 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiMotion-LLM: Motion Prediction Instruction Tuning
Jun 11, 2024
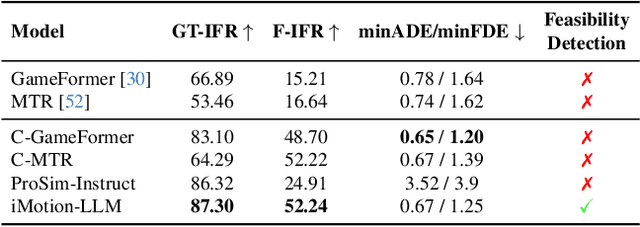
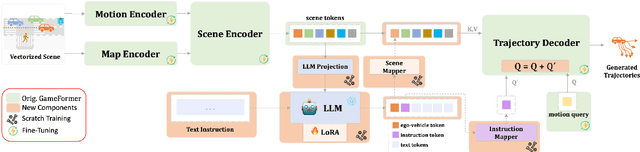

We introduce iMotion-LLM: a Multimodal Large Language Models (LLMs) with trajectory prediction, tailored to guide interactive multi-agent scenarios. Different from conventional motion prediction approaches, iMotion-LLM capitalizes on textual instructions as key inputs for generating contextually relevant trajectories. By enriching the real-world driving scenarios in the Waymo Open Dataset with textual motion instructions, we created InstructWaymo. Leveraging this dataset, iMotion-LLM integrates a pretrained LLM, fine-tuned with LoRA, to translate scene features into the LLM input space. iMotion-LLM offers significant advantages over conventional motion prediction models. First, it can generate trajectories that align with the provided instructions if it is a feasible direction. Second, when given an infeasible direction, it can reject the instruction, thereby enhancing safety. These findings act as milestones in empowering autonomous navigation systems to interpret and predict the dynamics of multi-agent environments, laying the groundwork for future advancements in this field.
A Review of Deep Learning for Video Captioning
Apr 22, 2023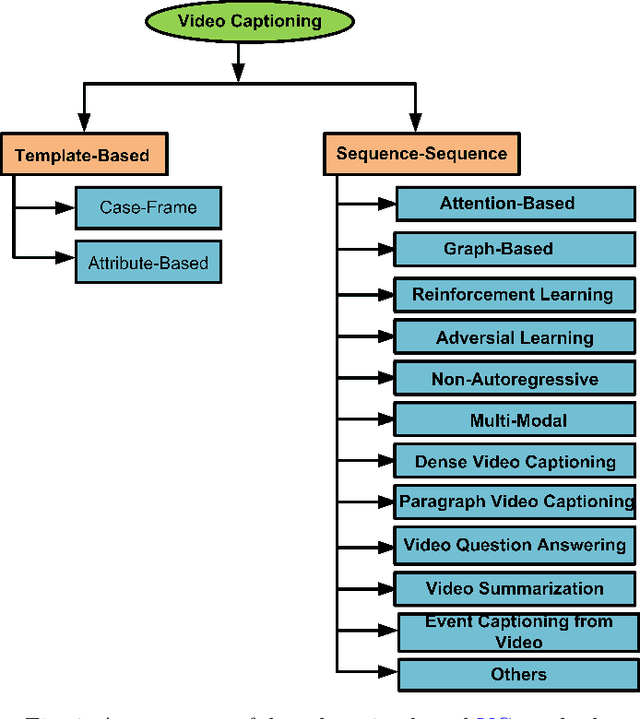
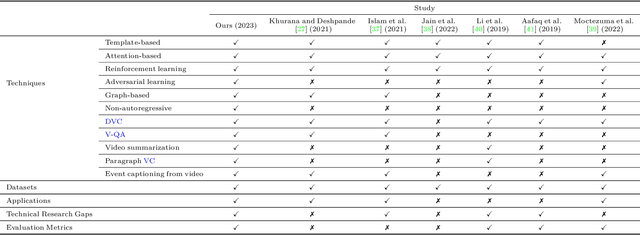
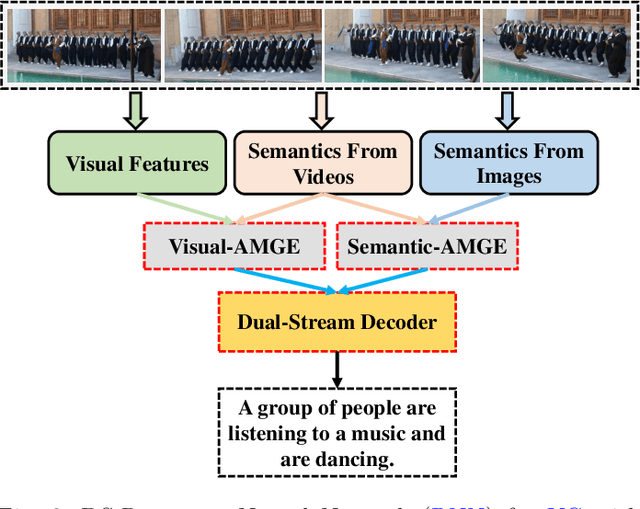
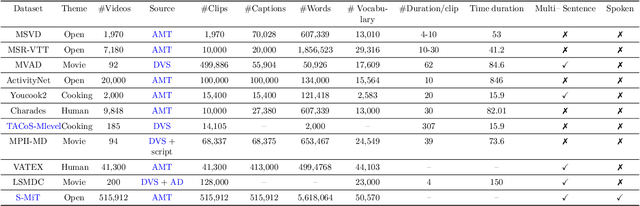
Video captioning (VC) is a fast-moving, cross-disciplinary area of research that bridges work in the fields of computer vision, natural language processing (NLP), linguistics, and human-computer interaction. In essence, VC involves understanding a video and describing it with language. Captioning is used in a host of applications from creating more accessible interfaces (e.g., low-vision navigation) to video question answering (V-QA), video retrieval and content generation. This survey covers deep learning-based VC, including but, not limited to, attention-based architectures, graph networks, reinforcement learning, adversarial networks, dense video captioning (DVC), and more. We discuss the datasets and evaluation metrics used in the field, and limitations, applications, challenges, and future directions for VC.
FollowMe: Vehicle Behaviour Prediction in Autonomous Vehicle Settings
Apr 12, 2023An ego vehicle following a virtual lead vehicle planned route is an essential component when autonomous and non-autonomous vehicles interact. Yet, there is a question about the driver's ability to follow the planned lead vehicle route. Thus, predicting the trajectory of the ego vehicle route given a lead vehicle route is of interest. We introduce a new dataset, the FollowMe dataset, which offers a motion and behavior prediction problem by answering the latter question of the driver's ability to follow a lead vehicle. We also introduce a deep spatio-temporal graph model FollowMe-STGCNN as a baseline for the dataset. In our experiments and analysis, we show the design benefits of FollowMe-STGCNN in capturing the interactions that lie within the dataset. We contrast the performance of FollowMe-STGCNN with prior motion prediction models showing the need to have a different design mechanism to address the lead vehicle following settings.
HAR-GCNN: Deep Graph CNNs for Human Activity Recognition From Highly Unlabeled Mobile Sensor Data
Mar 07, 2022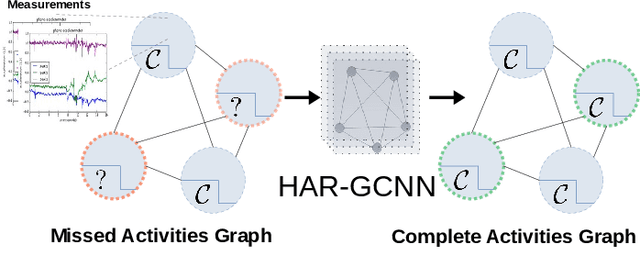
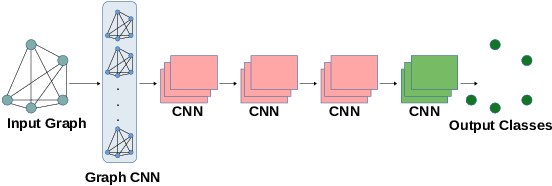
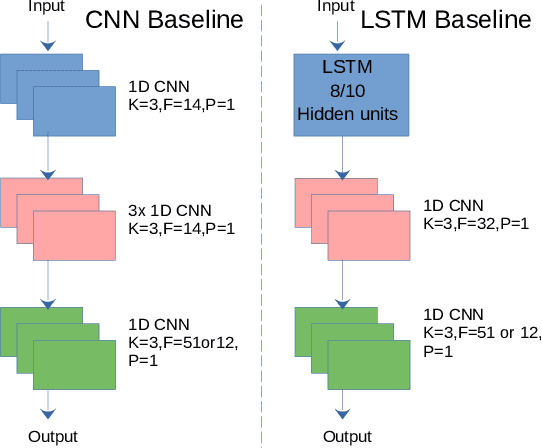
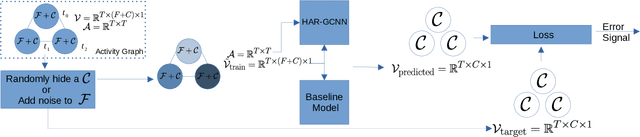
The problem of human activity recognition from mobile sensor data applies to multiple domains, such as health monitoring, personal fitness, daily life logging, and senior care. A critical challenge for training human activity recognition models is data quality. Acquiring balanced datasets containing accurate activity labels requires humans to correctly annotate and potentially interfere with the subjects' normal activities in real-time. Despite the likelihood of incorrect annotation or lack thereof, there is often an inherent chronology to human behavior. For example, we take a shower after we exercise. This implicit chronology can be used to learn unknown labels and classify future activities. In this work, we propose HAR-GCCN, a deep graph CNN model that leverages the correlation between chronologically adjacent sensor measurements to predict the correct labels for unclassified activities that have at least one activity label. We propose a new training strategy enforcing that the model predicts the missing activity labels by leveraging the known ones. HAR-GCCN shows superior performance relative to previously used baseline methods, improving classification accuracy by about 25% and up to 68% on different datasets. Code is available at \url{https://github.com/abduallahmohamed/HAR-GCNN}.
Social-Implicit: Rethinking Trajectory Prediction Evaluation and The Effectiveness of Implicit Maximum Likelihood Estimation
Mar 06, 2022
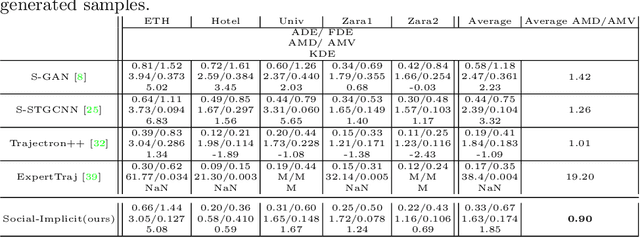
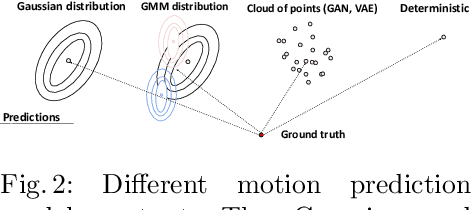

Best-of-N (BoN) Average Displacement Error (ADE)/ Final Displacement Error (FDE) is the most used metric for evaluating trajectory prediction models. Yet, the BoN does not quantify the whole generated samples, resulting in an incomplete view of the model's prediction quality and performance. We propose a new metric, Average Mahalanobis Distance (AMD) to tackle this issue. AMD is a metric that quantifies how close the whole generated samples are to the ground truth. We also introduce the Average Maximum Eigenvalue (AMV) metric that quantifies the overall spread of the predictions. Our metrics are validated empirically by showing that the ADE/FDE is not sensitive to distribution shifts, giving a biased sense of accuracy, unlike the AMD/AMV metrics. We introduce the usage of Implicit Maximum Likelihood Estimation (IMLE) as a replacement for traditional generative models to train our model, Social-Implicit. IMLE training mechanism aligns with AMD/AMV objective of predicting trajectories that are close to the ground truth with a tight spread. Social-Implicit is a memory efficient deep model with only 5.8K parameters that runs in real time of about 580Hz and achieves competitive results. Interactive demo of the problem can be seen here \url{https://www.abduallahmohamed.com/social-implicit-amdamv-adefde-demo}. Code is available at \url{https://github.com/abduallahmohamed/Social-Implicit}.
Skeleton-Graph: Long-Term 3D Motion Prediction From 2D Observations Using Deep Spatio-Temporal Graph CNNs
Sep 27, 2021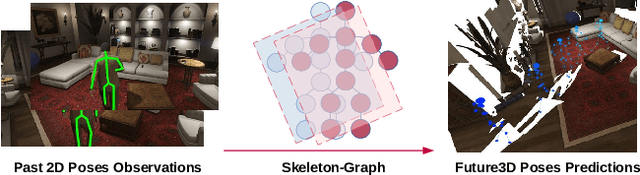
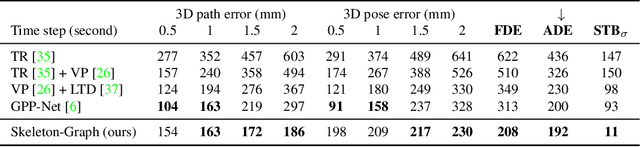
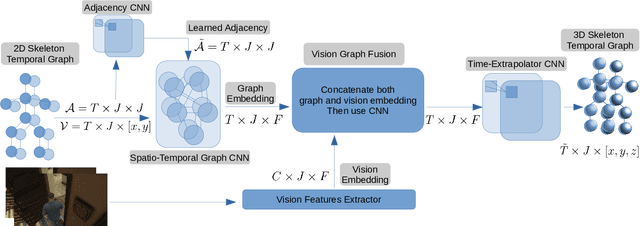
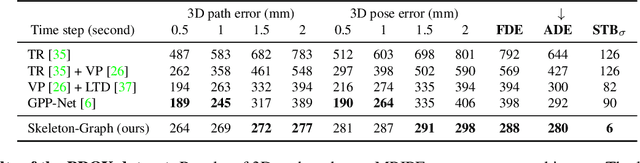
Several applications such as autonomous driving, augmented reality and virtual reality require a precise prediction of the 3D human pose. Recently, a new problem was introduced in the field to predict the 3D human poses from observed 2D poses. We propose Skeleton-Graph, a deep spatio-temporal graph CNN model that predicts the future 3D skeleton poses in a single pass from the 2D ones. Unlike prior works, Skeleton-Graph focuses on modeling the interaction between the skeleton joints by exploiting their spatial configuration. This is being achieved by formulating the problem as a graph structure while learning a suitable graph adjacency kernel. By the design, Skeleton-Graph predicts the future 3D poses without divergence in the long-term, unlike prior works. We also introduce a new metric that measures the divergence of predictions in the long term. Our results show an FDE improvement of at least 27% and an ADE of 4% on both the GTA-IM and PROX datasets respectively in comparison with prior works. Also, we are 88% and 93% less divergence on the long-term motion prediction in comparison with prior works on both GTA-IM and PROX datasets. Code is available at https://github.com/abduallahmohamed/Skeleton-Graph.git
Inner Ensemble Nets
Jun 15, 2020
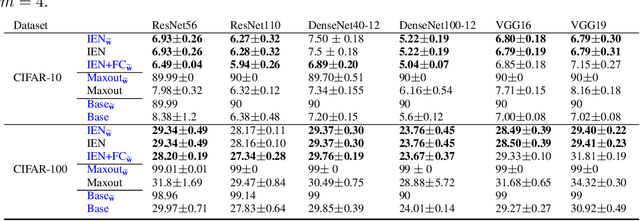
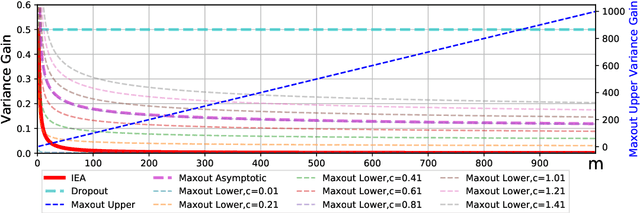
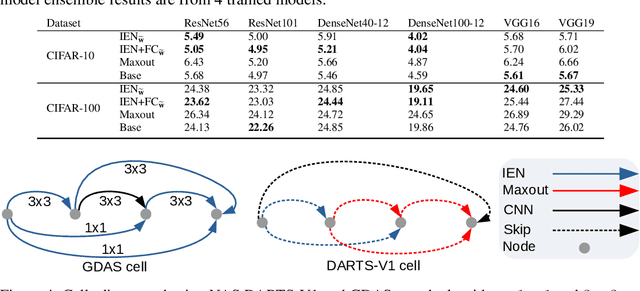
We introduce Inner Ensemble Networks (IENs) which reduce the variance within the neural network itself without an increase in the model complexity. IENs utilize ensemble parameters during the training phase to reduce the network variance. While in the testing phase, these parameters are removed without a change in the enhanced performance. IENs reduce the variance of an ordinary deep model by a factor of $1/m^{L-1}$, where $m$ is the number of inner ensembles and $L$ is the depth of the model. Also, we show empirically and theoretically that IENs lead to a greater variance reduction in comparison with other similar approaches such as dropout and maxout. Our results show a decrease of error rates between 1.7\% and 17.3\% in comparison with an ordinary deep model. Code is available at \url{https://github.com/abduallahmohamed/inner_ensemble_nets.git}.
Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction
Mar 24, 2020

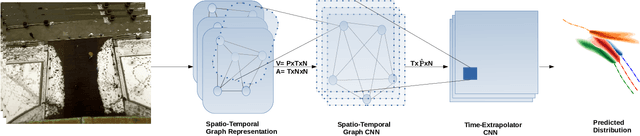
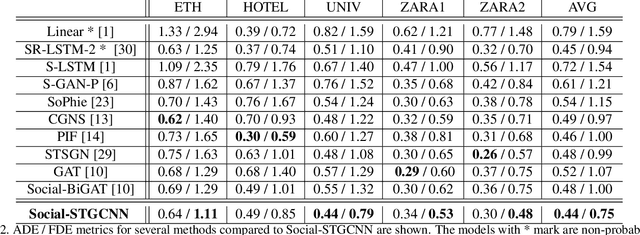
Better machine understanding of pedestrian behaviors enables faster progress in modeling interactions between agents such as autonomous vehicles and humans. Pedestrian trajectories are not only influenced by the pedestrian itself but also by interaction with surrounding objects. Previous methods modeled these interactions by using a variety of aggregation methods that integrate different learned pedestrians states. We propose the Social Spatio-Temporal Graph Convolutional Neural Network (Social-STGCNN), which substitutes the need of aggregation methods by modeling the interactions as a graph. Our results show an improvement over the state of art by 20% on the Final Displacement Error (FDE) and an improvement on the Average Displacement Error (ADE) with 8.5 times less parameters and up to 48 times faster inference speed than previously reported methods. In addition, our model is data efficient, and exceeds previous state of the art on the ADE metric with only 20% of the training data. We propose a kernel function to embed the social interactions between pedestrians within the adjacency matrix. Through qualitative analysis, we show that our model inherited social behaviors that can be expected between pedestrians trajectories. Code is available at https://github.com/abduallahmohamed/Social-STGCNN.
Physics Informed Data Driven model for Flood Prediction: Application of Deep Learning in prediction of urban flood development
Aug 23, 2019
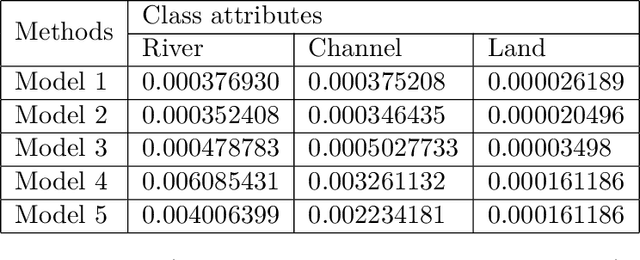
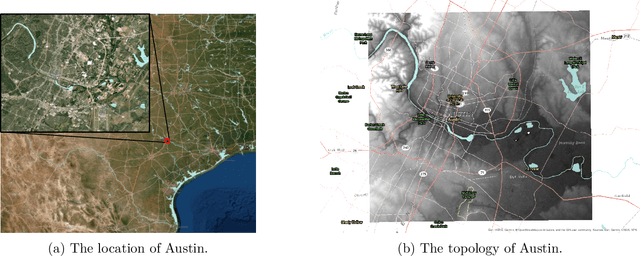

Flash floods in urban areas occur with increasing frequency. Detecting these floods would greatlyhelp alleviate human and economic losses. However, current flood prediction methods are eithertoo slow or too simplified to capture the flood development in details. Using Deep Neural Networks,this work aims at boosting the computational speed of a physics-based 2-D urban flood predictionmethod, governed by the Shallow Water Equation (SWE). Convolutional Neural Networks(CNN)and conditional Generative Adversarial Neural Networks(cGANs) are applied to extract the dy-namics of flood from the data simulated by a Partial Differential Equation(PDE) solver. Theperformance of the data-driven model is evaluated in terms of Mean Squared Error(MSE) andPeak Signal to Noise Ratio(PSNR). The deep learning-based, data-driven flood prediction modelis shown to be able to provide precise real-time predictions of flood development