 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Image Tokenization for Multi-Scale Image Super Resolution
May 14, 2026We introduce a multi-scale Image Super Resolution (ISR) method building on recent advances in Visual Auto-Regressive (VAR) modeling. VAR models break image tokenization into additive, gradually increasing scales, using Residual Quantization (RQ), an approach that aligns perfectly with our target ISR task. Previous works taking advantage of this synergy suffer from two main shortcomings. First, due to the limitations in RQ, they only generate images at a predefined fixed scale, failing to map intermediate outputs to the corresponding image scales. They also rely on large backbones or a large corpus of annotated data to achieve better performance. To address both shortcomings, we introduce two novel components to the VAR training for ISR, aiming at increasing its flexibility and reducing its complexity. In particular, we introduce a) a \textbf{Hierarchical Image Tokenization (HIT)} approach that progressively represents images at different scales while enforcing token overlap across scales, and b) a \textbf{Direct Preference Optimization (DPO) regularization term} that, relying solely on the (LR,HR) pair, encourages the transformer to produce the latter over the former. Our proposed HIT acts as a strong inductive bias for the VAR training, resulting in a small model (300M params vs 1B params of VARSR), that achieves state-of-the-art results without external training data, and that delivers multi-scale outputs with a single forward pass.
Restore, Assess, Repeat: A Unified Framework for Iterative Image Restoration
Mar 27, 2026Image restoration aims to recover high quality images from inputs degraded by various factors, such as adverse weather, blur, or low light. While recent studies have shown remarkable progress across individual or unified restoration tasks, they still suffer from limited generalization and inefficiency when handling unknown or composite degradations. To address these limitations, we propose RAR, a Restore, Assess and Repeat process, that integrates Image Quality Assessment (IQA) and Image Restoration (IR) into a unified framework to iteratively and efficiently achieve high quality image restoration. Specifically, we introduce a restoration process that operates entirely in the latent domain to jointly perform degradation identification, image restoration, and quality verification. The resulting model is fully trainable end to end and allows for an all-in-one assess and restore approach that dynamically adapts the restoration process. Also, the tight integration of IQA and IR into a unified model minimizes the latency and information loss that typically arises from keeping the two modules disjoint, (e.g. during image and/or text decoding). Extensive experiments show that our approach consistent improvements under single, unknown and composite degradations, thereby establishing a new state-of-the-art.
Multi-scale Image Super Resolution with a Single Auto-Regressive Model
Jun 05, 2025In this paper we tackle Image Super Resolution (ISR), using recent advances in Visual Auto-Regressive (VAR) modeling. VAR iteratively estimates the residual in latent space between gradually increasing image scales, a process referred to as next-scale prediction. Thus, the strong priors learned during pre-training align well with the downstream task (ISR). To our knowledge, only VARSR has exploited this synergy so far, showing promising results. However, due to the limitations of existing residual quantizers, VARSR works only at a fixed resolution, i.e. it fails to map intermediate outputs to the corresponding image scales. Additionally, it relies on a 1B transformer architecture (VAR-d24), and leverages a large-scale private dataset to achieve state-of-the-art results. We address these limitations through two novel components: a) a Hierarchical Image Tokenization approach with a multi-scale image tokenizer that progressively represents images at different scales while simultaneously enforcing token overlap across scales, and b) a Direct Preference Optimization (DPO) regularization term that, relying solely on the LR and HR tokenizations, encourages the transformer to produce the latter over the former. To the best of our knowledge, this is the first time a quantizer is trained to force semantically consistent residuals at different scales, and the first time that preference-based optimization is used to train a VAR. Using these two components, our model can denoise the LR image and super-resolve at half and full target upscale factors in a single forward pass. Additionally, we achieve \textit{state-of-the-art results on ISR}, while using a small model (300M params vs ~1B params of VARSR), and without using external training data.
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
Dec 09, 2024



There has been immense progress recently in the visual quality of Stable Diffusion-based Super Resolution (SD-SR). However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. This is compounded for SR as it often operates at high res (e.g. 4Kx3K). In this work, we introduce Edge-SD-SR, the first parameter efficient and low latency diffusion model for image super-resolution. Edge-SD-SR consists of ~169M parameters, including UNet, encoder and decoder, and has a complexity of only ~142 GFLOPs. To maintain a high visual quality on such low compute budget, we introduce a number of training strategies: (i) A novel conditioning mechanism on the low resolution input, coined bidirectional conditioning, which tailors the SD model for the SR task. (ii) Joint training of the UNet and encoder, while decoupling the encodings of the HR and LR images and using a dedicated schedule. (iii) Finetuning the decoder using the UNet's output to directly tailor the decoder to the latents obtained at inference time. Edge-SD-SR runs efficiently on device, e.g. it can upscale a 128x128 patch to 512x512 in 38 msec while running on a Samsung S24 DSP, and of a 512x512 to 2048x2048 (requiring 25 model evaluations) in just ~1.1 sec. Furthermore, we show that Edge-SD-SR matches or even outperforms state-of-the-art SR approaches on the most established SR benchmarks.
FAM Diffusion: Frequency and Attention Modulation for High-Resolution Image Generation with Stable Diffusion
Nov 27, 2024



Diffusion models are proficient at generating high-quality images. They are however effective only when operating at the resolution used during training. Inference at a scaled resolution leads to repetitive patterns and structural distortions. Retraining at higher resolutions quickly becomes prohibitive. Thus, methods enabling pre-existing diffusion models to operate at flexible test-time resolutions are highly desirable. Previous works suffer from frequent artifacts and often introduce large latency overheads. We propose two simple modules that combine to solve these issues. We introduce a Frequency Modulation (FM) module that leverages the Fourier domain to improve the global structure consistency, and an Attention Modulation (AM) module which improves the consistency of local texture patterns, a problem largely ignored in prior works. Our method, coined Fam diffusion, can seamlessly integrate into any latent diffusion model and requires no additional training. Extensive qualitative results highlight the effectiveness of our method in addressing structural and local artifacts, while quantitative results show state-of-the-art performance. Also, our method avoids redundant inference tricks for improved consistency such as patch-based or progressive generation, leading to negligible latency overheads.
You Only Need One Step: Fast Super-Resolution with Stable Diffusion via Scale Distillation
Jan 30, 2024
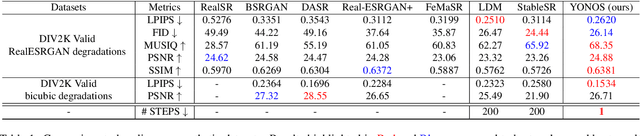
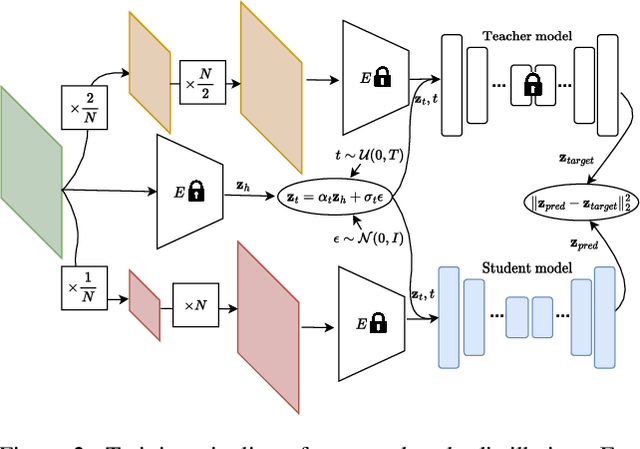

In this paper, we introduce YONOS-SR, a novel stable diffusion-based approach for image super-resolution that yields state-of-the-art results using only a single DDIM step. We propose a novel scale distillation approach to train our SR model. Instead of directly training our SR model on the scale factor of interest, we start by training a teacher model on a smaller magnification scale, thereby making the SR problem simpler for the teacher. We then train a student model for a higher magnification scale, using the predictions of the teacher as a target during the training. This process is repeated iteratively until we reach the target scale factor of the final model. The rationale behind our scale distillation is that the teacher aids the student diffusion model training by i) providing a target adapted to the current noise level rather than using the same target coming from ground truth data for all noise levels and ii) providing an accurate target as the teacher has a simpler task to solve. We empirically show that the distilled model significantly outperforms the model trained for high scales directly, specifically with few steps during inference. Having a strong diffusion model that requires only one step allows us to freeze the U-Net and fine-tune the decoder on top of it. We show that the combination of spatially distilled U-Net and fine-tuned decoder outperforms state-of-the-art methods requiring 200 steps with only one single step.
Graph Guided Question Answer Generation for Procedural Question-Answering
Jan 24, 2024
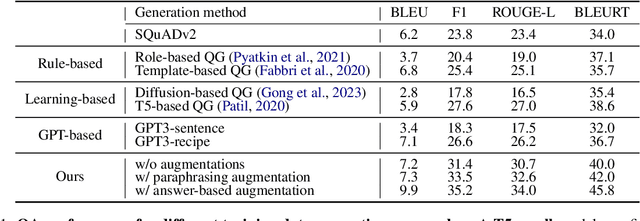
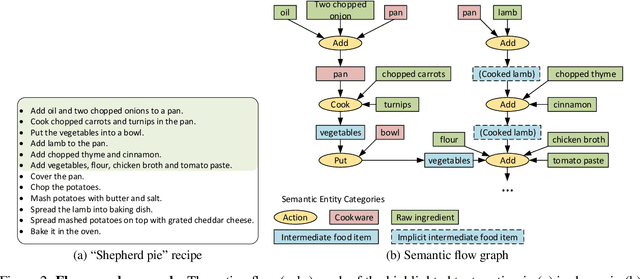
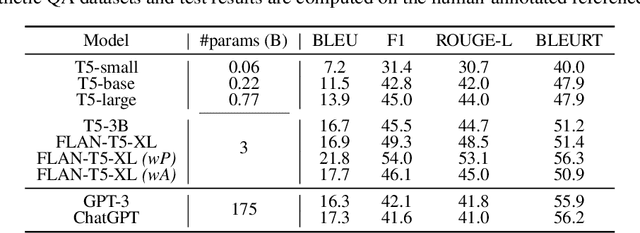
In this paper, we focus on task-specific question answering (QA). To this end, we introduce a method for generating exhaustive and high-quality training data, which allows us to train compact (e.g., run on a mobile device), task-specific QA models that are competitive against GPT variants. The key technological enabler is a novel mechanism for automatic question-answer generation from procedural text which can ingest large amounts of textual instructions and produce exhaustive in-domain QA training data. While current QA data generation methods can produce well-formed and varied data, their non-exhaustive nature is sub-optimal for training a QA model. In contrast, we leverage the highly structured aspect of procedural text and represent each step and the overall flow of the procedure as graphs. We then condition on graph nodes to automatically generate QA pairs in an exhaustive and controllable manner. Comprehensive evaluations of our method show that: 1) small models trained with our data achieve excellent performance on the target QA task, even exceeding that of GPT3 and ChatGPT despite being several orders of magnitude smaller. 2) semantic coverage is the key indicator for downstream QA performance. Crucially, while large language models excel at syntactic diversity, this does not necessarily result in improvements on the end QA model. In contrast, the higher semantic coverage provided by our method is critical for QA performance.
GePSAn: Generative Procedure Step Anticipation in Cooking Videos
Oct 12, 2023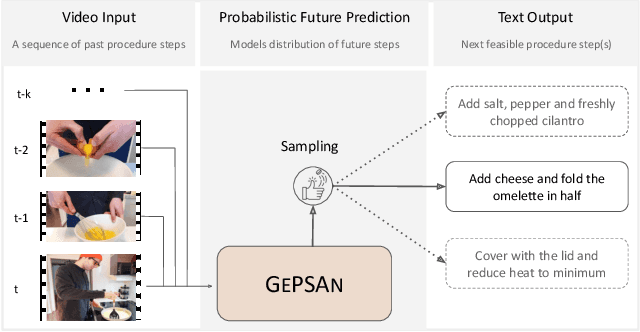
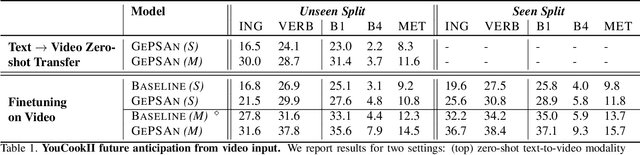
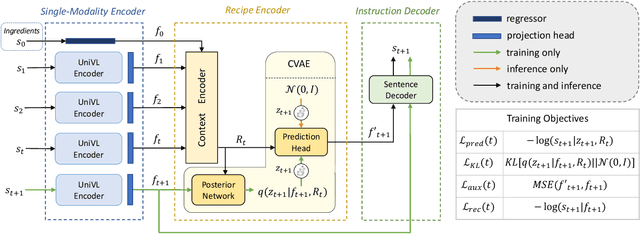
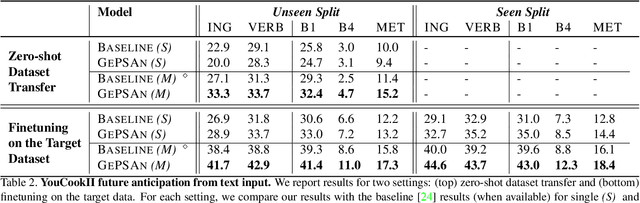
We study the problem of future step anticipation in procedural videos. Given a video of an ongoing procedural activity, we predict a plausible next procedure step described in rich natural language. While most previous work focus on the problem of data scarcity in procedural video datasets, another core challenge of future anticipation is how to account for multiple plausible future realizations in natural settings. This problem has been largely overlooked in previous work. To address this challenge, we frame future step prediction as modelling the distribution of all possible candidates for the next step. Specifically, we design a generative model that takes a series of video clips as input, and generates multiple plausible and diverse candidates (in natural language) for the next step. Following previous work, we side-step the video annotation scarcity by pretraining our model on a large text-based corpus of procedural activities, and then transfer the model to the video domain. Our experiments, both in textual and video domains, show that our model captures diversity in the next step prediction and generates multiple plausible future predictions. Moreover, our model establishes new state-of-the-art results on YouCookII, where it outperforms existing baselines on the next step anticipation. Finally, we also show that our model can successfully transfer from text to the video domain zero-shot, ie, without fine-tuning or adaptation, and produces good-quality future step predictions from video.
StepFormer: Self-supervised Step Discovery and Localization in Instructional Videos
Apr 26, 2023



Instructional videos are an important resource to learn procedural tasks from human demonstrations. However, the instruction steps in such videos are typically short and sparse, with most of the video being irrelevant to the procedure. This motivates the need to temporally localize the instruction steps in such videos, i.e. the task called key-step localization. Traditional methods for key-step localization require video-level human annotations and thus do not scale to large datasets. In this work, we tackle the problem with no human supervision and introduce StepFormer, a self-supervised model that discovers and localizes instruction steps in a video. StepFormer is a transformer decoder that attends to the video with learnable queries, and produces a sequence of slots capturing the key-steps in the video. We train our system on a large dataset of instructional videos, using their automatically-generated subtitles as the only source of supervision. In particular, we supervise our system with a sequence of text narrations using an order-aware loss function that filters out irrelevant phrases. We show that our model outperforms all previous unsupervised and weakly-supervised approaches on step detection and localization by a large margin on three challenging benchmarks. Moreover, our model demonstrates an emergent property to solve zero-shot multi-step localization and outperforms all relevant baselines at this task.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022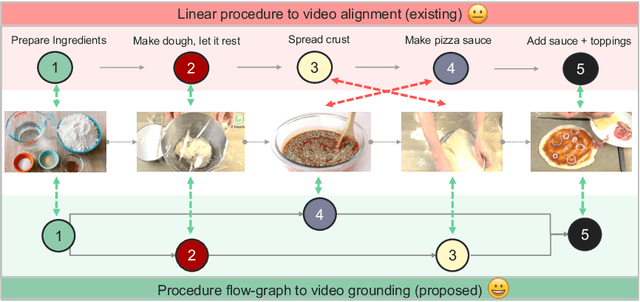
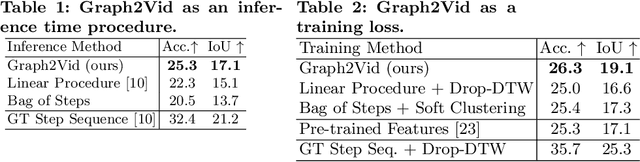

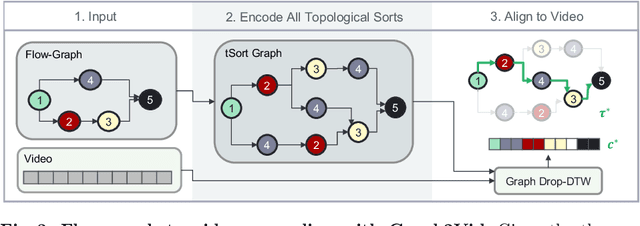
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral