 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABCO: Adaptive Bacterial Colony Optimisation
May 02, 2025



This paper introduces a new optimisation algorithm, called Adaptive Bacterial Colony Optimisation (ABCO), modelled after the foraging behaviour of E. coli bacteria. The algorithm follows three stages--explore, exploit and reproduce--and is adaptable to meet the requirements of its applications. The performance of the proposed ABCO algorithm is compared to that of established optimisation algorithms--particle swarm optimisation (PSO) and ant colony optimisation (ACO)--on a set of benchmark functions. Experimental results demonstrate the benefits of the adaptive nature of the proposed algorithm: ABCO runs much faster than PSO and ACO while producing competitive results and outperforms PSO and ACO in a scenario where the running time is not crucial.
PAIR: A Novel Large Language Model-Guided Selection Strategy for Evolutionary Algorithms
Mar 05, 2025Evolutionary Algorithms (EAs) employ random or simplistic selection methods, limiting their exploration of solution spaces and convergence to optimal solutions. The randomness in performing crossover or mutations may limit the model's ability to evolve efficiently. This paper introduces Preference-Aligned Individual Reciprocity (PAIR), a novel selection approach leveraging Large Language Models to emulate human-like mate selection, thereby introducing intelligence to the pairing process in EAs. PAIR prompts an LLM to evaluate individuals within a population based on genetic diversity, fitness level, and crossover compatibility, guiding more informed pairing decisions. We evaluated PAIR against a baseline method called LLM-driven EA (LMEA), published recently. Results indicate that PAIR significantly outperforms LMEA across various TSP instances, achieving lower optimality gaps and improved convergence. This performance is especially noticeable when combined with the flash thinking model, demonstrating increased population diversity to escape local optima. In general, PAIR provides a new strategy in the area of in-context learning for LLM-driven selection in EAs via sophisticated preference modelling, paving the way for improved solutions and further studies into LLM-guided optimization.
The dynamics of meaning through time: Assessment of Large Language Models
Jan 09, 2025
Understanding how large language models (LLMs) grasp the historical context of concepts and their semantic evolution is essential in advancing artificial intelligence and linguistic studies. This study aims to evaluate the capabilities of various LLMs in capturing temporal dynamics of meaning, specifically how they interpret terms across different time periods. We analyze a diverse set of terms from multiple domains, using tailored prompts and measuring responses through both objective metrics (e.g., perplexity and word count) and subjective human expert evaluations. Our comparative analysis includes prominent models like ChatGPT, GPT-4, Claude, Bard, Gemini, and Llama. Findings reveal marked differences in each model's handling of historical context and semantic shifts, highlighting both strengths and limitations in temporal semantic understanding. These insights offer a foundation for refining LLMs to better address the evolving nature of language, with implications for historical text analysis, AI design, and applications in digital humanities.
CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking
Mar 04, 2024Automatic Compliance Checking (ACC) within the Architecture, Engineering, and Construction (AEC) sector necessitates automating the interpretation of building regulations to achieve its full potential. However, extracting information from textual rules to convert them to a machine-readable format has been a challenge due to the complexities associated with natural language and the limited resources that can support advanced machine-learning techniques. To address this challenge, we introduce CODE-ACCORD, a unique dataset compiled under the EU Horizon ACCORD project. CODE-ACCORD comprises 862 self-contained sentences extracted from the building regulations of England and Finland. Aligned with our core objective of facilitating information extraction from text for machine-readable rule generation, each sentence was annotated with entities and relations. Entities represent specific components such as "window" and "smoke detectors", while relations denote semantic associations between these entities, collectively capturing the conveyed ideas in natural language. We manually annotated all the sentences using a group of 12 annotators. Each sentence underwent annotations by multiple annotators and subsequently careful data curation to finalise annotations, ensuring their accuracy and reliability, thereby establishing the dataset as a solid ground truth. CODE-ACCORD offers a rich resource for diverse machine learning and natural language processing (NLP) related tasks in ACC, including text classification, entity recognition and relation extraction. To the best of our knowledge, this is the first entity and relation-annotated dataset in compliance checking, which is also publicly available.
MCUa: Multi-level Context and Uncertainty aware Dynamic Deep Ensemble for Breast Cancer Histology Image Classification
Aug 24, 2021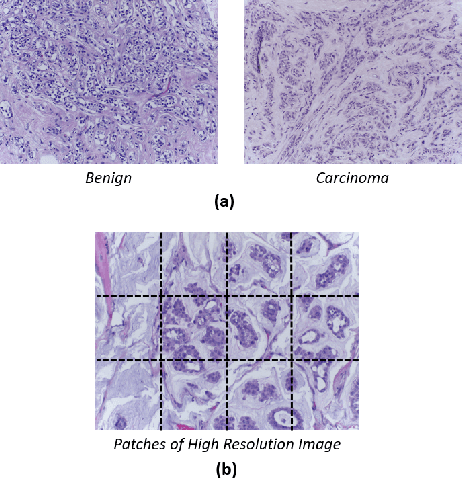
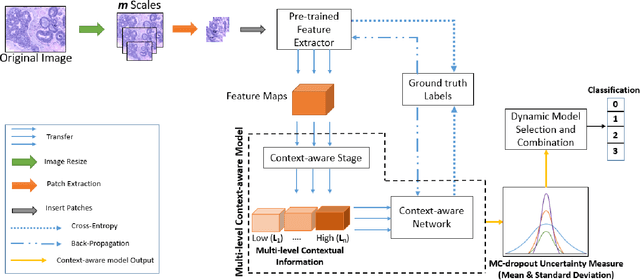

Breast histology image classification is a crucial step in the early diagnosis of breast cancer. In breast pathological diagnosis, Convolutional Neural Networks (CNNs) have demonstrated great success using digitized histology slides. However, tissue classification is still challenging due to the high visual variability of the large-sized digitized samples and the lack of contextual information. In this paper, we propose a novel CNN, called Multi-level Context and Uncertainty aware (MCUa) dynamic deep learning ensemble model.MCUamodel consists of several multi-level context-aware models to learn the spatial dependency between image patches in a layer-wise fashion. It exploits the high sensitivity to the multi-level contextual information using an uncertainty quantification component to accomplish a novel dynamic ensemble model.MCUamodelhas achieved a high accuracy of 98.11% on a breast cancer histology image dataset. Experimental results show the superior effectiveness of the proposed solution compared to the state-of-the-art histology classification models.
* accepted by IEEE Transactions on Biomedical Engineering
Embed2Detect: Temporally Clustered Embedded Words for Event Detection in Social Media
Jun 11, 2020

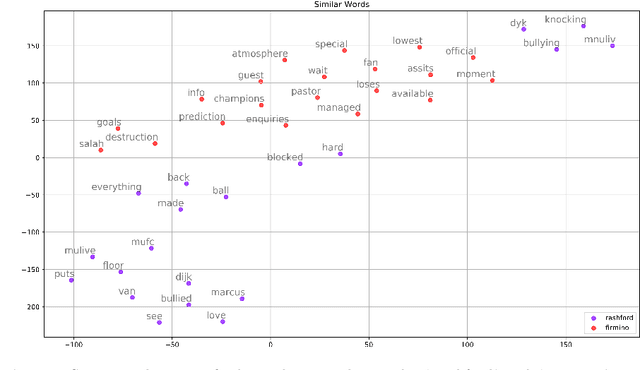

Event detection in social media refers to automatic identification of important information shared in social media platforms on a certain time. Considering the dynamic nature and high volume of data production in data streams, it is impractical to filter the events manually. Therefore, it is important to have an automated mechanism to detect events in order to utilise social media data effectively. Analysing the available literature, most of the existing event detection methods are only focused on statistical and syntactical features in data, even though the underlying semantics are also important for an effective information retrieval from text, because they describe the connections between words and their meanings. In this paper, we propose a novel method termed Embed2Detect for event detection in social media by combining the characteristics in prediction-based word embeddings and hierarchical agglomerative clustering. The adoption of prediction-based word embeddings incorporates the semantical features in the text to overcome a major limitation available with previous approaches. This method is experimented on two recent social media data sets which represent the sports and politics domains. The results obtained from the experiments reveal that our approach is capable of effective and efficient event detection with the proof of significant improvements over baselines. For sports data set, Embed2Detect achieved 30% higher F-measure than the best performed baseline method and for political data set, it was an increase by 36%.
Classification of COVID-19 in chest X-ray images using DeTraC deep convolutional neural network
Apr 18, 2020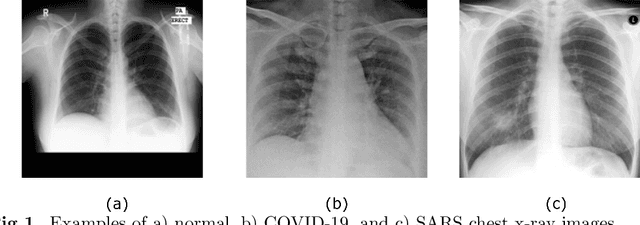


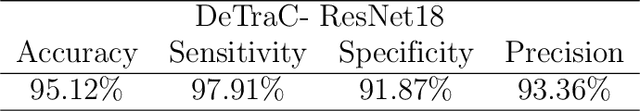
Chest X-ray is the first imaging technique that plays an important role in the diagnosis of COVID-19 disease. Due to the high availability of large-scale annotated image datasets, great success has been achieved using convolutional neural networks (CNNs) for image recognition and classification. However, due to the limited availability of annotated medical images, the classification of medical images remains the biggest challenge in medical diagnosis. Thanks to transfer learning, an effective mechanism that can provide a promising solution by transferring knowledge from generic object recognition tasks to domain-specific tasks. In this paper, we validate and adapt our previously developed CNN, called Decompose, Transfer, and Compose (DeTraC), for the classification of COVID-19 chest X-ray images. DeTraC can deal with any irregularities in the image dataset by investigating its class boundaries using a class decomposition mechanism. The experimental results showed the capability of DeTraC in the detection of COVID-19 cases from a comprehensive image dataset collected from several hospitals around the world. High accuracy of 95.12% (with a sensitivity of 97.91%, a specificity of 91.87%, and a precision of 93.36%) was achieved by DeTraC in the detection of COVID-19 X-ray images from normal, and severe acute respiratory syndrome cases.
Co-eye: A Multi-resolution Symbolic Representation to TimeSeries Diversified Ensemble Classification
Apr 15, 2020



Time series classification (TSC) is a challenging task that attracted many researchers in the last few years. One main challenge in TSC is the diversity of domains where time series data come from. Thus, there is no "one model that fits all" in TSC. Some algorithms are very accurate in classifying a specific type of time series when the whole series is considered, while some only target the existence/non-existence of specific patterns/shapelets. Yet other techniques focus on the frequency of occurrences of discriminating patterns/features. This paper presents a new classification technique that addresses the inherent diversity problem in TSC using a nature-inspired method. The technique is stimulated by how flies look at the world through "compound eyes" that are made up of thousands of lenses, called ommatidia. Each ommatidium is an eye with its own lens, and thousands of them together create a broad field of vision. The developed technique similarly uses different lenses and representations to look at the time series, and then combines them for broader visibility. These lenses have been created through hyper-parameterisation of symbolic representations (Piecewise Aggregate and Fourier approximations). The algorithm builds a random forest for each lens, then performs soft dynamic voting for classifying new instances using the most confident eyes, i.e, forests. We evaluate the new technique, coined Co-eye, using the recently released extended version of UCR archive, containing more than 100 datasets across a wide range of domains. The results show the benefits of bringing together different perspectives reflecting on the accuracy and robustness of Co-eye in comparison to other state-of-the-art techniques.
DeepStreamCE: A Streaming Approach to Concept Evolution Detection in Deep Neural Networks
Apr 08, 2020



Deep neural networks have experimentally demonstrated superior performance over other machine learning approaches in decision-making predictions. However, one major concern is the closed set nature of the classification decision on the trained classes, which can have serious consequences in safety critical systems. When the deep neural network is in a streaming environment, fast interpretation of this classification is required to determine if the classification result is trusted. Un-trusted classifications can occur when the input data to the deep neural network changes over time. One type of change that can occur is concept evolution, where a new class is introduced that the deep neural network was not trained on. In the majority of deep neural network architectures, the only option is to assign this instance to one of the classes it was trained on, which would be incorrect. The aim of this research is to detect the arrival of a new class in the stream. Existing work on interpreting deep neural networks often focuses on neuron activations to provide visual interpretation and feature extraction. Our novel approach, coined DeepStreamCE, uses streaming approaches for real-time concept evolution detection in deep neural networks. DeepStreamCE applies neuron activation reduction using an autoencoder and MCOD stream-based clustering in the offline phase. Both outputs are used in the online phase to analyse the neuron activations in the evolving stream in order to detect concept evolution occurrence in real time. We evaluate DeepStreamCE by training VGG16 convolutional neural networks on combinations of data from the CIFAR-10 dataset, holding out some classes to be used as concept evolution. For comparison, we apply the data and VGG16 networks to an open-set deep network solution - OpenMax. DeepStreamCE outperforms OpenMax when identifying concept evolution for our datasets.
A Heuristically Modified FP-Tree for Ontology Learning with Applications in Education
Oct 29, 2019
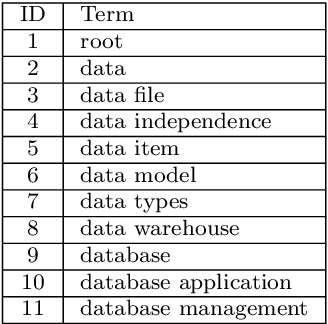

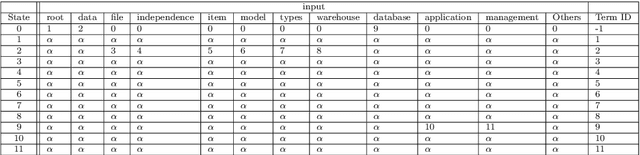
We propose a heuristically modified FP-Tree for ontology learning from text. Unlike previous research, for concept extraction, we use a regular expression parser approach widely adopted in compiler construction, i.e., deterministic finite automata (DFA). Thus, the concepts are extracted from unstructured documents. For ontology learning, we use a frequent pattern mining approach and employ a rule mining heuristic function to enhance its quality. This process does not rely on predefined lexico-syntactic patterns, thus, it is applicable for different subjects. We employ the ontology in a question-answering system for students' content-related questions. For validation, we used textbook questions/answers and questions from online course forums. Subject experts rated the quality of the system's answers on a subset of questions and their ratings were used to identify the most appropriate automatic semantic text similarity metric to use as a validation metric for all answers. The Latent Semantic Analysis was identified as the closest to the experts' ratings. We compared the use of our ontology with the use of Text2Onto for the question-answering system and found that with our ontology 80% of the questions were answered, while with Text2Onto only 28.4% were answered, thanks to the finer grained hierarchy our approach is able to produce.