 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Unification: Entropy Probing Reveals Divergent Information Patterns in Unified Multimodal Models
Apr 13, 2026Unified multimodal models (UMMs) were designed to combine the reasoning ability of large language models (LLMs) with the generation capability of vision models. In practice, however, this synergy remains elusive: UMMs fail to transfer LLM-like reasoning to image synthesis and exhibit divergent response behaviors. We term this phenomenon pseudo-unification. Diagnosing its internal causes is important, but existing probing methods either lack model-internal insight or ignore prompt-response dependencies. To address these limitations, we propose an information-theoretic probing framework that jointly analyzes how UMMs encode inputs and generate outputs. Applied to ten representative UMMs, our framework reveals that pseudo-unification stems from a dual divergence: (i) Modality-Asymmetric Encoding, where vision and language follow different entropy trajectories, and (ii) Pattern-Split Response, where text generation exhibits high-entropy creativity while image synthesis enforces low-entropy fidelity. Only models that unify both sides (e.g., via contextual prediction) achieve more genuine unification, enabling stronger reasoning-based text-to-image generation even with fewer parameters. Our work provides the first model-internal probing of unification, demonstrating that real multimodal synergy requires consistency in information flow, not just shared parameters.
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
Mar 17, 2026Distilled autoregressive (AR) video models enable efficient streaming generation but frequently misalign with human visual preferences. Existing reinforcement learning (RL) frameworks are not naturally suited to these architectures, typically requiring either expensive re-distillation or solver-coupled reverse-process optimization that introduces considerable memory and computational overhead. We present Astrolabe, an efficient online RL framework tailored for distilled AR models. To overcome existing bottlenecks, we introduce a forward-process RL formulation based on negative-aware fine-tuning. By contrasting positive and negative samples directly at inference endpoints, this approach establishes an implicit policy improvement direction without requiring reverse-process unrolling. To scale this alignment to long videos, we propose a streaming training scheme that generates sequences progressively via a rolling KV-cache, applying RL updates exclusively to local clip windows while conditioning on prior context to ensure long-range coherence. Finally, to mitigate reward hacking, we integrate a multi-reward objective stabilized by uncertainty-aware selective regularization and dynamic reference updates. Extensive experiments demonstrate that our method consistently enhances generation quality across multiple distilled AR video models, serving as a robust and scalable alignment solution.
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
Mar 12, 2026Text-driven video generation has democratized film creation, but camera control in cinematic multi-shot scenarios remains a significant block. Implicit textual prompts lack precision, while explicit trajectory conditioning imposes prohibitive manual overhead and often triggers execution failures in current models. To overcome this bottleneck, we propose a data-centric paradigm shift, positing that aligned (Caption, Trajectory, Video) triplets form an inherent joint distribution that can connect automated plotting and precise execution. Guided by this insight, we present ShotVerse, a "Plan-then-Control" framework that decouples generation into two collaborative agents: a VLM (Vision-Language Model)-based Planner that leverages spatial priors to obtain cinematic, globally aligned trajectories from text, and a Controller that renders these trajectories into multi-shot video content via a camera adapter. Central to our approach is the construction of a data foundation: we design an automated multi-shot camera calibration pipeline aligns disjoint single-shot trajectories into a unified global coordinate system. This facilitates the curation of ShotVerse-Bench, a high-fidelity cinematic dataset with a three-track evaluation protocol that serves as the bedrock for our framework. Extensive experiments demonstrate that ShotVerse effectively bridges the gap between unreliable textual control and labor-intensive manual plotting, achieving superior cinematic aesthetics and generating multi-shot videos that are both camera-accurate and cross-shot consistent.
SesaHand: Enhancing 3D Hand Reconstruction via Controllable Generation with Semantic and Structural Alignment
Feb 28, 2026Recent studies on 3D hand reconstruction have demonstrated the effectiveness of synthetic training data to improve estimation performance. However, most methods rely on game engines to synthesize hand images, which often lack diversity in textures and environments, and fail to include crucial components like arms or interacting objects. Generative models are promising alternatives to generate diverse hand images, but still suffer from misalignment issues. In this paper, we present SesaHand, which enhances controllable hand image generation from both semantic and structural alignment perspectives for 3D hand reconstruction. Specifically, for semantic alignment, we propose a pipeline with Chain-of-Thought inference to extract human behavior semantics from image captions generated by the Vision-Language Model. This semantics suppresses human-irrelevant environmental details and ensures sufficient human-centric contexts for hand image generation. For structural alignment, we introduce hierarchical structural fusion to integrate structural information with different granularity for feature refinement to better align the hand and the overall human body in generated images. We further propose a hand structure attention enhancement method to efficiently enhance the model's attention on hand regions. Experiments demonstrate that our method not only outperforms prior work in generation performance but also improves 3D hand reconstruction with the generated hand images.
Composing Concepts from Images and Videos via Concept-prompt Binding
Dec 10, 2025Visual concept composition, which aims to integrate different elements from images and videos into a single, coherent visual output, still falls short in accurately extracting complex concepts from visual inputs and flexibly combining concepts from both images and videos. We introduce Bind & Compose, a one-shot method that enables flexible visual concept composition by binding visual concepts with corresponding prompt tokens and composing the target prompt with bound tokens from various sources. It adopts a hierarchical binder structure for cross-attention conditioning in Diffusion Transformers to encode visual concepts into corresponding prompt tokens for accurate decomposition of complex visual concepts. To improve concept-token binding accuracy, we design a Diversify-and-Absorb Mechanism that uses an extra absorbent token to eliminate the impact of concept-irrelevant details when training with diversified prompts. To enhance the compatibility between image and video concepts, we present a Temporal Disentanglement Strategy that decouples the training process of video concepts into two stages with a dual-branch binder structure for temporal modeling. Evaluations demonstrate that our method achieves superior concept consistency, prompt fidelity, and motion quality over existing approaches, opening up new possibilities for visual creativity.
Taming Flow-based I2V Models for Creative Video Editing
Sep 26, 2025Although image editing techniques have advanced significantly, video editing, which aims to manipulate videos according to user intent, remains an emerging challenge. Most existing image-conditioned video editing methods either require inversion with model-specific design or need extensive optimization, limiting their capability of leveraging up-to-date image-to-video (I2V) models to transfer the editing capability of image editing models to the video domain. To this end, we propose IF-V2V, an Inversion-Free method that can adapt off-the-shelf flow-matching-based I2V models for video editing without significant computational overhead. To circumvent inversion, we devise Vector Field Rectification with Sample Deviation to incorporate information from the source video into the denoising process by introducing a deviation term into the denoising vector field. To further ensure consistency with the source video in a model-agnostic way, we introduce Structure-and-Motion-Preserving Initialization to generate motion-aware temporally correlated noise with structural information embedded. We also present a Deviation Caching mechanism to minimize the additional computational cost for denoising vector rectification without significantly impacting editing quality. Evaluations demonstrate that our method achieves superior editing quality and consistency over existing approaches, offering a lightweight plug-and-play solution to realize visual creativity.
ProFashion: Prototype-guided Fashion Video Generation with Multiple Reference Images
May 10, 2025



Fashion video generation aims to synthesize temporally consistent videos from reference images of a designated character. Despite significant progress, existing diffusion-based methods only support a single reference image as input, severely limiting their capability to generate view-consistent fashion videos, especially when there are different patterns on the clothes from different perspectives. Moreover, the widely adopted motion module does not sufficiently model human body movement, leading to sub-optimal spatiotemporal consistency. To address these issues, we propose ProFashion, a fashion video generation framework leveraging multiple reference images to achieve improved view consistency and temporal coherency. To effectively leverage features from multiple reference images while maintaining a reasonable computational cost, we devise a Pose-aware Prototype Aggregator, which selects and aggregates global and fine-grained reference features according to pose information to form frame-wise prototypes, which serve as guidance in the denoising process. To further enhance motion consistency, we introduce a Flow-enhanced Prototype Instantiator, which exploits the human keypoint motion flow to guide an extra spatiotemporal attention process in the denoiser. To demonstrate the effectiveness of ProFashion, we extensively evaluate our method on the MRFashion-7K dataset we collected from the Internet. ProFashion also outperforms previous methods on the UBC Fashion dataset.
Generative AI for Film Creation: A Survey of Recent Advances
Apr 11, 2025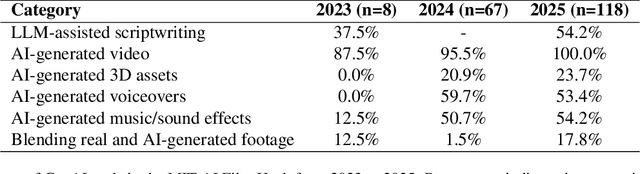


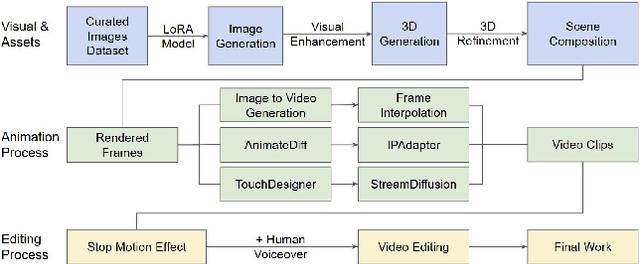
Generative AI (GenAI) is transforming filmmaking, equipping artists with tools like text-to-image and image-to-video diffusion, neural radiance fields, avatar generation, and 3D synthesis. This paper examines the adoption of these technologies in filmmaking, analyzing workflows from recent AI-driven films to understand how GenAI contributes to character creation, aesthetic styling, and narration. We explore key strategies for maintaining character consistency, achieving stylistic coherence, and ensuring motion continuity. Additionally, we highlight emerging trends such as the growing use of 3D generation and the integration of real footage with AI-generated elements. Beyond technical advancements, we examine how GenAI is enabling new artistic expressions, from generating hard-to-shoot footage to dreamlike diffusion-based morphing effects, abstract visuals, and unworldly objects. We also gather artists' feedback on challenges and desired improvements, including consistency, controllability, fine-grained editing, and motion refinement. Our study provides insights into the evolving intersection of AI and filmmaking, offering a roadmap for researchers and artists navigating this rapidly expanding field.
Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Jul 22, 2024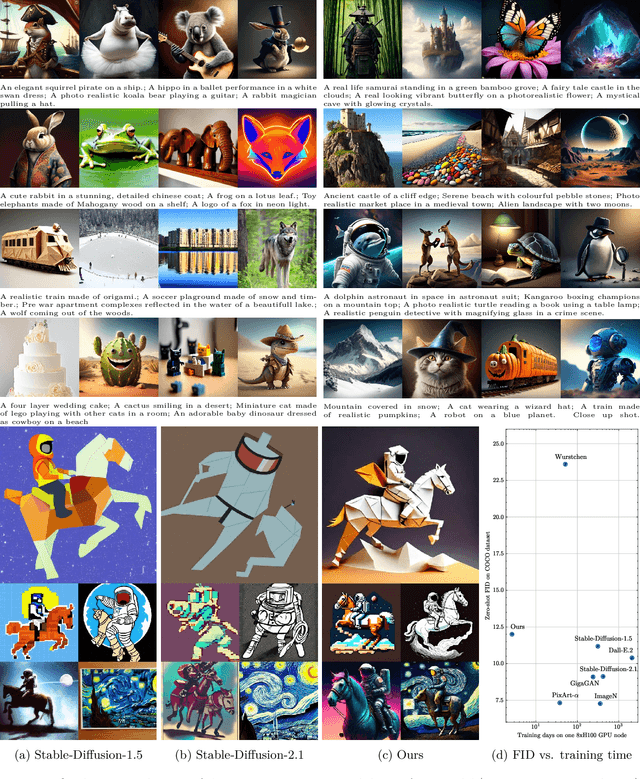
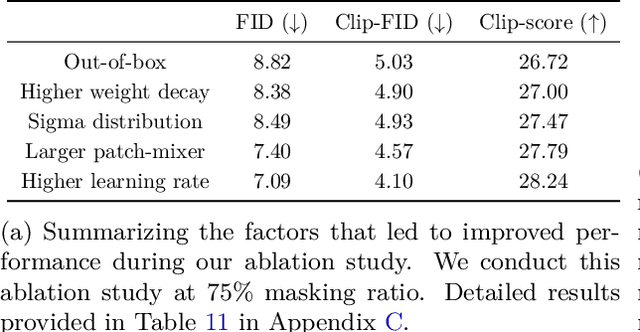
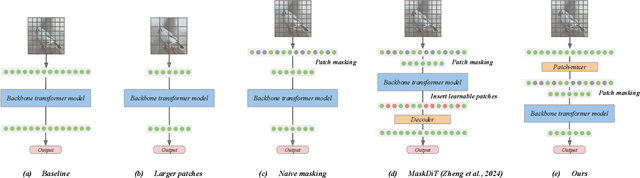

As scaling laws in generative AI push performance, they also simultaneously concentrate the development of these models among actors with large computational resources. With a focus on text-to-image (T2I) generative models, we aim to address this bottleneck by demonstrating very low-cost training of large-scale T2I diffusion transformer models. As the computational cost of transformers increases with the number of patches in each image, we propose to randomly mask up to 75% of the image patches during training. We propose a deferred masking strategy that preprocesses all patches using a patch-mixer before masking, thus significantly reducing the performance degradation with masking, making it superior to model downscaling in reducing computational cost. We also incorporate the latest improvements in transformer architecture, such as the use of mixture-of-experts layers, to improve performance and further identify the critical benefit of using synthetic images in micro-budget training. Finally, using only 37M publicly available real and synthetic images, we train a 1.16 billion parameter sparse transformer with only \$1,890 economical cost and achieve a 12.7 FID in zero-shot generation on the COCO dataset. Notably, our model achieves competitive FID and high-quality generations while incurring 118$\times$ lower cost than stable diffusion models and 14$\times$ lower cost than the current state-of-the-art approach that costs \$28,400. We aim to release our end-to-end training pipeline to further democratize the training of large-scale diffusion models on micro-budgets.
Your Diffusion Model is Secretly a Noise Classifier and Benefits from Contrastive Training
Jul 12, 2024



Diffusion models learn to denoise data and the trained denoiser is then used to generate new samples from the data distribution. In this paper, we revisit the diffusion sampling process and identify a fundamental cause of sample quality degradation: the denoiser is poorly estimated in regions that are far Outside Of the training Distribution (OOD), and the sampling process inevitably evaluates in these OOD regions. This can become problematic for all sampling methods, especially when we move to parallel sampling which requires us to initialize and update the entire sample trajectory of dynamics in parallel, leading to many OOD evaluations. To address this problem, we introduce a new self-supervised training objective that differentiates the levels of noise added to a sample, leading to improved OOD denoising performance. The approach is based on our observation that diffusion models implicitly define a log-likelihood ratio that distinguishes distributions with different amounts of noise, and this expression depends on denoiser performance outside the standard training distribution. We show by diverse experiments that the proposed contrastive diffusion training is effective for both sequential and parallel settings, and it improves the performance and speed of parallel samplers significantly.