 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCTECG-Net: Uncertainty-aware Convolution Transformer ECG Network for Arrhythmia Detection
Feb 18, 2026Deep learning has improved automated electrocardiogram (ECG) classification, but limited insight into prediction reliability hinders its use in safety-critical settings. This paper proposes UCTECG-Net, an uncertainty-aware hybrid architecture that combines one-dimensional convolutions and Transformer encoders to process raw ECG signals and their spectrograms jointly. Evaluated on the MIT-BIH Arrhythmia and PTB Diagnostic datasets, UCTECG-Net outperforms LSTM, CNN1D, and Transformer baselines in terms of accuracy, precision, recall and F1 score, achieving up to 98.58% accuracy on MIT-BIH and 99.14% on PTB. To assess predictive reliability, we integrate three uncertainty quantification methods (Monte Carlo Dropout, Deep Ensembles, and Ensemble Monte Carlo Dropout) into all models and analyze their behavior using an uncertainty-aware confusion matrix and derived metrics. The results show that UCTECG-Net, particularly with Ensemble or EMCD, provides more reliable and better-aligned uncertainty estimates than competing architectures, offering a stronger basis for risk-aware ECG decision support.
Uncertainty-Aware Deep Learning for Automated Skin Cancer Classification: A Comprehensive Evaluation
Jun 12, 2025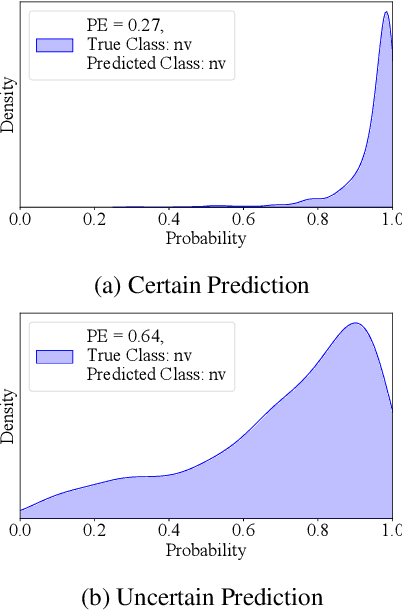
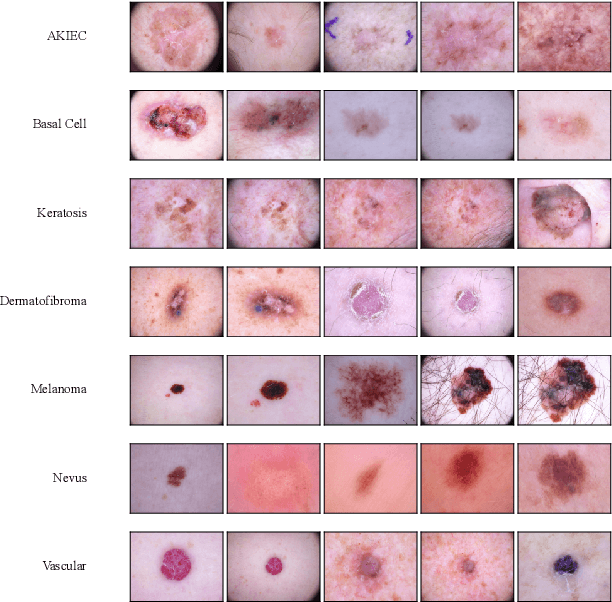
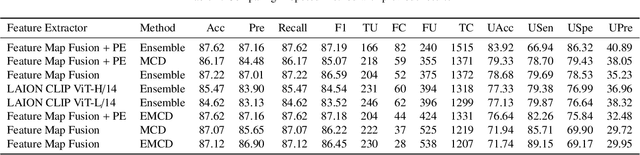
Accurate and reliable skin cancer diagnosis is critical for early treatment and improved patient outcomes. Deep learning (DL) models have shown promise in automating skin cancer classification, but their performance can be limited by data scarcity and a lack of uncertainty awareness. In this study, we present a comprehensive evaluation of DL-based skin lesion classification using transfer learning and uncertainty quantification (UQ) on the HAM10000 dataset. In the first phase, we benchmarked several pre-trained feature extractors-including Contrastive Language-Image Pretraining (CLIP) variants, Residual Network-50 (ResNet50), Densely Connected Convolutional Network (DenseNet121), Visual Geometry Group network (VGG16), and EfficientNet-V2-Large-combined with a range of traditional classifiers such as Support Vector Machine (SVM), eXtreme Gradient Boosting (XGBoost), and logistic regression. Our results show that CLIP-based vision transformers, particularly LAION CLIP ViT-H/14 with SVM, deliver the highest classification performance. In the second phase, we incorporated UQ using Monte Carlo Dropout (MCD), Ensemble, and Ensemble Monte Carlo Dropout (EMCD) to assess not only prediction accuracy but also the reliability of model outputs. We evaluated these models using uncertainty-aware metrics such as uncertainty accuracy(UAcc), uncertainty sensitivity(USen), uncertainty specificity(USpe), and uncertainty precision(UPre). The results demonstrate that ensemble methods offer a good trade-off between accuracy and uncertainty handling, while EMCD is more sensitive to uncertain predictions. This study highlights the importance of integrating UQ into DL-based medical diagnosis to enhance both performance and trustworthiness in real-world clinical applications.
Machine Learning Models for the Identification of Cardiovascular Diseases Using UK Biobank Data
Jul 23, 2024


Machine learning models have the potential to identify cardiovascular diseases (CVDs) early and accurately in primary healthcare settings, which is crucial for delivering timely treatment and management. Although population-based CVD risk models have been used traditionally, these models often do not consider variations in lifestyles, socioeconomic conditions, or genetic predispositions. Therefore, we aimed to develop machine learning models for CVD detection using primary healthcare data, compare the performance of different models, and identify the best models. We used data from the UK Biobank study, which included over 500,000 middle-aged participants from different primary healthcare centers in the UK. Data collected at baseline (2006--2010) and during imaging visits after 2014 were used in this study. Baseline characteristics, including sex, age, and the Townsend Deprivation Index, were included. Participants were classified as having CVD if they reported at least one of the following conditions: heart attack, angina, stroke, or high blood pressure. Cardiac imaging data such as electrocardiogram and echocardiography data, including left ventricular size and function, cardiac output, and stroke volume, were also used. We used 9 machine learning models (LSVM, RBFSVM, GP, DT, RF, NN, AdaBoost, NB, and QDA), which are explainable and easily interpretable. We reported the accuracy, precision, recall, and F-1 scores; confusion matrices; and area under the curve (AUC) curves.
Comparison of gait phase detection using traditional machine learning and deep learning techniques
Mar 07, 2024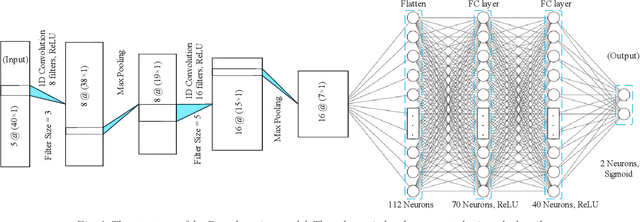
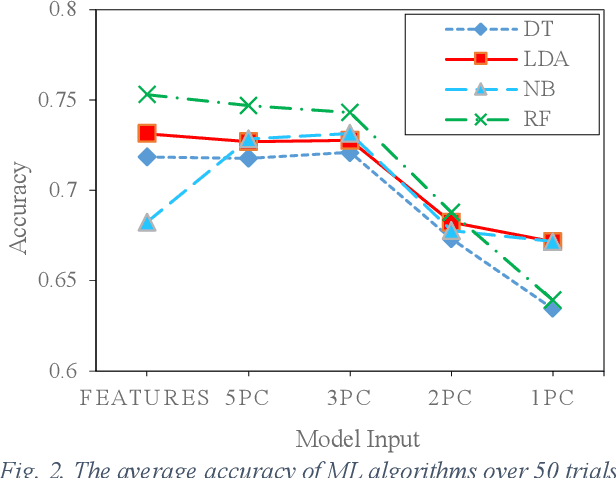


Human walking is a complex activity with a high level of cooperation and interaction between different systems in the body. Accurate detection of the phases of the gait in real-time is crucial to control lower-limb assistive devices like exoskeletons and prostheses. There are several ways to detect the walking gait phase, ranging from cameras and depth sensors to the sensors attached to the device itself or the human body. Electromyography (EMG) is one of the input methods that has captured lots of attention due to its precision and time delay between neuromuscular activity and muscle movement. This study proposes a few Machine Learning (ML) based models on lower-limb EMG data for human walking. The proposed models are based on Gaussian Naive Bayes (NB), Decision Tree (DT), Random Forest (RF), Linear Discriminant Analysis (LDA) and Deep Convolutional Neural Networks (DCNN). The traditional ML models are trained on hand-crafted features or their reduced components using Principal Component Analysis (PCA). On the contrary, the DCNN model utilises convolutional layers to extract features from raw data. The results show up to 75% average accuracy for traditional ML models and 79% for Deep Learning (DL) model. The highest achieved accuracy in 50 trials of the training DL model is 89.5%.
* Copyright \c{opyright} This is the accepted version of an article published in the proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Leveraging Optimal Transport for Enhanced Offline Reinforcement Learning in Surgical Robotic Environments
Oct 13, 2023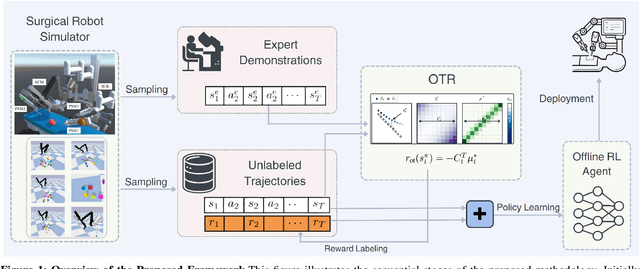
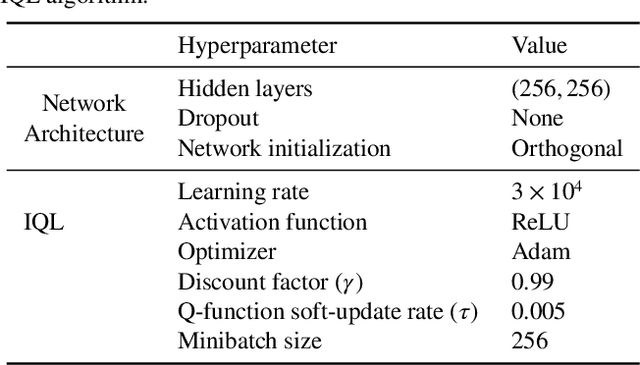


Most Reinforcement Learning (RL) methods are traditionally studied in an active learning setting, where agents directly interact with their environments, observe action outcomes, and learn through trial and error. However, allowing partially trained agents to interact with real physical systems poses significant challenges, including high costs, safety risks, and the need for constant supervision. Offline RL addresses these cost and safety concerns by leveraging existing datasets and reducing the need for resource-intensive real-time interactions. Nevertheless, a substantial challenge lies in the demand for these datasets to be meticulously annotated with rewards. In this paper, we introduce Optimal Transport Reward (OTR) labelling, an innovative algorithm designed to assign rewards to offline trajectories, using a small number of high-quality expert demonstrations. The core principle of OTR involves employing Optimal Transport (OT) to calculate an optimal alignment between an unlabeled trajectory from the dataset and an expert demonstration. This alignment yields a similarity measure that is effectively interpreted as a reward signal. An offline RL algorithm can then utilize these reward signals to learn a policy. This approach circumvents the need for handcrafted rewards, unlocking the potential to harness vast datasets for policy learning. Leveraging the SurRoL simulation platform tailored for surgical robot learning, we generate datasets and employ them to train policies using the OTR algorithm. By demonstrating the efficacy of OTR in a different domain, we emphasize its versatility and its potential to expedite RL deployment across a wide range of fields.
A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges
Sep 05, 2023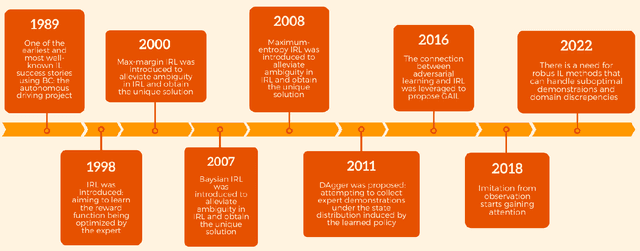
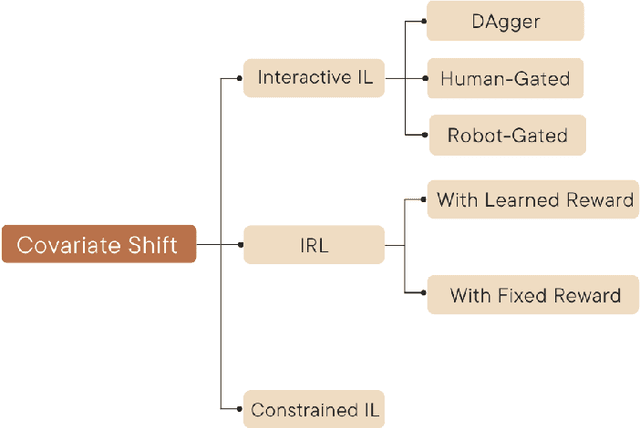
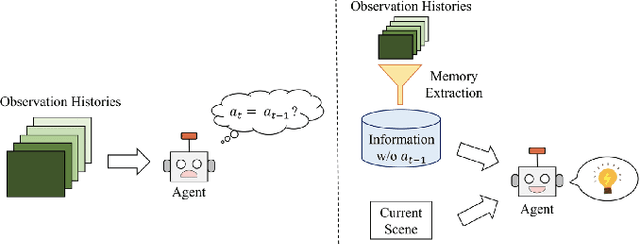
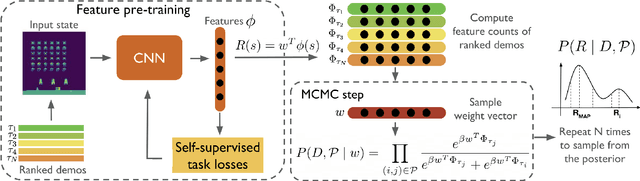
In recent years, the development of robotics and artificial intelligence (AI) systems has been nothing short of remarkable. As these systems continue to evolve, they are being utilized in increasingly complex and unstructured environments, such as autonomous driving, aerial robotics, and natural language processing. As a consequence, programming their behaviors manually or defining their behavior through reward functions (as done in reinforcement learning (RL)) has become exceedingly difficult. This is because such environments require a high degree of flexibility and adaptability, making it challenging to specify an optimal set of rules or reward signals that can account for all possible situations. In such environments, learning from an expert's behavior through imitation is often more appealing. This is where imitation learning (IL) comes into play - a process where desired behavior is learned by imitating an expert's behavior, which is provided through demonstrations. This paper aims to provide an introduction to IL and an overview of its underlying assumptions and approaches. It also offers a detailed description of recent advances and emerging areas of research in the field. Additionally, the paper discusses how researchers have addressed common challenges associated with IL and provides potential directions for future research. Overall, the goal of the paper is to provide a comprehensive guide to the growing field of IL in robotics and AI.
Uncertainty Aware Neural Network from Similarity and Sensitivity
Apr 27, 2023Researchers have proposed several approaches for neural network (NN) based uncertainty quantification (UQ). However, most of the approaches are developed considering strong assumptions. Uncertainty quantification algorithms often perform poorly in an input domain and the reason for poor performance remains unknown. Therefore, we present a neural network training method that considers similar samples with sensitivity awareness in this paper. In the proposed NN training method for UQ, first, we train a shallow NN for the point prediction. Then, we compute the absolute differences between prediction and targets and train another NN for predicting those absolute differences or absolute errors. Domains with high average absolute errors represent a high uncertainty. In the next step, we select each sample in the training set one by one and compute both prediction and error sensitivities. Then we select similar samples with sensitivity consideration and save indexes of similar samples. The ranges of an input parameter become narrower when the output is highly sensitive to that parameter. After that, we construct initial uncertainty bounds (UB) by considering the distribution of sensitivity aware similar samples. Prediction intervals (PIs) from initial uncertainty bounds are larger and cover more samples than required. Therefore, we train bound correction NN. As following all the steps for finding UB for each sample requires a lot of computation and memory access, we train a UB computation NN. The UB computation NN takes an input sample and provides an uncertainty bound. The UB computation NN is the final product of the proposed approach. Scripts of the proposed method are available in the following GitHub repository: github.com/dipuk0506/UQ
A Review of Deep Learning for Video Captioning
Apr 22, 2023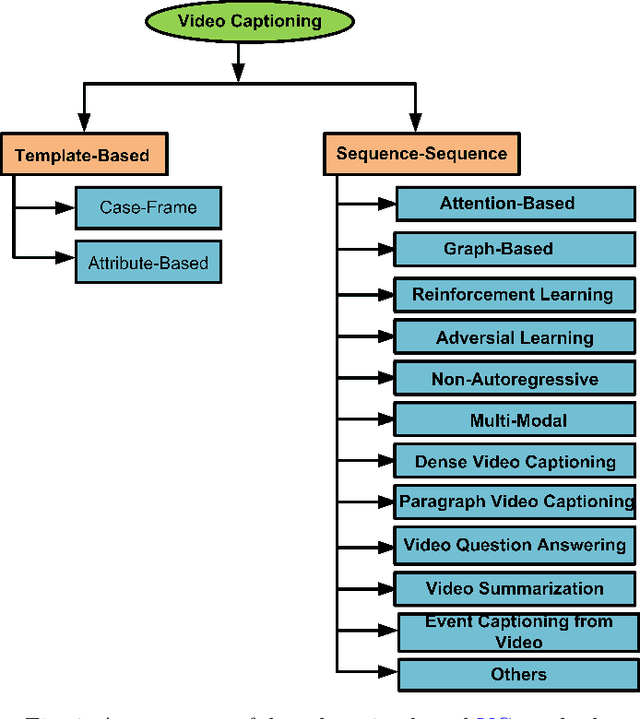
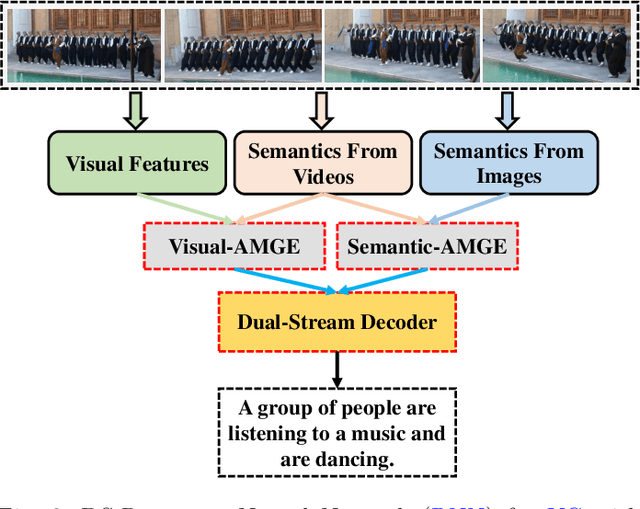
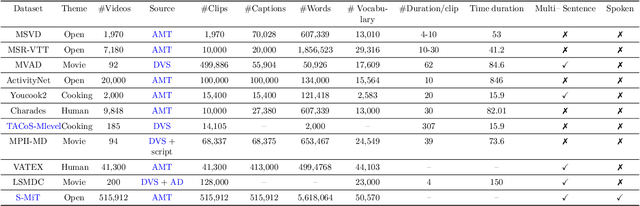
Video captioning (VC) is a fast-moving, cross-disciplinary area of research that bridges work in the fields of computer vision, natural language processing (NLP), linguistics, and human-computer interaction. In essence, VC involves understanding a video and describing it with language. Captioning is used in a host of applications from creating more accessible interfaces (e.g., low-vision navigation) to video question answering (V-QA), video retrieval and content generation. This survey covers deep learning-based VC, including but, not limited to, attention-based architectures, graph networks, reinforcement learning, adversarial networks, dense video captioning (DVC), and more. We discuss the datasets and evaluation metrics used in the field, and limitations, applications, challenges, and future directions for VC.
Survey on Leveraging Uncertainty Estimation Towards Trustworthy Deep Neural Networks: The Case of Reject Option and Post-training Processing
Apr 11, 2023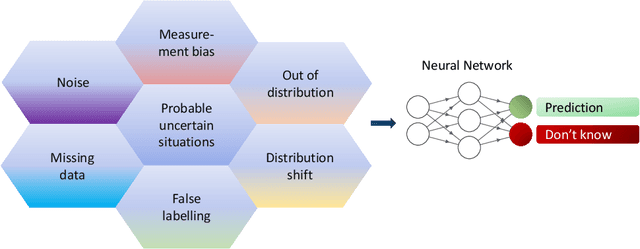
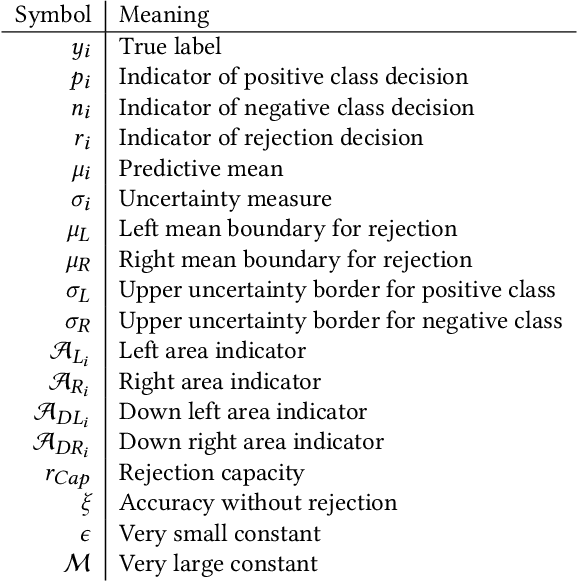
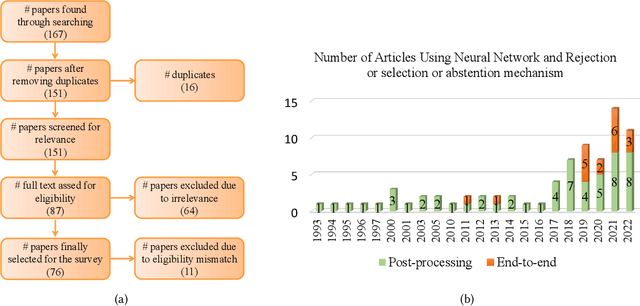

Although neural networks (especially deep neural networks) have achieved \textit{better-than-human} performance in many fields, their real-world deployment is still questionable due to the lack of awareness about the limitation in their knowledge. To incorporate such awareness in the machine learning model, prediction with reject option (also known as selective classification or classification with abstention) has been proposed in literature. In this paper, we present a systematic review of the prediction with the reject option in the context of various neural networks. To the best of our knowledge, this is the first study focusing on this aspect of neural networks. Moreover, we discuss different novel loss functions related to the reject option and post-training processing (if any) of network output for generating suitable measurements for knowledge awareness of the model. Finally, we address the application of the rejection option in reducing the prediction time for the real-time problems and present a comprehensive summary of the techniques related to the reject option in the context of extensive variety of neural networks. Our code is available on GitHub: \url{https://github.com/MehediHasanTutul/Reject_option}
SFE: A Simple, Fast and Efficient Feature Selection Algorithm for High-Dimensional Data
Mar 17, 2023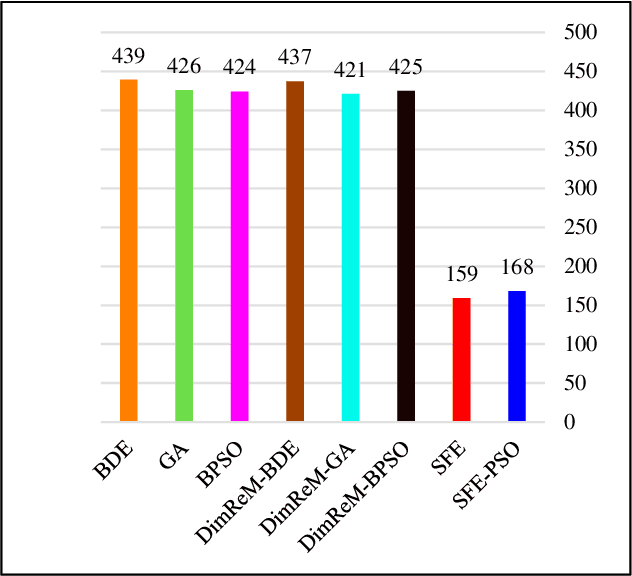

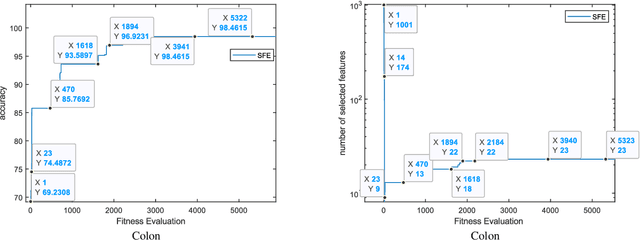
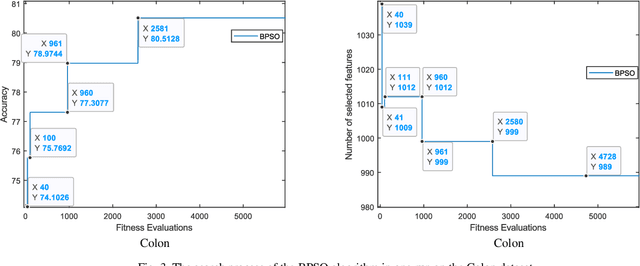
In this paper, a new feature selection algorithm, called SFE (Simple, Fast, and Efficient), is proposed for high-dimensional datasets. The SFE algorithm performs its search process using a search agent and two operators: non-selection and selection. It comprises two phases: exploration and exploitation. In the exploration phase, the non-selection operator performs a global search in the entire problem search space for the irrelevant, redundant, trivial, and noisy features, and changes the status of the features from selected mode to non-selected mode. In the exploitation phase, the selection operator searches the problem search space for the features with a high impact on the classification results, and changes the status of the features from non-selected mode to selected mode. The proposed SFE is successful in feature selection from high-dimensional datasets. However, after reducing the dimensionality of a dataset, its performance cannot be increased significantly. In these situations, an evolutionary computational method could be used to find a more efficient subset of features in the new and reduced search space. To overcome this issue, this paper proposes a hybrid algorithm, SFE-PSO (particle swarm optimization) to find an optimal feature subset. The efficiency and effectiveness of the SFE and the SFE-PSO for feature selection are compared on 40 high-dimensional datasets. Their performances were compared with six recently proposed feature selection algorithms. The results obtained indicate that the two proposed algorithms significantly outperform the other algorithms, and can be used as efficient and effective algorithms in selecting features from high-dimensional datasets.