and pre-training dataset for the two external corpora. Lastly, we demonstrate the difficulty of our task to the layman in a crowd-sourced annotation exercise. Our annotated corpus is publicly available, providing a valuable resource for causal text mining researchers.
Transformers to Fight the COVID-19 Infodemic
Apr 25, 2021



The massive spread of false information on social media has become a global risk especially in a global pandemic situation like COVID-19. False information detection has thus become a surging research topic in recent months. NLP4IF-2021 shared task on fighting the COVID-19 infodemic has been organised to strengthen the research in false information detection where the participants are asked to predict seven different binary labels regarding false information in a tweet. The shared task has been organised in three languages; Arabic, Bulgarian and English. In this paper, we present our approach to tackle the task objective using transformers. Overall, our approach achieves a 0.707 mean F1 score in Arabic, 0.578 mean F1 score in Bulgarian and 0.864 mean F1 score in English ranking 4th place in all the languages.
TransWiC at SemEval-2021 Task 2: Transformer-based Multilingual and Cross-lingual Word-in-Context Disambiguation
Apr 09, 2021
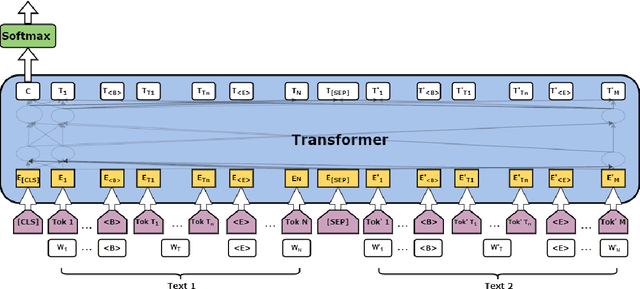
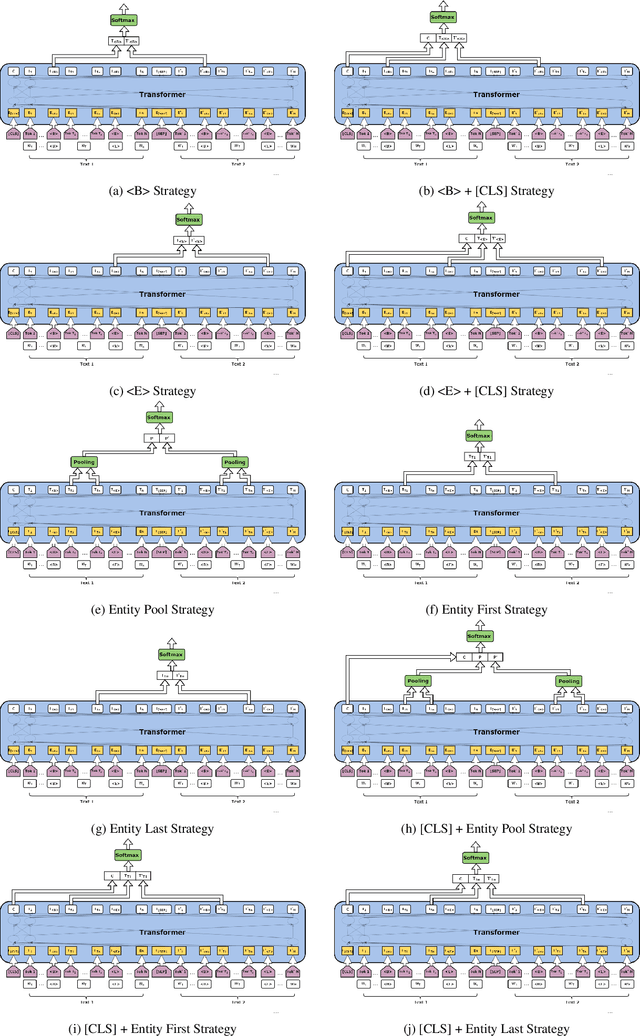

Identifying whether a word carries the same meaning or different meaning in two contexts is an important research area in natural language processing which plays a significant role in many applications such as question answering, document summarisation, information retrieval and information extraction. Most of the previous work in this area rely on language-specific resources making it difficult to generalise across languages. Considering this limitation, our approach to SemEval-2021 Task 2 is based only on pretrained transformer models and does not use any language-specific processing and resources. Despite that, our best model achieves 0.90 accuracy for English-English subtask which is very compatible compared to the best result of the subtask; 0.93 accuracy. Our approach also achieves satisfactory results in other monolingual and cross-lingual language pairs as well.