 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation-Preserving Adaptation via Generalized Rayleigh-Quotient Optimization
May 28, 2026While finetuning effectively adapts foundation models to specialized downstream tasks, it can degrade nontarget capabilities acquired during pretraining. Existing forgetting aware methods typically seek safer updates through specialized initialization or fixed constraints, but do not regulate the adaptation preservation trade-off during training. We propose Foundation Preserving LoRA (FoLoRA), a forgetting aware optimization framework. Guided by a first order preservation condition, FoLoRA defines a forgetting penalty over pretraining-proxy activations and a task utility over downstream task activations. It then scores update directions by task utility per unit forgetting penalty via a generalized Rayleigh quotient. The resulting spectral coordinate system enables direction wise gated Adam updates, attenuating low utility to penalty directions during training. To estimate the forgetting penalty, FoLoRA constructs pretraining proxy calibration data by sampling from the pretrained model rather than relying on a single proxy dataset. Experiments on math, code, and instruction following adaptation show that FoLoRA achieves the strongest preservation adaptation balance over baselines, improving target task performance with best aggregate preservation of non target capabilities.
Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
Mar 04, 2026Large language model (LLM) agents are fundamentally bottlenecked by finite context windows on long-horizon tasks. As trajectories grow, retaining tool outputs and intermediate reasoning in-context quickly becomes infeasible: the working context becomes prohibitively long, eventually exceeds the context budget, and makes distant evidence harder to use even when it is still present. Existing solutions typically shorten context through truncation or running summaries, but these methods are fundamentally lossy because they compress or discard past evidence itself. We introduce Memex, an indexed experience memory mechanism that instead compresses context without discarding evidence. Memex maintains a compact working context consisting of concise structured summaries and stable indices, while storing full-fidelity underlying interactions in an external experience database under those indices. The agent can then decide when to dereference an index and recover the exact past evidence needed for the current subgoal. We optimize both write and read behaviors with our reinforcement learning framework MemexRL, using reward shaping tailored to indexed memory usage under a context budget, so the agent learns what to summarize, what to archive, how to index it, and when to retrieve it. This yields a substantially less lossy form of long-horizon memory than summary-only approaches. We further provide a theoretical analysis showing the potential of the Memex loop to preserve decision quality with bounded dereferencing while keeping effective in-context computation bounded as history grows. Empirically, on challenging long-horizon tasks, Memex agent trained with MemexRL improves task success while using a significantly smaller working context.
Regularized Calibration with Successive Rounding for Post-Training Quantization
Feb 05, 2026Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.
Boundary Attention Constrained Zero-Shot Layout-To-Image Generation
Nov 15, 2024



Recent text-to-image diffusion models excel at generating high-resolution images from text but struggle with precise control over spatial composition and object counting. To address these challenges, several studies developed layout-to-image (L2I) approaches that incorporate layout instructions into text-to-image models. However, existing L2I methods typically require either fine-tuning pretrained parameters or training additional control modules for the diffusion models. In this work, we propose a novel zero-shot L2I approach, BACON (Boundary Attention Constrained generation), which eliminates the need for additional modules or fine-tuning. Specifically, we use text-visual cross-attention feature maps to quantify inconsistencies between the layout of the generated images and the provided instructions, and then compute loss functions to optimize latent features during the diffusion reverse process. To enhance spatial controllability and mitigate semantic failures in complex layout instructions, we leverage pixel-to-pixel correlations in the self-attention feature maps to align cross-attention maps and combine three loss functions constrained by boundary attention to update latent features. Comprehensive experimental results on both L2I and non-L2I pretrained diffusion models demonstrate that our method outperforms existing zero-shot L2I techniuqes both quantitatively and qualitatively in terms of image composition on the DrawBench and HRS benchmarks.
Dual Low-Rank Adaptation for Continual Learning with Pre-Trained Models
Nov 01, 2024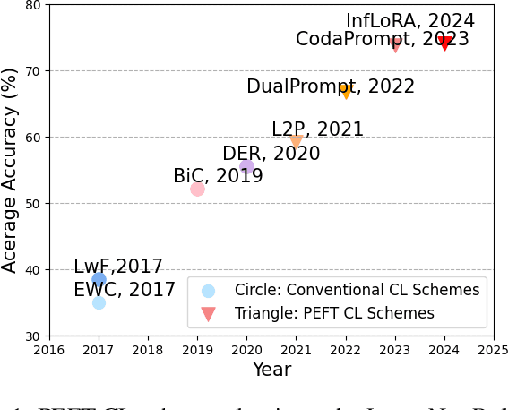
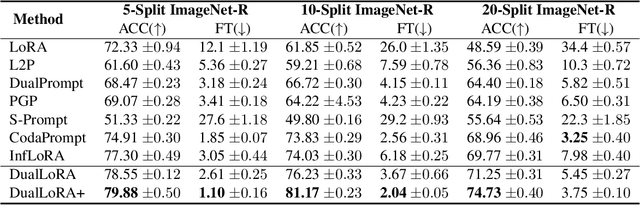
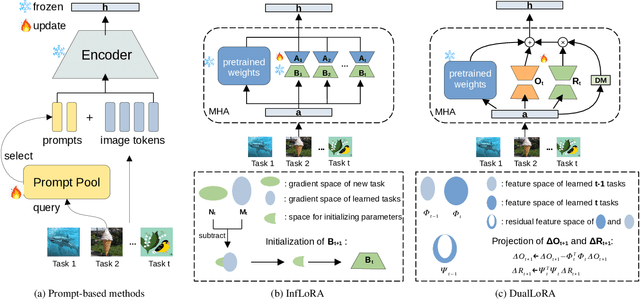
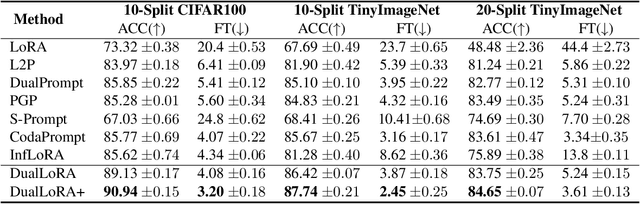
In the era of foundation models, we revisit continual learning~(CL), which aims to enable vision transformers (ViTs) to learn new tasks over time. However, as the scale of these models increases, catastrophic forgetting remains a persistent challenge, particularly in the presence of significant domain shifts across tasks. Recent studies highlight a crossover between CL techniques and parameter-efficient fine-tuning (PEFT), which focuses on fine-tuning only a small set of trainable parameters to adapt to downstream tasks, such as low-rank adaptation (LoRA). While LoRA achieves faster convergence and requires fewer trainable parameters, it has seldom been explored in the context of continual learning. To address this gap, we propose a novel PEFT-CL method called Dual Low-Rank Adaptation (DualLoRA), which introduces both an orthogonal LoRA adapter and a residual LoRA adapter parallel to pre-trained weights in each layer. These components are orchestrated by a dynamic memory mechanism to strike a balance between stability and plasticity. The orthogonal LoRA adapter's parameters are updated in an orthogonal subspace of previous tasks to mitigate catastrophic forgetting, while the residual LoRA adapter's parameters are updated in the residual subspace spanned by task-specific bases without interaction across tasks, offering complementary capabilities for fine-tuning new tasks. On ViT-based models, we demonstrate that DualLoRA offers significant advantages in accuracy, inference speed, and memory efficiency over existing CL methods across multiple benchmarks.
Recovering Labels from Local Updates in Federated Learning
May 02, 2024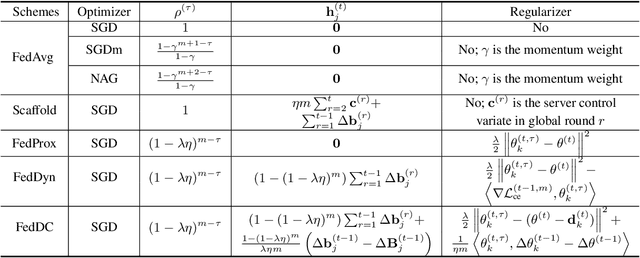
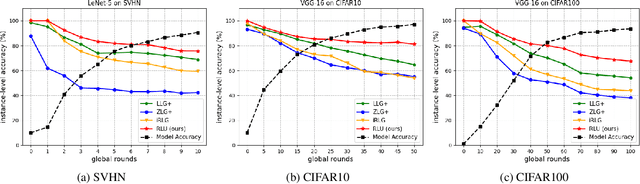
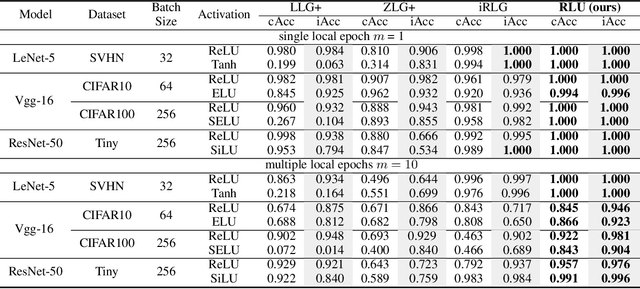
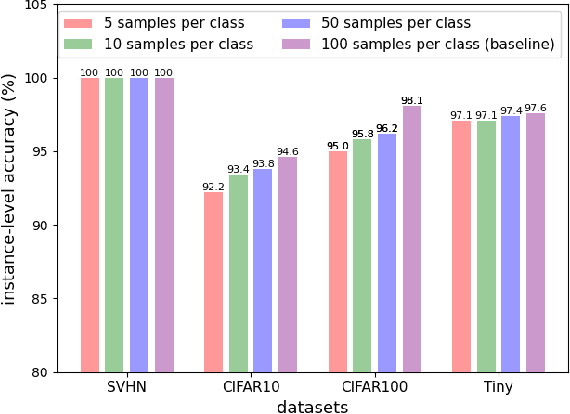
Gradient inversion (GI) attacks present a threat to the privacy of clients in federated learning (FL) by aiming to enable reconstruction of the clients' data from communicated model updates. A number of such techniques attempts to accelerate data recovery by first reconstructing labels of the samples used in local training. However, existing label extraction methods make strong assumptions that typically do not hold in realistic FL settings. In this paper we present a novel label recovery scheme, Recovering Labels from Local Updates (RLU), which provides near-perfect accuracy when attacking untrained (most vulnerable) models. More significantly, RLU achieves high performance even in realistic real-world settings where the clients in an FL system run multiple local epochs, train on heterogeneous data, and deploy various optimizers to minimize different objective functions. Specifically, RLU estimates labels by solving a least-square problem that emerges from the analysis of the correlation between labels of the data points used in a training round and the resulting update of the output layer. The experimental results on several datasets, architectures, and data heterogeneity scenarios demonstrate that the proposed method consistently outperforms existing baselines, and helps improve quality of the reconstructed images in GI attacks in terms of both PSNR and LPIPS.
Mixed-Precision Quantization for Federated Learning on Resource-Constrained Heterogeneous Devices
Nov 29, 2023While federated learning (FL) systems often utilize quantization to battle communication and computational bottlenecks, they have heretofore been limited to deploying fixed-precision quantization schemes. Meanwhile, the concept of mixed-precision quantization (MPQ), where different layers of a deep learning model are assigned varying bit-width, remains unexplored in the FL settings. We present a novel FL algorithm, FedMPQ, which introduces mixed-precision quantization to resource-heterogeneous FL systems. Specifically, local models, quantized so as to satisfy bit-width constraint, are trained by optimizing an objective function that includes a regularization term which promotes reduction of precision in some of the layers without significant performance degradation. The server collects local model updates, de-quantizes them into full-precision models, and then aggregates them into a global model. To initialize the next round of local training, the server relies on the information learned in the previous training round to customize bit-width assignments of the models delivered to different clients. In extensive benchmarking experiments on several model architectures and different datasets in both iid and non-iid settings, FedMPQ outperformed the baseline FL schemes that utilize fixed-precision quantization while incurring only a minor computational overhead on the participating devices.
Accelerating Non-IID Federated Learning via Heterogeneity-Guided Client Sampling
Sep 30, 2023Statistical heterogeneity of data present at client devices in a federated learning (FL) system renders the training of a global model in such systems difficult. Particularly challenging are the settings where due to resource constraints only a small fraction of clients can participate in any given round of FL. Recent approaches to training a global model in FL systems with non-IID data have focused on developing client selection methods that aim to sample clients with more informative updates of the model. However, existing client selection techniques either introduce significant computation overhead or perform well only in the scenarios where clients have data with similar heterogeneity profiles. In this paper, we propose HiCS-FL (Federated Learning via Hierarchical Clustered Sampling), a novel client selection method in which the server estimates statistical heterogeneity of a client's data using the client's update of the network's output layer and relies on this information to cluster and sample the clients. We analyze the ability of the proposed techniques to compare heterogeneity of different datasets, and characterize convergence of the training process that deploys the introduced client selection method. Extensive experimental results demonstrate that in non-IID settings HiCS-FL achieves faster convergence and lower training variance than state-of-the-art FL client selection schemes. Notably, HiCS-FL drastically reduces computation cost compared to existing selection schemes and is adaptable to different heterogeneity scenarios.
The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation
Jan 21, 2023



Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model's accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions -- information that we refer to as ``hyper-knowledge". The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.
Federated Learning in Non-IID Settings Aided by Differentially Private Synthetic Data
Jun 01, 2022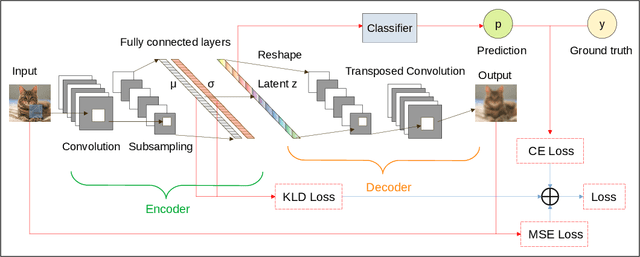
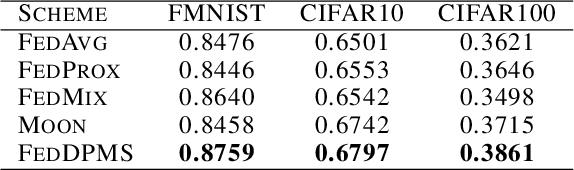
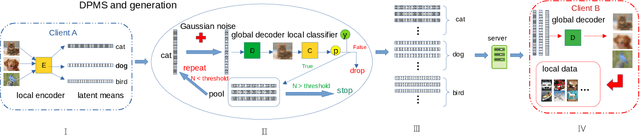
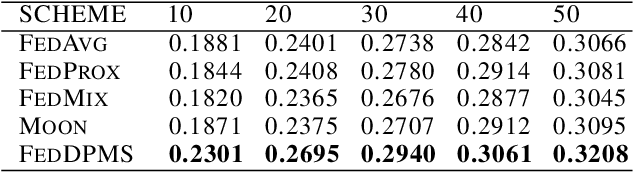
Federated learning (FL) is a privacy-promoting framework that enables potentially large number of clients to collaboratively train machine learning models. In a FL system, a server coordinates the collaboration by collecting and aggregating clients' model updates while the clients' data remains local and private. A major challenge in federated learning arises when the local data is heterogeneous -- the setting in which performance of the learned global model may deteriorate significantly compared to the scenario where the data is identically distributed across the clients. In this paper we propose FedDPMS (Federated Differentially Private Means Sharing), an FL algorithm in which clients deploy variational auto-encoders to augment local datasets with data synthesized using differentially private means of latent data representations communicated by a trusted server. Such augmentation ameliorates effects of data heterogeneity across the clients without compromising privacy. Our experiments on deep image classification tasks demonstrate that FedDPMS outperforms competing state-of-the-art FL methods specifically designed for heterogeneous data settings.