 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRan Score: a LLM-based Evaluation Score for Radiology Report Generation
Mar 24, 2026Chest X-ray report generation and automated evaluation are limited by poor recognition of low-prevalence abnormalities and inadequate handling of clinically important language, including negation and ambiguity. We develop a clinician-guided framework combining human expertise and large language models for multi-label finding extraction from free-text chest X-ray reports and use it to define Ran Score, a finding-level metric for report evaluation. Using three non-overlapping MIMIC-CXR-EN cohorts from a public chest X-ray dataset and an independent ChestX-CN validation cohort, we optimize prompts, establish radiologist-derived reference labels and evaluate report generation models. The optimized framework improves the macro-averaged score from 0.753 to 0.956 on the MIMIC-CXR-EN development cohort, exceeds the CheXbert benchmark by 15.7 percentage points on directly comparable labels, and shows robust generalization on the ChestX-CN validation cohort. Here we show that clinician-guided prompt optimization improves agreement with a radiologist-derived reference standard and that Ran Score enables finding-level evaluation of report fidelity, particularly for low-prevalence abnormalities.
UniCompress: Token Compression for Unified Vision-Language Understanding and Generation
Mar 11, 2026Unified models aim to support both understanding and generation by encoding images into discrete tokens and processing them alongside text within a single autoregressive framework. This unified design offers architectural simplicity and cross-modal synergy, which facilitates shared parameterization, consistent training objectives, and seamless transfer between modalities. However, the large number of visual tokens required by such models introduces substantial computation and memory overhead, and this inefficiency directly hinders deployment in resource constrained scenarios such as embodied AI systems. In this work, we propose a unified token compression algorithm UniCompress that significantly reduces visual token count while preserving performance on both image understanding and generation tasks. Our method introduces a plug-in compression and decompression mechanism guided with learnable global meta tokens. The framework is lightweight and modular, enabling efficient integration into existing models without full retraining. Experimental results show that our approach reduces image tokens by up to 4 times, achieves substantial gains in inference latency and training cost, and incurs only minimal performance degradation, which demonstrates the promise of token-efficient unified modeling for real world multimodal applications.
Unlocking Cognitive Capabilities and Analyzing the Perception-Logic Trade-off
Feb 27, 2026Recent advancements in Multimodal Large Language Models (MLLMs) pursue omni-perception capabilities, yet integrating robust sensory grounding with complex reasoning remains a challenge, particularly for underrepresented regions. In this report, we introduce the research preview of MERaLiON2-Omni (Alpha), a 10B-parameter multilingual omni-perception tailored for Southeast Asia (SEA). We present a progressive training pipeline that explicitly decouples and then integrates "System 1" (Perception) and "System 2" (Reasoning) capabilities. First, we establish a robust Perception Backbone by aligning region-specific audio-visual cues (e.g., Singlish code-switching, local cultural landmarks) with a multilingual LLM through orthogonal modality adaptation. Second, to inject cognitive capabilities without large-scale supervision, we propose a cost-effective Generate-Judge-Refine pipeline. By utilizing a Super-LLM to filter hallucinations and resolve conflicts via a consensus mechanism, we synthesize high-quality silver data that transfers textual Chain-of-Thought reasoning to multimodal scenarios. Comprehensive evaluation on our newly introduced SEA-Omni Benchmark Suite reveals an Efficiency-Stability Paradox: while reasoning acts as a non-linear amplifier for abstract tasks (boosting mathematical and instruction-following performance significantly), it introduces instability in low-level sensory processing. Specifically, we identify Temporal Drift in long-context audio, where extended reasoning desynchronizes the model from acoustic timestamps, and Visual Over-interpretation, where logic overrides pixel-level reality. This report details the architecture, the data-efficient training recipe, and a diagnostic analysis of the trade-offs between robust perception and structured reasoning.
StelLA: Subspace Learning in Low-rank Adaptation using Stiefel Manifold
Oct 02, 2025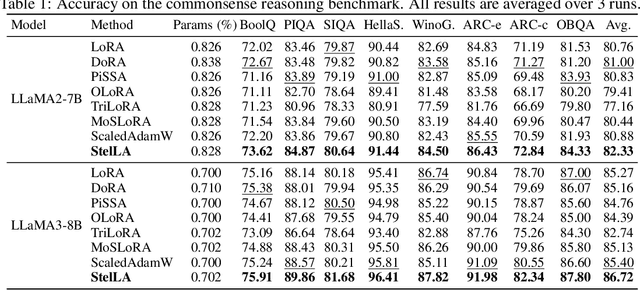
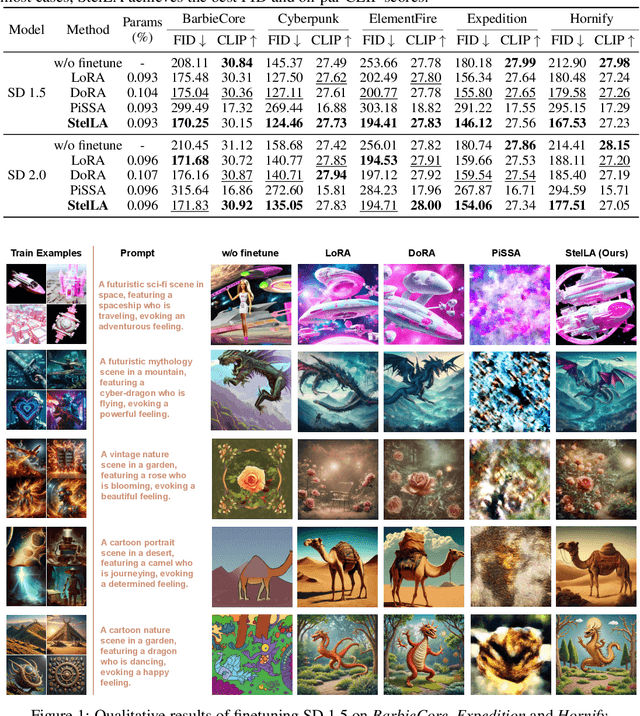
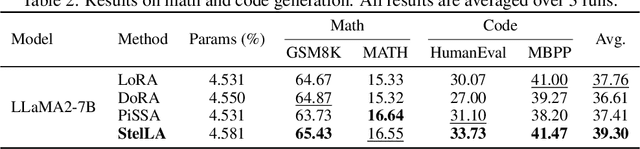
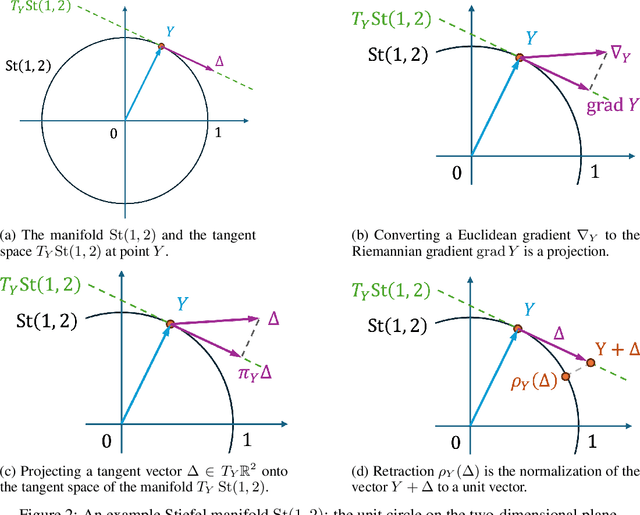
Low-rank adaptation (LoRA) has been widely adopted as a parameter-efficient technique for fine-tuning large-scale pre-trained models. However, it still lags behind full fine-tuning in performance, partly due to its insufficient exploitation of the geometric structure underlying low-rank manifolds. In this paper, we propose a geometry-aware extension of LoRA that uses a three-factor decomposition $U\!SV^\top$. Analogous to the structure of singular value decomposition (SVD), it separates the adapter's input and output subspaces, $V$ and $U$, from the scaling factor $S$. Our method constrains $U$ and $V$ to lie on the Stiefel manifold, ensuring their orthonormality throughout the training. To optimize on the Stiefel manifold, we employ a flexible and modular geometric optimization design that converts any Euclidean optimizer to a Riemannian one. It enables efficient subspace learning while remaining compatible with existing fine-tuning pipelines. Empirical results across a wide range of downstream tasks, including commonsense reasoning, math and code generation, image classification, and image generation, demonstrate the superior performance of our approach against the recent state-of-the-art variants of LoRA. Code is available at https://github.com/SonyResearch/stella.
UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models
Aug 27, 2025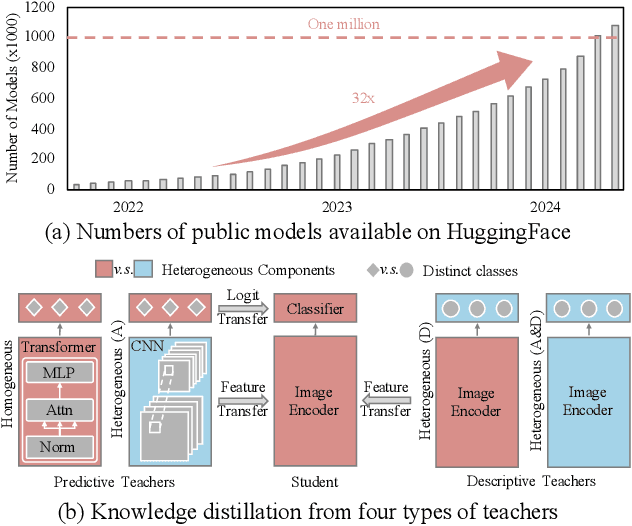
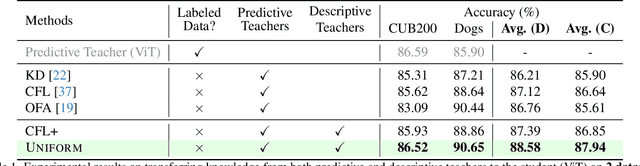
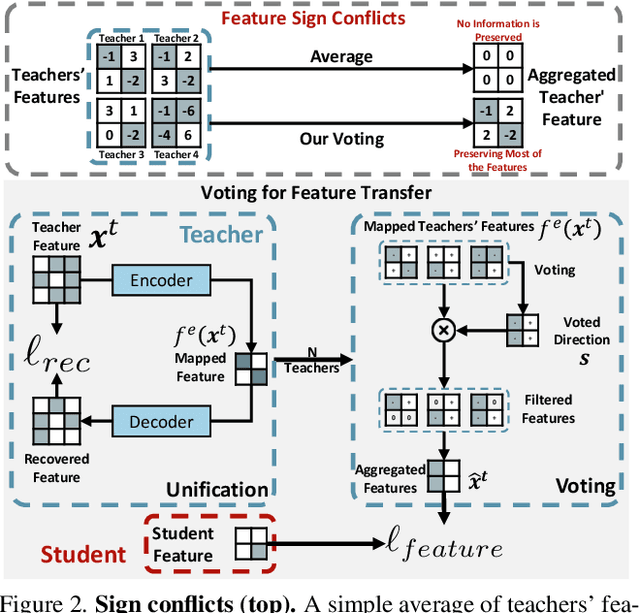
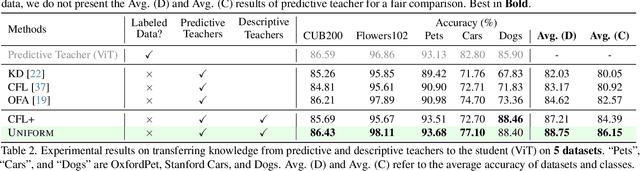
In the era of deep learning, the increasing number of pre-trained models available online presents a wealth of knowledge. These models, developed with diverse architectures and trained on varied datasets for different tasks, provide unique interpretations of the real world. Their collective consensus is likely universal and generalizable to unseen data. However, effectively harnessing this collective knowledge poses a fundamental challenge due to the heterogeneity of pre-trained models. Existing knowledge integration solutions typically rely on strong assumptions about training data distributions and network architectures, limiting them to learning only from specific types of models and resulting in data and/or inductive biases. In this work, we introduce a novel framework, namely UNIFORM, for knowledge transfer from a diverse set of off-the-shelf models into one student model without such constraints. Specifically, we propose a dedicated voting mechanism to capture the consensus of knowledge both at the logit level -- incorporating teacher models that are capable of predicting target classes of interest -- and at the feature level, utilizing visual representations learned on arbitrary label spaces. Extensive experiments demonstrate that UNIFORM effectively enhances unsupervised object recognition performance compared to strong knowledge transfer baselines. Notably, it exhibits remarkable scalability by benefiting from over one hundred teachers, while existing methods saturate at a much smaller scale.
HyperFree: A Channel-adaptive and Tuning-free Foundation Model for Hyperspectral Remote Sensing Imagery
Mar 27, 2025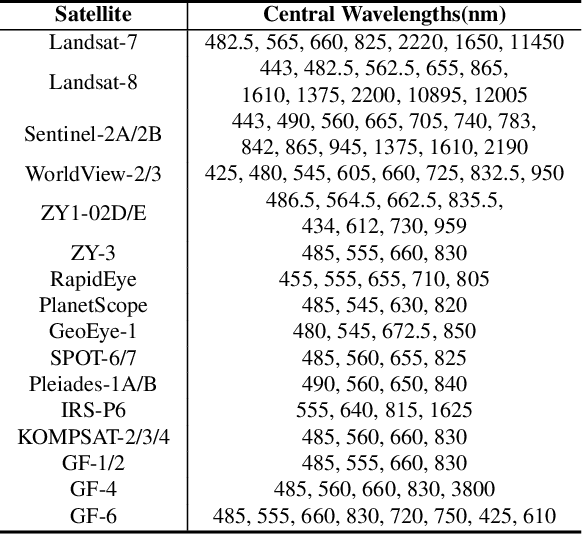
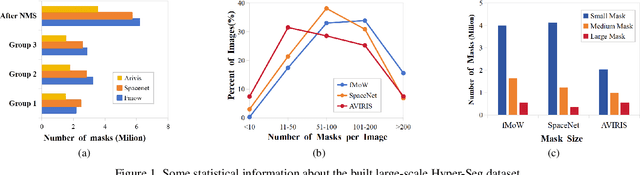
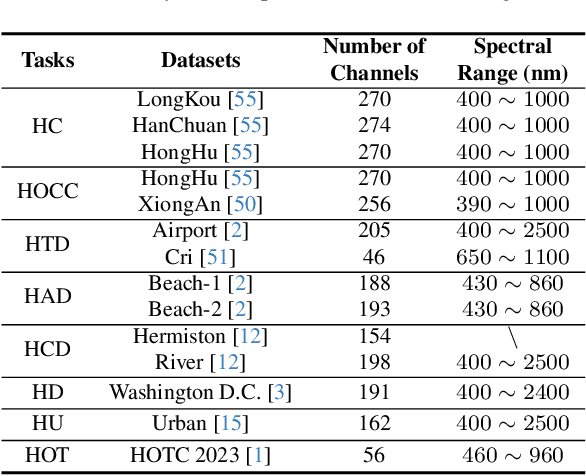
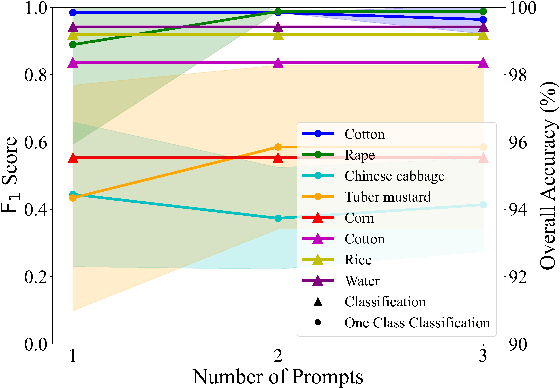
Advanced interpretation of hyperspectral remote sensing images benefits many precise Earth observation tasks. Recently, visual foundation models have promoted the remote sensing interpretation but concentrating on RGB and multispectral images. Due to the varied hyperspectral channels,existing foundation models would face image-by-image tuning situation, imposing great pressure on hardware and time resources. In this paper, we propose a tuning-free hyperspectral foundation model called HyperFree, by adapting the existing visual prompt engineering. To process varied channel numbers, we design a learned weight dictionary covering full-spectrum from $0.4 \sim 2.5 \, \mu\text{m}$, supporting to build the embedding layer dynamically. To make the prompt design more tractable, HyperFree can generate multiple semantic-aware masks for one prompt by treating feature distance as semantic-similarity. After pre-training HyperFree on constructed large-scale high-resolution hyperspectral images, HyperFree (1 prompt) has shown comparable results with specialized models (5 shots) on 5 tasks and 11 datasets.Code and dataset are accessible at https://rsidea.whu.edu.cn/hyperfree.htm.
HOpenCls: Training Hyperspectral Image Open-Set Classifiers in Their Living Environments
Feb 21, 2025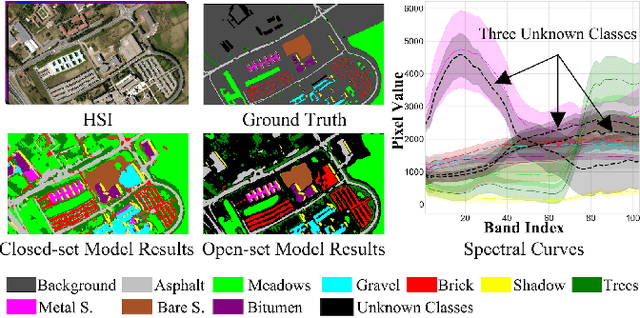
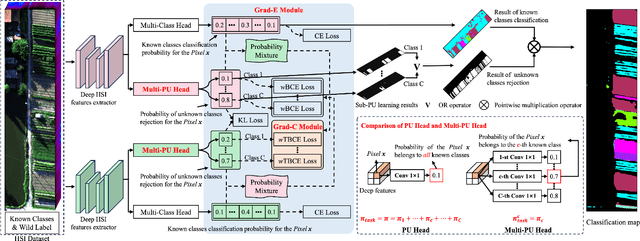
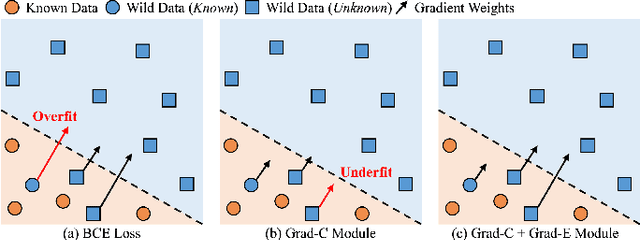

Hyperspectral image (HSI) open-set classification is critical for HSI classification models deployed in real-world environments, where classifiers must simultaneously classify known classes and reject unknown classes. Recent methods utilize auxiliary unknown classes data to improve classification performance. However, the auxiliary unknown classes data is strongly assumed to be completely separable from known classes and requires labor-intensive annotation. To address this limitation, this paper proposes a novel framework, HOpenCls, to leverage the unlabeled wild data-that is the mixture of known and unknown classes. Such wild data is abundant and can be collected freely during deploying classifiers in their living environments. The key insight is reformulating the open-set HSI classification with unlabeled wild data as a positive-unlabeled (PU) learning problem. Specifically, the multi-label strategy is introduced to bridge the PU learning and open-set HSI classification, and then the proposed gradient contraction and gradient expansion module to make this PU learning problem tractable from the observation of abnormal gradient weights associated with wild data. Extensive experiment results demonstrate that incorporating wild data has the potential to significantly enhance open-set HSI classification in complex real-world scenarios.
Boundary Attention Constrained Zero-Shot Layout-To-Image Generation
Nov 15, 2024



Recent text-to-image diffusion models excel at generating high-resolution images from text but struggle with precise control over spatial composition and object counting. To address these challenges, several studies developed layout-to-image (L2I) approaches that incorporate layout instructions into text-to-image models. However, existing L2I methods typically require either fine-tuning pretrained parameters or training additional control modules for the diffusion models. In this work, we propose a novel zero-shot L2I approach, BACON (Boundary Attention Constrained generation), which eliminates the need for additional modules or fine-tuning. Specifically, we use text-visual cross-attention feature maps to quantify inconsistencies between the layout of the generated images and the provided instructions, and then compute loss functions to optimize latent features during the diffusion reverse process. To enhance spatial controllability and mitigate semantic failures in complex layout instructions, we leverage pixel-to-pixel correlations in the self-attention feature maps to align cross-attention maps and combine three loss functions constrained by boundary attention to update latent features. Comprehensive experimental results on both L2I and non-L2I pretrained diffusion models demonstrate that our method outperforms existing zero-shot L2I techniuqes both quantitatively and qualitatively in terms of image composition on the DrawBench and HRS benchmarks.
Dual Low-Rank Adaptation for Continual Learning with Pre-Trained Models
Nov 01, 2024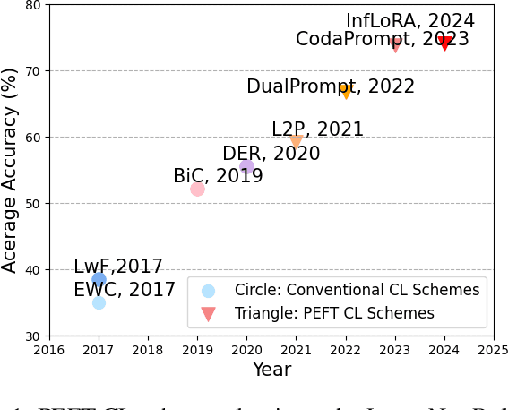
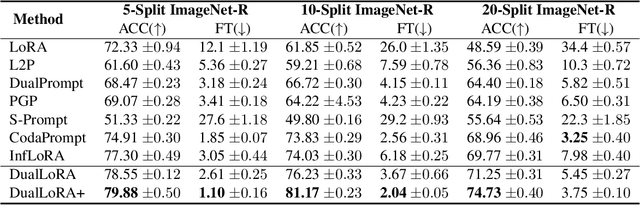
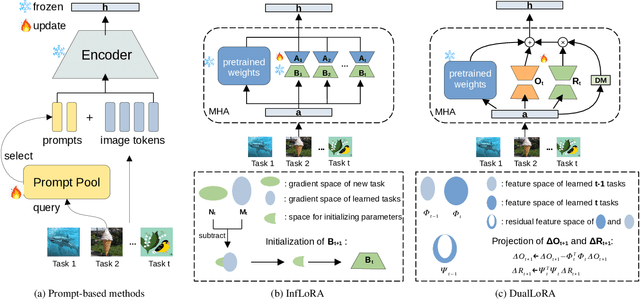
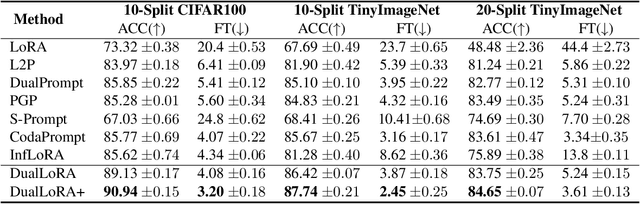
In the era of foundation models, we revisit continual learning~(CL), which aims to enable vision transformers (ViTs) to learn new tasks over time. However, as the scale of these models increases, catastrophic forgetting remains a persistent challenge, particularly in the presence of significant domain shifts across tasks. Recent studies highlight a crossover between CL techniques and parameter-efficient fine-tuning (PEFT), which focuses on fine-tuning only a small set of trainable parameters to adapt to downstream tasks, such as low-rank adaptation (LoRA). While LoRA achieves faster convergence and requires fewer trainable parameters, it has seldom been explored in the context of continual learning. To address this gap, we propose a novel PEFT-CL method called Dual Low-Rank Adaptation (DualLoRA), which introduces both an orthogonal LoRA adapter and a residual LoRA adapter parallel to pre-trained weights in each layer. These components are orchestrated by a dynamic memory mechanism to strike a balance between stability and plasticity. The orthogonal LoRA adapter's parameters are updated in an orthogonal subspace of previous tasks to mitigate catastrophic forgetting, while the residual LoRA adapter's parameters are updated in the residual subspace spanned by task-specific bases without interaction across tasks, offering complementary capabilities for fine-tuning new tasks. On ViT-based models, we demonstrate that DualLoRA offers significant advantages in accuracy, inference speed, and memory efficiency over existing CL methods across multiple benchmarks.
AnomalyCD: A benchmark for Earth anomaly change detection with high-resolution and time-series observations
Sep 09, 2024



Various Earth anomalies have destroyed the stable, balanced state, resulting in fatalities and serious destruction of property. With the advantages of large-scale and precise observation, high-resolution remote sensing images have been widely used for anomaly monitoring and localization. Powered by the deep representation, the existing methods have achieved remarkable advances, primarily in classification and change detection techniques. However, labeled samples are difficult to acquire due to the low probability of anomaly occurrence, and the trained models are limited to fixed anomaly categories, which hinders the application for anomalies with few samples or unknown anomalies. In this paper, to tackle this problem, we propose the anomaly change detection (AnomalyCD) technique, which accepts time-series observations and learns to identify anomalous changes by learning from the historical normal change pattern. Compared to the existing techniques, AnomalyCD processes an unfixed number of time steps and can localize the various anomalies in a unified manner, without human supervision. To benchmark AnomalyCD, we constructed a high-resolution dataset with time-series images dedicated to various Earth anomalies (the AnomalyCDD dataset). AnomalyCDD contains high-resolution (from 0.15 to 2.39 m/pixel), time-series (from 3 to 7 time steps), and large-scale images (1927.93 km2 in total) collected globally Furthermore, we developed a zero-shot baseline model (AnomalyCDM), which implements the AnomalyCD technique by extracting a general representation from the segment anything model (SAM) and conducting temporal comparison to distinguish the anomalous changes from normal changes. AnomalyCDM is designed as a two-stage workflow to enhance the efficiency, and has the ability to process the unseen images directly, without retraining for each scene.