 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOL-Pretrain: A complexity annotated corpus of first-order logic
May 20, 2025



Transformer-based large language models (LLMs) have demonstrated remarkable reasoning capabilities such as coding and solving mathematical problems to commonsense inference. While these tasks vary in complexity, they all require models to integrate and compute over structured information. Despite recent efforts to reverse-engineer LLM behavior through controlled experiments, our understanding of how these models internalize and execute complex algorithms remains limited. Progress has largely been confined to small-scale studies or shallow tasks such as basic arithmetic and grammatical pattern matching. One barrier to deeper understanding is the nature of pretraining data -- vast, heterogeneous, and often poorly annotated, making it difficult to isolate mechanisms of reasoning. To bridge this gap, we introduce a large-scale, fully open, complexity-annotated dataset of first-order logic reasoning traces, designed to probe and analyze algorithmic reasoning in LLMs. The dataset consists of 3.5 billion tokens, including 8.8 million LLM-augmented, human-annotated examples and 7.5 million synthetically generated examples. Each synthetic example is verifiably correct, produced by a custom automated theorem solver, and accompanied by metadata tracing its algorithmic provenance. We aim to provide a scalable, interpretable artifact for studying how LLMs learn and generalize symbolic reasoning processes, paving the way for more transparent and targeted investigations into the algorithmic capabilities of modern models.
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
May 20, 2025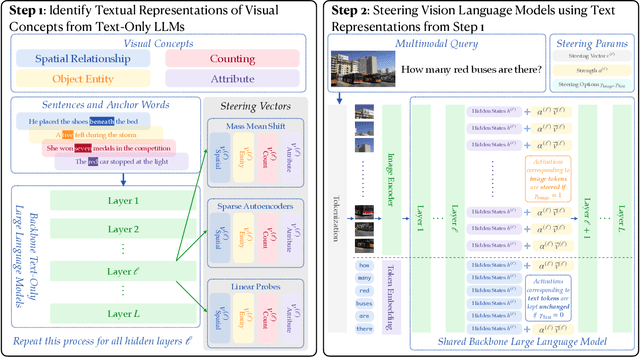
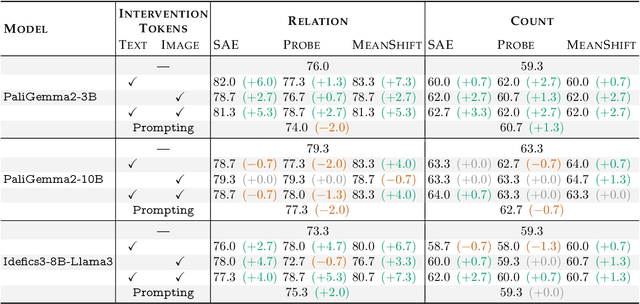
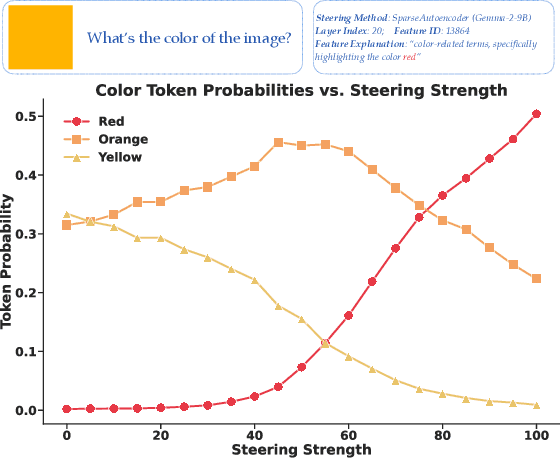
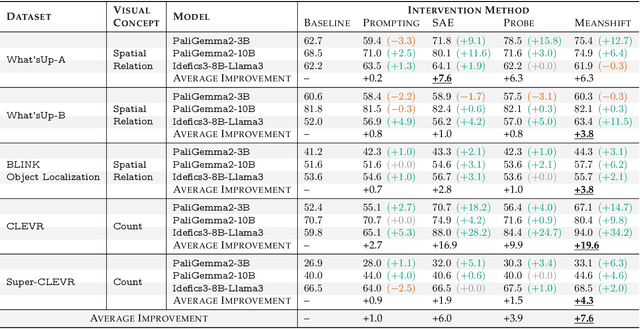
Steering methods have emerged as effective and targeted tools for guiding large language models' (LLMs) behavior without modifying their parameters. Multimodal large language models (MLLMs), however, do not currently enjoy the same suite of techniques, due in part to their recency and architectural diversity. Inspired by this gap, we investigate whether MLLMs can be steered using vectors derived from their text-only LLM backbone, via sparse autoencoders (SAEs), mean shift, and linear probing. We find that text-derived steering consistently enhances multimodal accuracy across diverse MLLM architectures and visual tasks. In particular, mean shift boosts spatial relationship accuracy on CV-Bench by up to +7.3% and counting accuracy by up to +3.3%, outperforming prompting and exhibiting strong generalization to out-of-distribution datasets. These results highlight textual steering vectors as a powerful, efficient mechanism for enhancing grounding in MLLMs with minimal additional data collection and computational overhead.
The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities
Nov 07, 2024
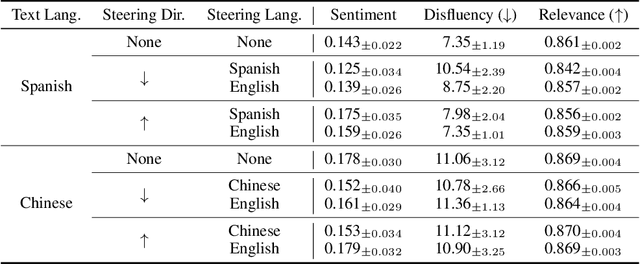
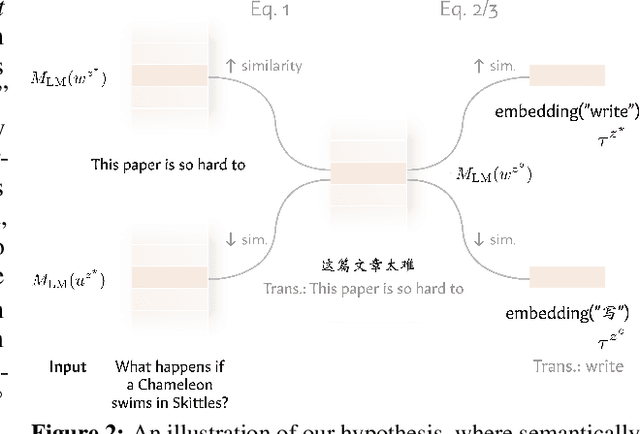
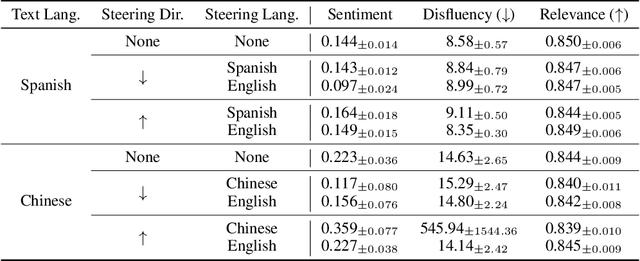
Modern language models can process inputs across diverse languages and modalities. We hypothesize that models acquire this capability through learning a shared representation space across heterogeneous data types (e.g., different languages and modalities), which places semantically similar inputs near one another, even if they are from different modalities/languages. We term this the semantic hub hypothesis, following the hub-and-spoke model from neuroscience (Patterson et al., 2007) which posits that semantic knowledge in the human brain is organized through a transmodal semantic "hub" which integrates information from various modality-specific "spokes" regions. We first show that model representations for semantically equivalent inputs in different languages are similar in the intermediate layers, and that this space can be interpreted using the model's dominant pretraining language via the logit lens. This tendency extends to other data types, including arithmetic expressions, code, and visual/audio inputs. Interventions in the shared representation space in one data type also predictably affect model outputs in other data types, suggesting that this shared representations space is not simply a vestigial byproduct of large-scale training on broad data, but something that is actively utilized by the model during input processing.
Causal Interventions on Causal Paths: Mapping GPT-2's Reasoning From Syntax to Semantics
Oct 28, 2024



While interpretability research has shed light on some internal algorithms utilized by transformer-based LLMs, reasoning in natural language, with its deep contextuality and ambiguity, defies easy categorization. As a result, formulating clear and motivating questions for circuit analysis that rely on well-defined in-domain and out-of-domain examples required for causal interventions is challenging. Although significant work has investigated circuits for specific tasks, such as indirect object identification (IOI), deciphering natural language reasoning through circuits remains difficult due to its inherent complexity. In this work, we take initial steps to characterize causal reasoning in LLMs by analyzing clear-cut cause-and-effect sentences like "I opened an umbrella because it started raining," where causal interventions may be possible through carefully crafted scenarios using GPT-2 small. Our findings indicate that causal syntax is localized within the first 2-3 layers, while certain heads in later layers exhibit heightened sensitivity to nonsensical variations of causal sentences. This suggests that models may infer reasoning by (1) detecting syntactic cues and (2) isolating distinct heads in the final layers that focus on semantic relationships.
Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
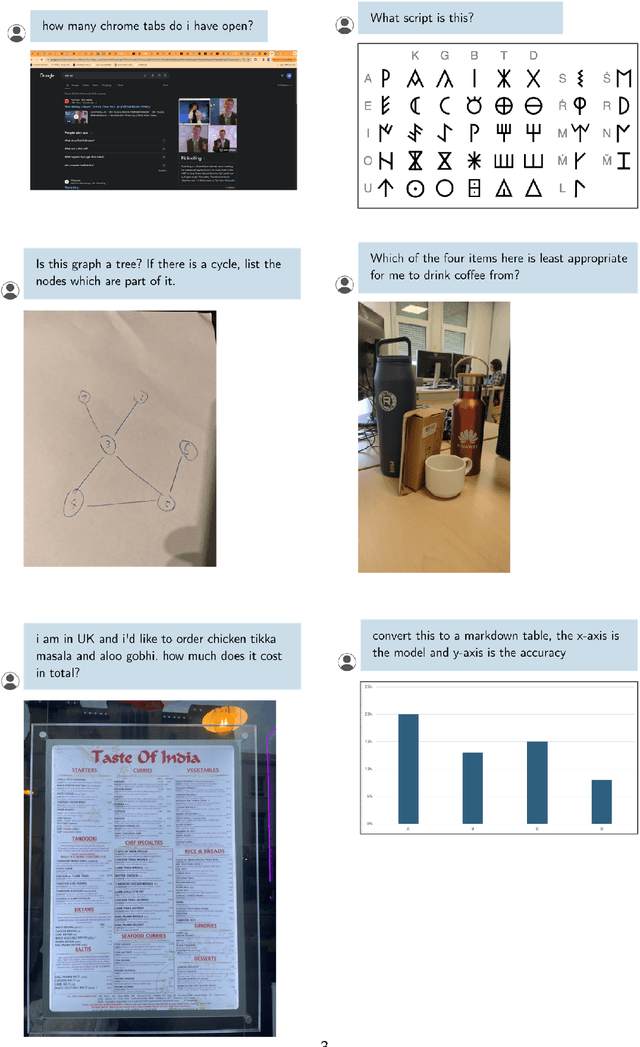
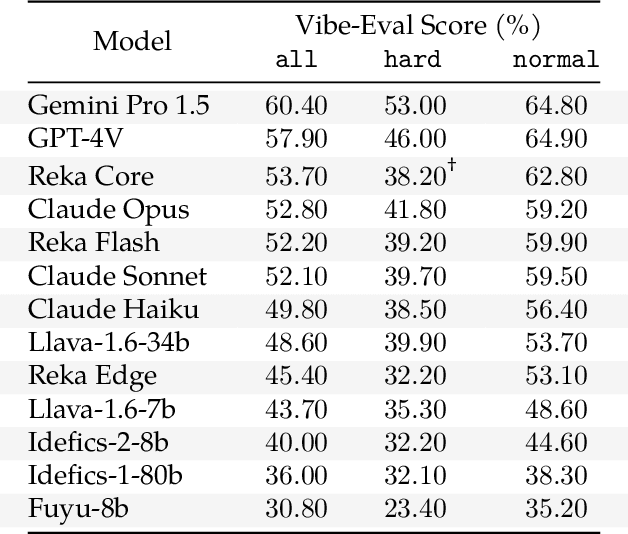
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024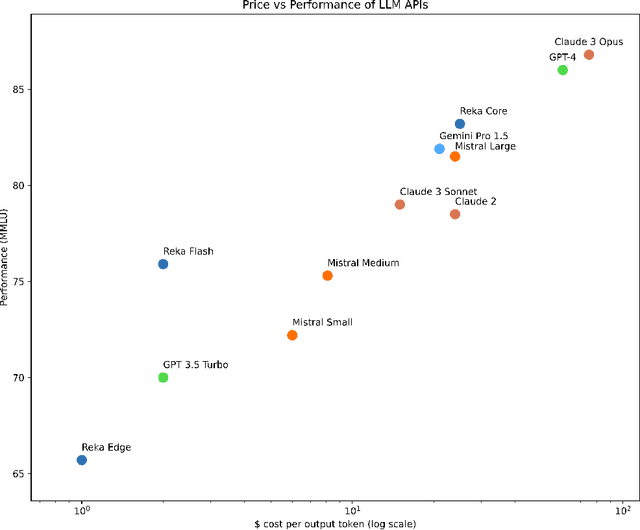


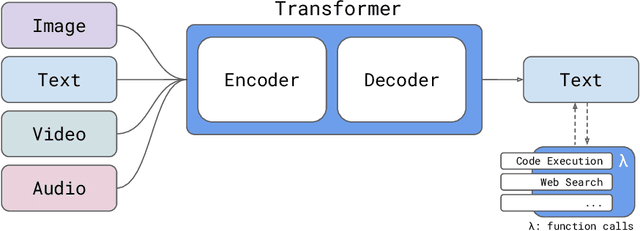
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
IsoBench: Benchmarking Multimodal Foundation Models on Isomorphic Representations
Apr 02, 2024
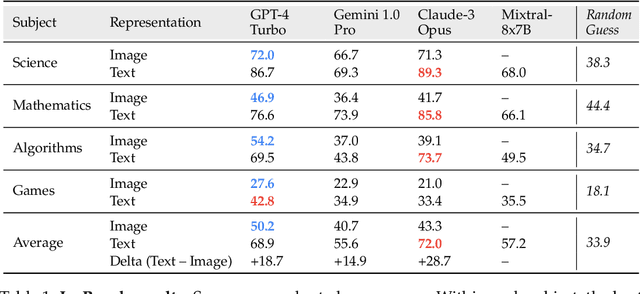
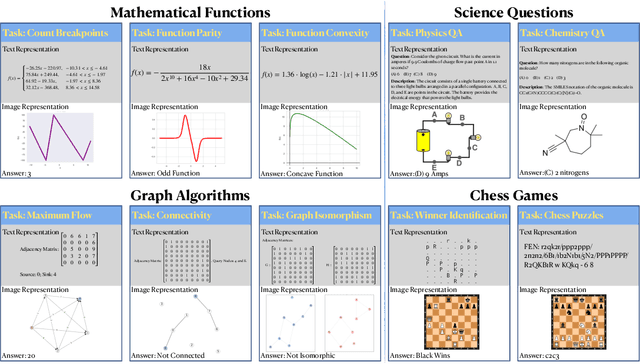
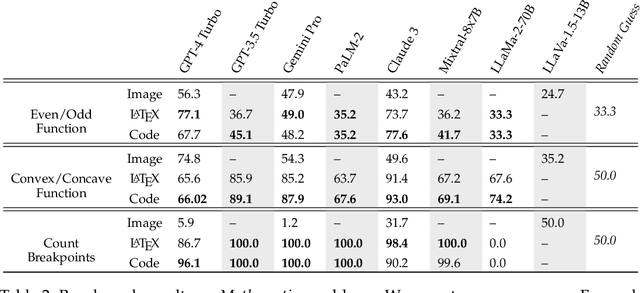
Current foundation models exhibit impressive capabilities when prompted either with text only or with both image and text inputs. But do their capabilities change depending on the input modality? In this work, we propose $\textbf{IsoBench}$, a benchmark dataset containing problems from four major areas: math, science, algorithms, and games. Each example is presented with multiple $\textbf{isomorphic representations}$ of inputs, such as visual, textual, and mathematical presentations. IsoBench provides fine-grained feedback to diagnose performance gaps caused by the form of the representation. Across various foundation models, we observe that on the same problem, models have a consistent preference towards textual representations. Most prominently, when evaluated on all IsoBench problems, Claude-3 Opus performs 28.7 points worse when provided with images instead of text; similarly, GPT-4 Turbo is 18.7 points worse and Gemini Pro is 14.9 points worse. Finally, we present two prompting techniques, $\textit{IsoCombination}$ and $\textit{IsoScratchPad}$, which improve model performance by considering combinations of, and translations between, different input representations.
Understanding In-Context Learning with a Pelican Soup Framework
Feb 16, 2024



Many existing theoretical analyses of in-context learning for natural language processing are based on latent variable models that leaves gaps between theory and practice. We aim to close these gaps by proposing a theoretical framework, the Pelican Soup Framework. In this framework, we introduce (1) the notion of a common sense knowledge base, (2) a general formalism for natural language classification tasks, and the notion of (3) meaning association. Under this framework, we can establish a $\mathcal{O}(1/T)$ loss bound for in-context learning, where $T$ is the number of example-label pairs in the demonstration. Compared with previous works, our bound reflects the effect of the choice of verbalizers and the effect of instruction tuning. An additional notion of \textit{atom concepts} makes our framework possible to explain the generalization to tasks unseen in the language model training data. Finally, we propose a toy setup, Calcutec, and a digit addition task that mimics types of distribution shifts a model needs to overcome to perform in-context learning. We also experiment with GPT2-Large on real-world NLP tasks. Our empirical results demonstrate the efficacy of our framework to explain in-context learning.
DeLLMa: A Framework for Decision Making Under Uncertainty with Large Language Models
Feb 04, 2024Large language models (LLMs) are increasingly used across society, including in domains like business, engineering, and medicine. These fields often grapple with decision-making under uncertainty, a critical yet challenging task. In this paper, we show that directly prompting LLMs on these types of decision-making problems yields poor results, especially as the problem complexity increases. To overcome this limitation, we propose DeLLMa (Decision-making Large Language Model assistant), a framework designed to enhance decision-making accuracy in uncertain environments. DeLLMa involves a multi-step scaffolding procedure, drawing upon principles from decision theory and utility theory, to provide an optimal and human-auditable decision-making process. We validate our framework on decision-making environments involving real agriculture and finance data. Our results show that DeLLMa can significantly improve LLM decision-making performance, achieving up to a 40% increase in accuracy over competing methods.
On Retrieval Augmentation and the Limitations of Language Model Training
Nov 16, 2023Augmenting a language model (LM) with $k$-nearest neighbors (kNN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remains elusive. In this work, we first rule out one previously posited possibility -- the "softmax bottleneck." We further identify the MLP hurdle phenomenon, where the final MLP layer in LMs may impede LM optimization early on. We explore memorization and generalization in language models with two new datasets, where advanced model like GPT-3.5-turbo find generalizing to irrelevant information in the training data challenging. However, incorporating kNN retrieval to vanilla GPT-2 117M can consistently improve performance in this setting.