 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteLLM: Learning to Route LLMs with Preference Data
Jun 26, 2024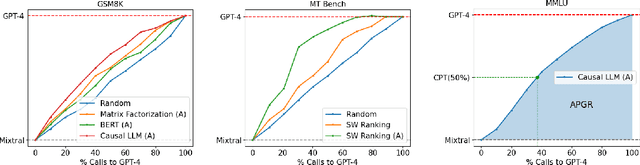
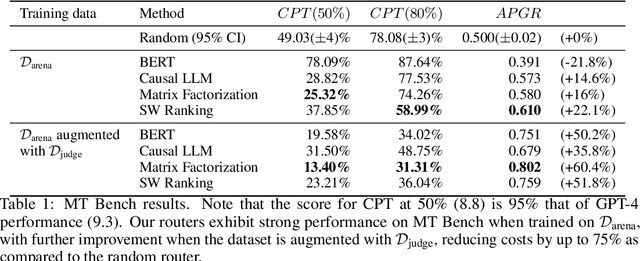
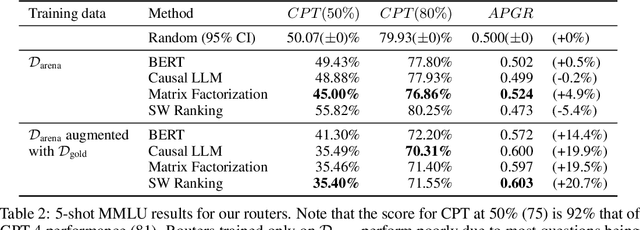
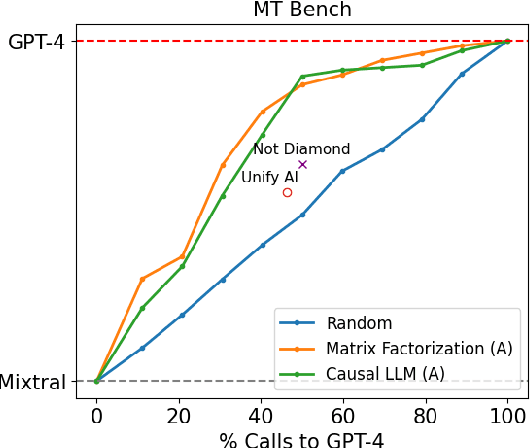
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024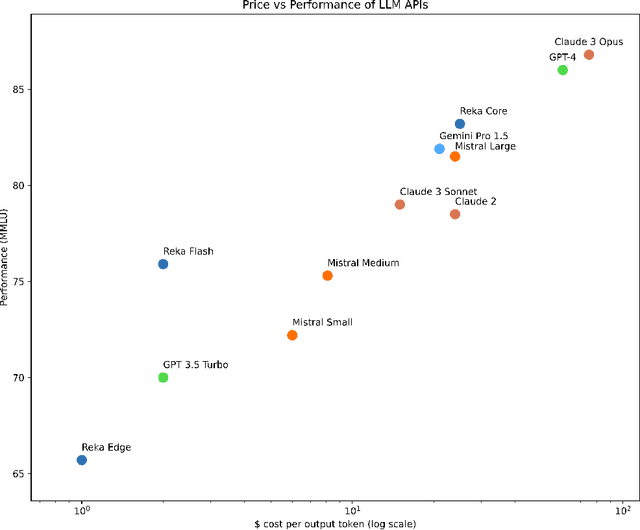


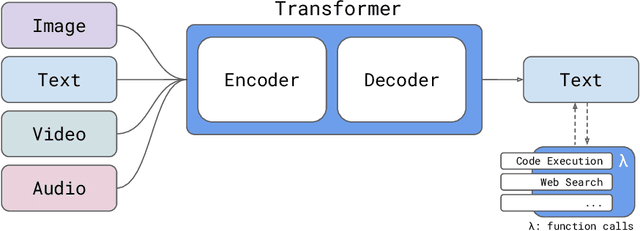
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
Nov 02, 2023While Large Language Models (LLMs) are increasingly being used in real-world applications, they remain vulnerable to prompt injection attacks: malicious third party prompts that subvert the intent of the system designer. To help researchers study this problem, we present a dataset of over 126,000 prompt injection attacks and 46,000 prompt-based "defenses" against prompt injection, all created by players of an online game called Tensor Trust. To the best of our knowledge, this is currently the largest dataset of human-generated adversarial examples for instruction-following LLMs. The attacks in our dataset have a lot of easily interpretable stucture, and shed light on the weaknesses of LLMs. We also use the dataset to create a benchmark for resistance to two types of prompt injection, which we refer to as prompt extraction and prompt hijacking. Our benchmark results show that many models are vulnerable to the attack strategies in the Tensor Trust dataset. Furthermore, we show that some attack strategies from the dataset generalize to deployed LLM-based applications, even though they have a very different set of constraints to the game. We release all data and source code at https://tensortrust.ai/paper