 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
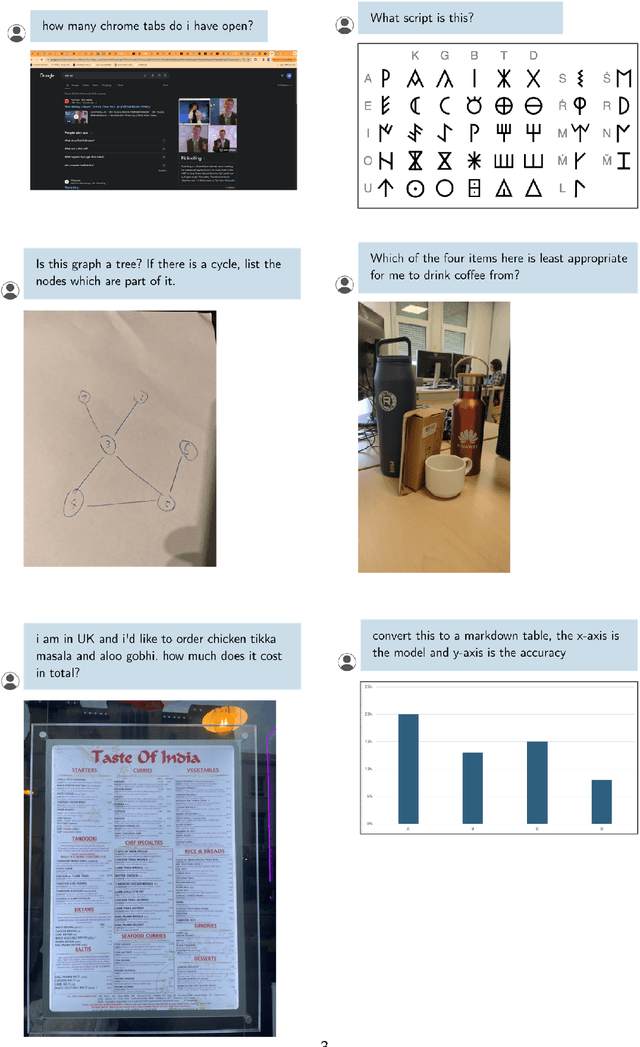
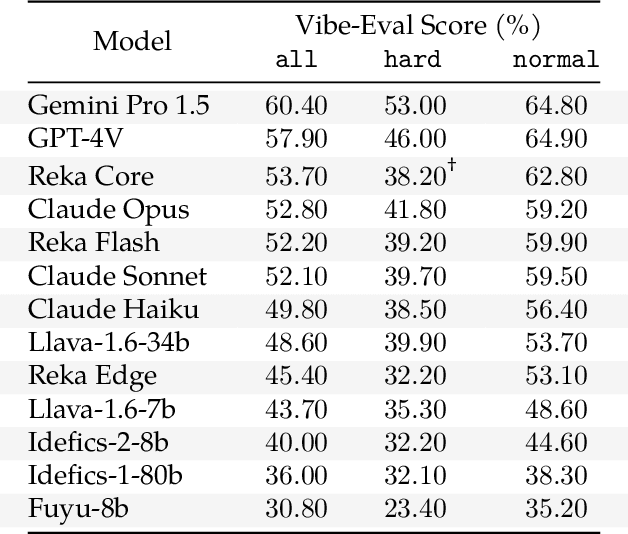
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024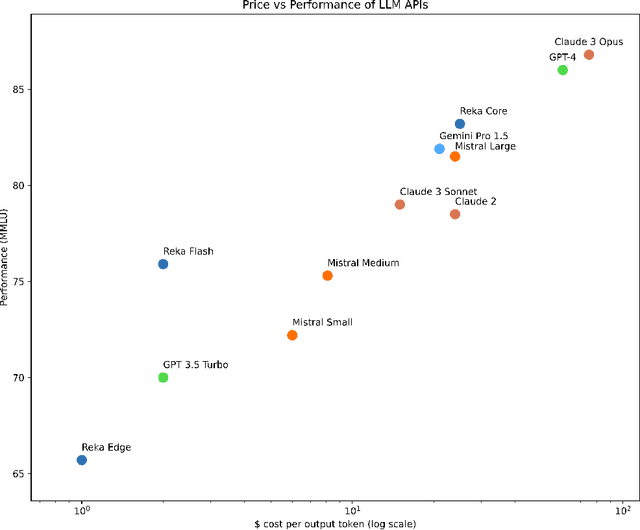


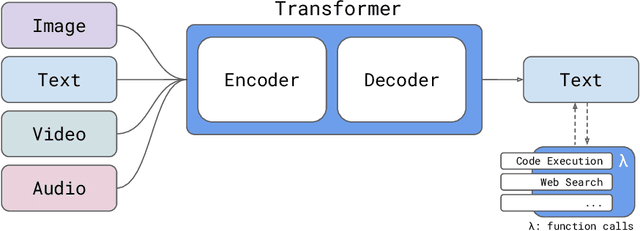
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Task-Based MoE for Multitask Multilingual Machine Translation
Sep 11, 2023Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
The student becomes the master: Matching GPT3 on Scientific Factual Error Correction
May 24, 2023
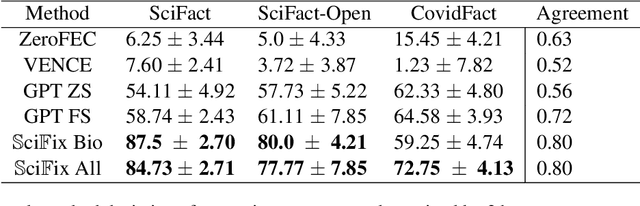

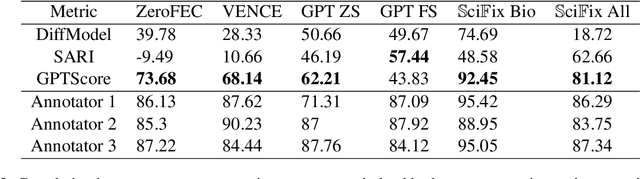
Due to the prohibitively high cost of creating error correction datasets, most Factual Claim Correction methods rely on a powerful verification model to guide the correction process. This leads to a significant drop in performance in domains like Scientific Claim Correction, where good verification models do not always exist. In this work, we introduce a claim correction system that makes no domain assumptions and does not require a verifier but is able to outperform existing methods by an order of magnitude -- achieving 94% correction accuracy on the SciFact dataset, and 62.5% on the SciFact-Open dataset, compared to the next best methods 0.5% and 1.50% respectively. Our method leverages the power of prompting with LLMs during training to create a richly annotated dataset that can be used for fully supervised training and regularization. We additionally use a claim-aware decoding procedure to improve the quality of corrected claims. Our method is competitive with the very LLM that was used to generate the annotated dataset -- with GPT3.5 achieving 89.5% and 60% correction accuracy on SciFact and SciFact-Open, despite using 1250 times as many parameters as our model.
On the Algorithmic Stability and Generalization of Adaptive Optimization Methods
Nov 08, 2022

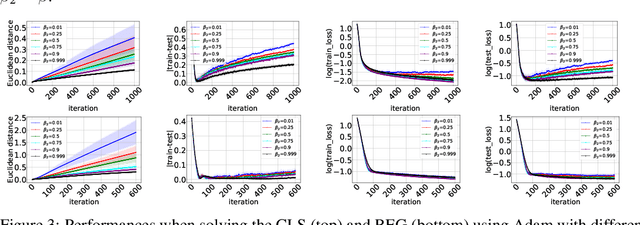
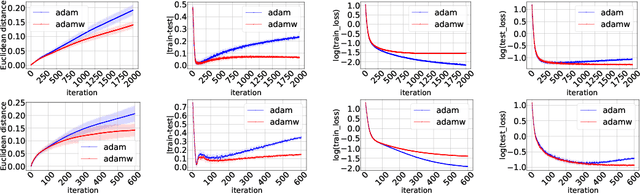
Despite their popularity in deep learning and machine learning in general, the theoretical properties of adaptive optimizers such as Adagrad, RMSProp, Adam or AdamW are not yet fully understood. In this paper, we develop a novel framework to study the stability and generalization of these optimization methods. Based on this framework, we show provable guarantees about such properties that depend heavily on a single parameter $\beta_2$. Our empirical experiments support our claims and provide practical insights into the stability and generalization properties of adaptive optimization methods.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022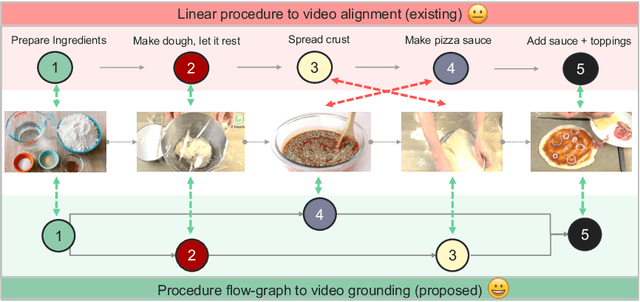
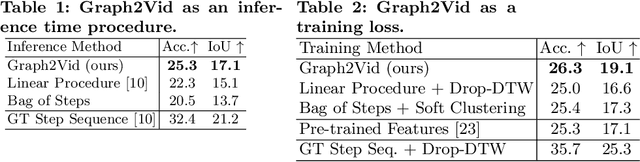

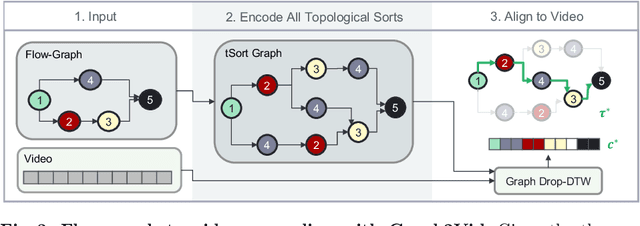
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
Understanding Long Documents with Different Position-Aware Attentions
Aug 17, 2022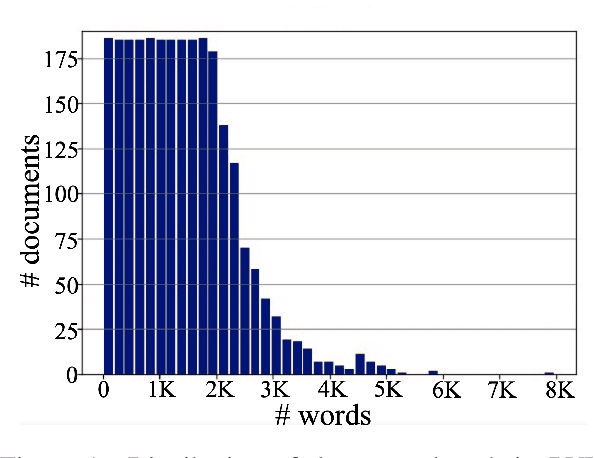
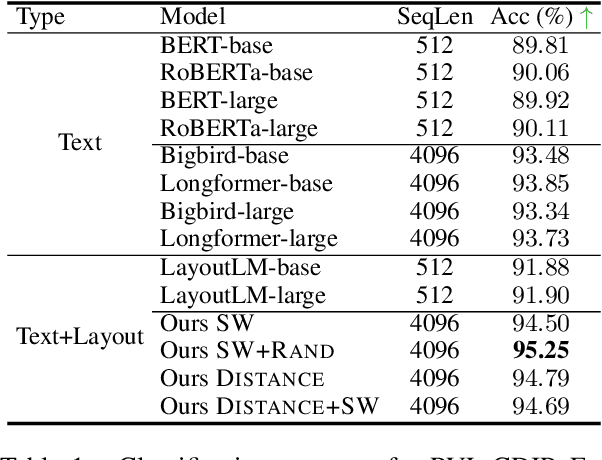
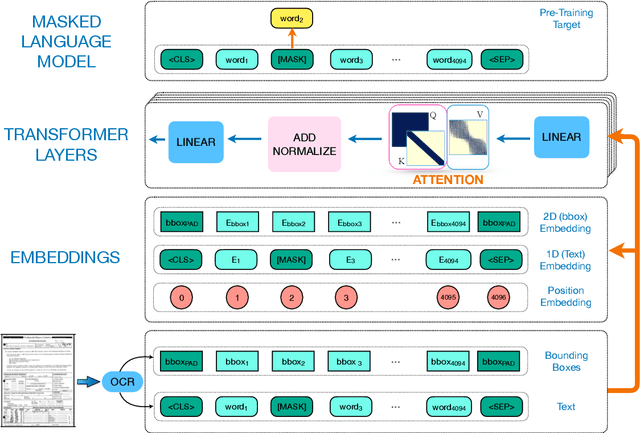
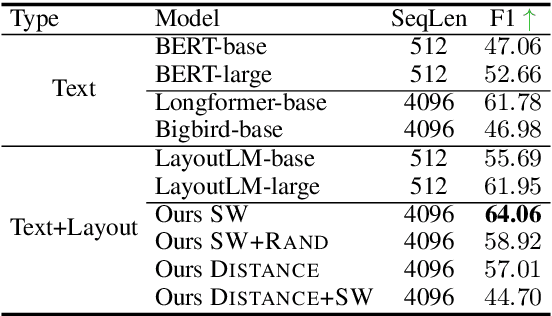
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D position-aware attention with essentially shortened context. Experimental results show that our proposed models have advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer
Apr 12, 2021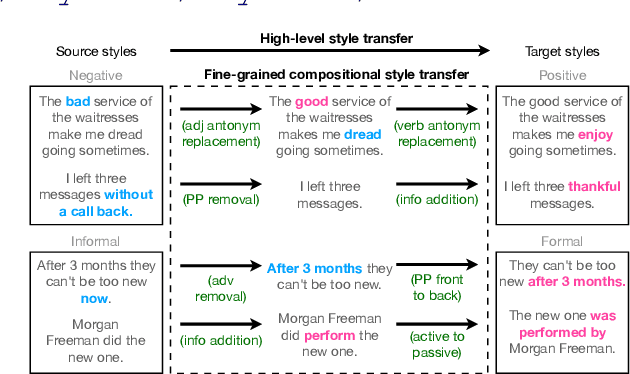
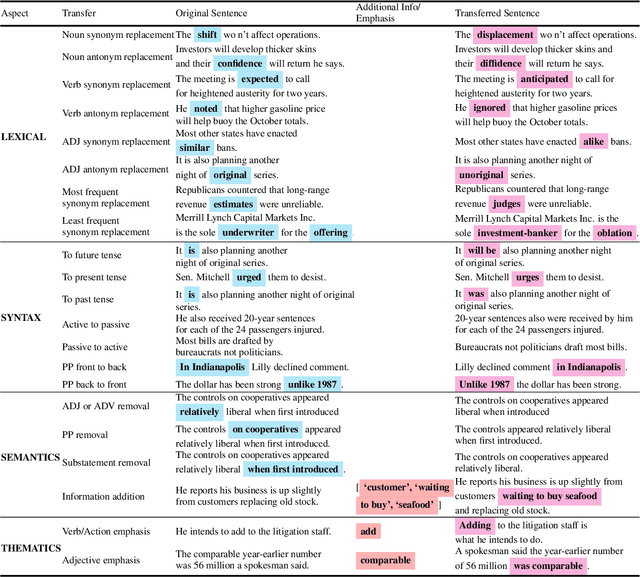
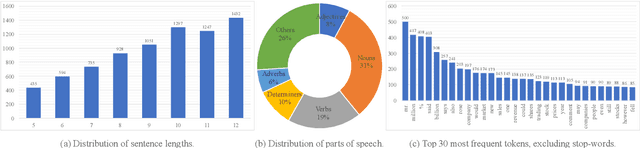
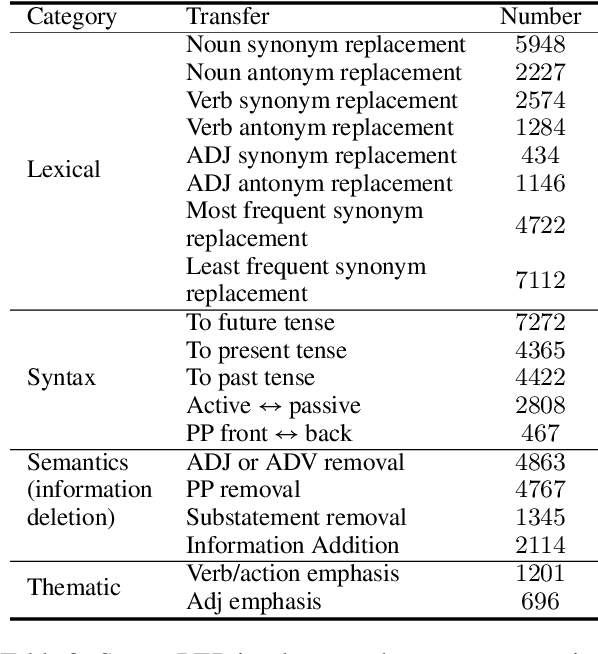
Text style transfer aims to controllably generate text with targeted stylistic changes while maintaining core meaning from the source sentence constant. Many of the existing style transfer benchmarks primarily focus on individual high-level semantic changes (e.g. positive to negative), which enable controllability at a high level but do not offer fine-grained control involving sentence structure, emphasis, and content of the sentence. In this paper, we introduce a large-scale benchmark, StylePTB, with (1) paired sentences undergoing 21 fine-grained stylistic changes spanning atomic lexical, syntactic, semantic, and thematic transfers of text, as well as (2) compositions of multiple transfers which allow modeling of fine-grained stylistic changes as building blocks for more complex, high-level transfers. By benchmarking existing methods on StylePTB, we find that they struggle to model fine-grained changes and have an even more difficult time composing multiple styles. As a result, StylePTB brings novel challenges that we hope will encourage future research in controllable text style transfer, compositional models, and learning disentangled representations. Solving these challenges would present important steps towards controllable text generation.
Revisiting the Sample Complexity of Sparse Spectrum Approximation of Gaussian Processes
Nov 17, 2020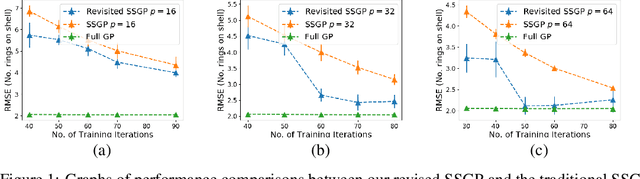

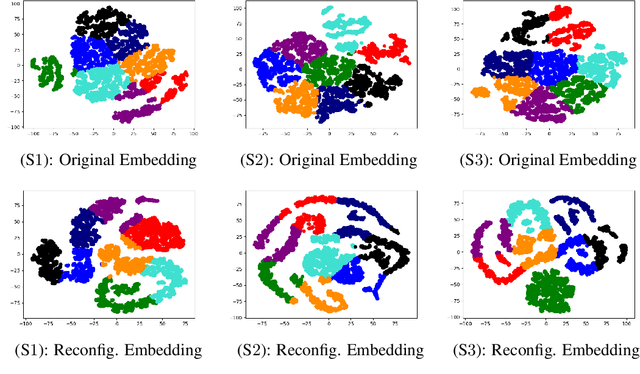
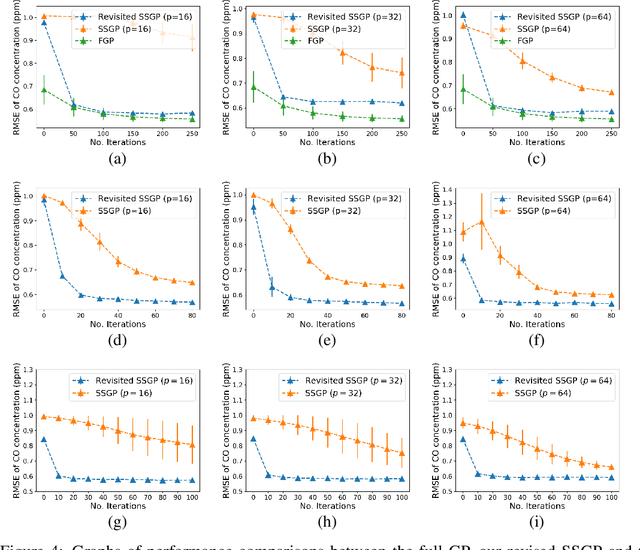
We introduce a new scalable approximation for Gaussian processes with provable guarantees which hold simultaneously over its entire parameter space. Our approximation is obtained from an improved sample complexity analysis for sparse spectrum Gaussian processes (SSGPs). In particular, our analysis shows that under a certain data disentangling condition, an SSGP's prediction and model evidence (for training) can well-approximate those of a full GP with low sample complexity. We also develop a new auto-encoding algorithm that finds a latent space to disentangle latent input coordinates into well-separated clusters, which is amenable to our sample complexity analysis. We validate our proposed method on several benchmarks with promising results supporting our theoretical analysis.
Robust Handwriting Recognition with Limited and Noisy Data
Aug 18, 2020

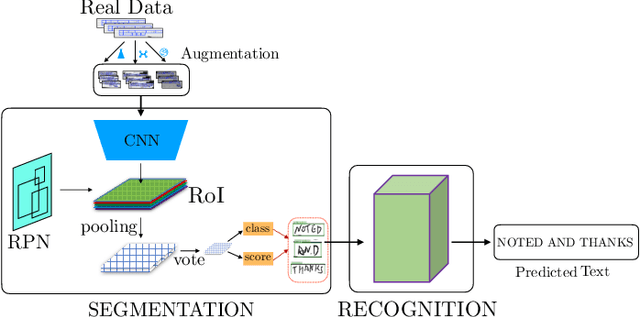
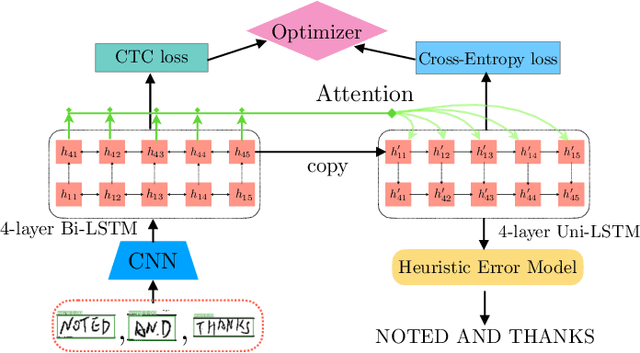
Despite the advent of deep learning in computer vision, the general handwriting recognition problem is far from solved. Most existing approaches focus on handwriting datasets that have clearly written text and carefully segmented labels. In this paper, we instead focus on learning handwritten characters from maintenance logs, a constrained setting where data is very limited and noisy. We break the problem into two consecutive stages of word segmentation and word recognition respectively and utilize data augmentation techniques to train both stages. Extensive comparisons with popular baselines for scene-text detection and word recognition show that our system achieves a lower error rate and is more suited to handle noisy and difficult documents