 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
NSINA: A News Corpus for Sinhala
Mar 25, 2024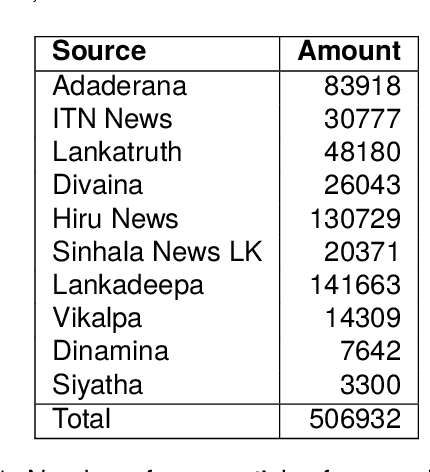
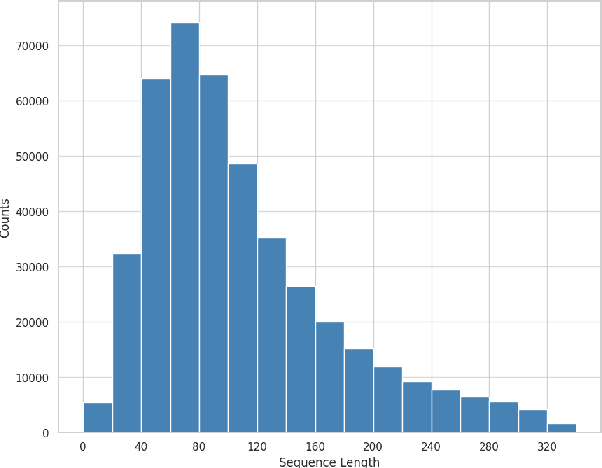
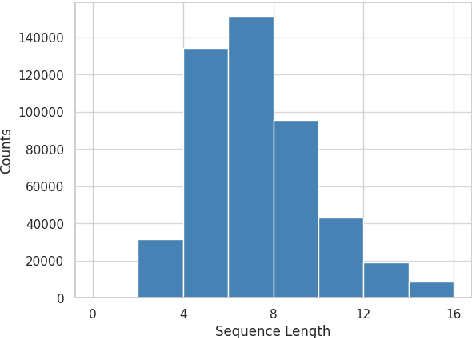
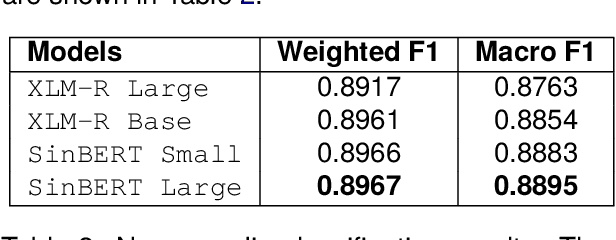
The introduction of large language models (LLMs) has advanced natural language processing (NLP), but their effectiveness is largely dependent on pre-training resources. This is especially evident in low-resource languages, such as Sinhala, which face two primary challenges: the lack of substantial training data and limited benchmarking datasets. In response, this study introduces NSINA, a comprehensive news corpus of over 500,000 articles from popular Sinhala news websites, along with three NLP tasks: news media identification, news category prediction, and news headline generation. The release of NSINA aims to provide a solution to challenges in adapting LLMs to Sinhala, offering valuable resources and benchmarks for improving NLP in the Sinhala language. NSINA is the largest news corpus for Sinhala, available up to date.
SOLD: Sinhala Offensive Language Dataset
Dec 01, 2022The widespread of offensive content online, such as hate speech and cyber-bullying, is a global phenomenon. This has sparked interest in the artificial intelligence (AI) and natural language processing (NLP) communities, motivating the development of various systems trained to detect potentially harmful content automatically. These systems require annotated datasets to train the machine learning (ML) models. However, with a few notable exceptions, most datasets on this topic have dealt with English and a few other high-resource languages. As a result, the research in offensive language identification has been limited to these languages. This paper addresses this gap by tackling offensive language identification in Sinhala, a low-resource Indo-Aryan language spoken by over 17 million people in Sri Lanka. We introduce the Sinhala Offensive Language Dataset (SOLD) and present multiple experiments on this dataset. SOLD is a manually annotated dataset containing 10,000 posts from Twitter annotated as offensive and not offensive at both sentence-level and token-level, improving the explainability of the ML models. SOLD is the first large publicly available offensive language dataset compiled for Sinhala. We also introduce SemiSOLD, a larger dataset containing more than 145,000 Sinhala tweets, annotated following a semi-supervised approach.
Transformers to Fight the COVID-19 Infodemic
Apr 25, 2021



The massive spread of false information on social media has become a global risk especially in a global pandemic situation like COVID-19. False information detection has thus become a surging research topic in recent months. NLP4IF-2021 shared task on fighting the COVID-19 infodemic has been organised to strengthen the research in false information detection where the participants are asked to predict seven different binary labels regarding false information in a tweet. The shared task has been organised in three languages; Arabic, Bulgarian and English. In this paper, we present our approach to tackle the task objective using transformers. Overall, our approach achieves a 0.707 mean F1 score in Arabic, 0.578 mean F1 score in Bulgarian and 0.864 mean F1 score in English ranking 4th place in all the languages.