 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Hard Negatives Required: Concept Centric Learning Leads to Compositionality without Degrading Zero-shot Capabilities of Contrastive Models
Mar 26, 2026Contrastive vision-language (V&L) models remain a popular choice for various applications. However, several limitations have emerged, most notably the limited ability of V&L models to learn compositional representations. Prior methods often addressed this limitation by generating custom training data to obtain hard negative samples. Hard negatives have been shown to improve performance on compositionality tasks, but are often specific to a single benchmark, do not generalize, and can cause substantial degradation of basic V&L capabilities such as zero-shot or retrieval performance, rendering them impractical. In this work we follow a different approach. We identify two root causes that limit compositionality performance of V&Ls: 1) Long training captions do not require a compositional representation; and 2) The final global pooling in the text and image encoders lead to a complete loss of the necessary information to learn binding in the first place. As a remedy, we propose two simple solutions: 1) We obtain short concept centric caption parts using standard NLP software and align those with the image; and 2) We introduce a parameter-free cross-modal attention-pooling to obtain concept centric visual embeddings from the image encoder. With these two changes and simple auxiliary contrastive losses, we obtain SOTA performance on standard compositionality benchmarks, while maintaining or improving strong zero-shot and retrieval capabilities. This is achieved without increasing inference cost. We release the code for this work at https://github.com/SamsungLabs/concept_centric_clip.
FAM Diffusion: Frequency and Attention Modulation for High-Resolution Image Generation with Stable Diffusion
Nov 27, 2024



Diffusion models are proficient at generating high-quality images. They are however effective only when operating at the resolution used during training. Inference at a scaled resolution leads to repetitive patterns and structural distortions. Retraining at higher resolutions quickly becomes prohibitive. Thus, methods enabling pre-existing diffusion models to operate at flexible test-time resolutions are highly desirable. Previous works suffer from frequent artifacts and often introduce large latency overheads. We propose two simple modules that combine to solve these issues. We introduce a Frequency Modulation (FM) module that leverages the Fourier domain to improve the global structure consistency, and an Attention Modulation (AM) module which improves the consistency of local texture patterns, a problem largely ignored in prior works. Our method, coined Fam diffusion, can seamlessly integrate into any latent diffusion model and requires no additional training. Extensive qualitative results highlight the effectiveness of our method in addressing structural and local artifacts, while quantitative results show state-of-the-art performance. Also, our method avoids redundant inference tricks for improved consistency such as patch-based or progressive generation, leading to negligible latency overheads.
Graph Guided Question Answer Generation for Procedural Question-Answering
Jan 24, 2024
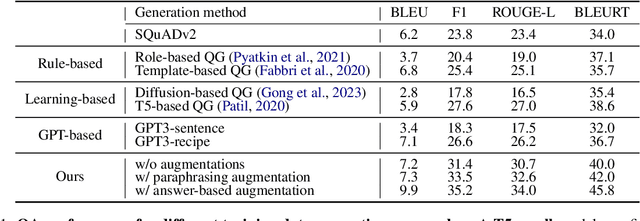
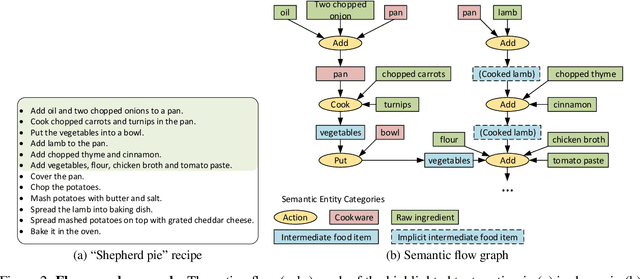
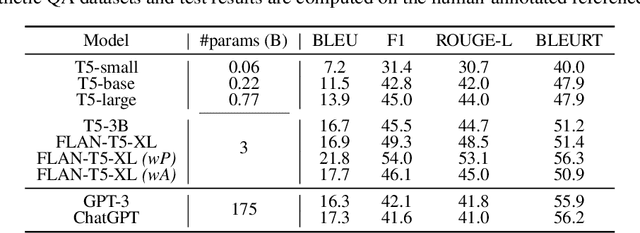
In this paper, we focus on task-specific question answering (QA). To this end, we introduce a method for generating exhaustive and high-quality training data, which allows us to train compact (e.g., run on a mobile device), task-specific QA models that are competitive against GPT variants. The key technological enabler is a novel mechanism for automatic question-answer generation from procedural text which can ingest large amounts of textual instructions and produce exhaustive in-domain QA training data. While current QA data generation methods can produce well-formed and varied data, their non-exhaustive nature is sub-optimal for training a QA model. In contrast, we leverage the highly structured aspect of procedural text and represent each step and the overall flow of the procedure as graphs. We then condition on graph nodes to automatically generate QA pairs in an exhaustive and controllable manner. Comprehensive evaluations of our method show that: 1) small models trained with our data achieve excellent performance on the target QA task, even exceeding that of GPT3 and ChatGPT despite being several orders of magnitude smaller. 2) semantic coverage is the key indicator for downstream QA performance. Crucially, while large language models excel at syntactic diversity, this does not necessarily result in improvements on the end QA model. In contrast, the higher semantic coverage provided by our method is critical for QA performance.
CHEF: Cross-modal Hierarchical Embeddings for Food Domain Retrieval
Feb 04, 2021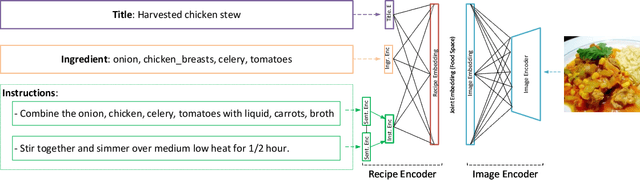
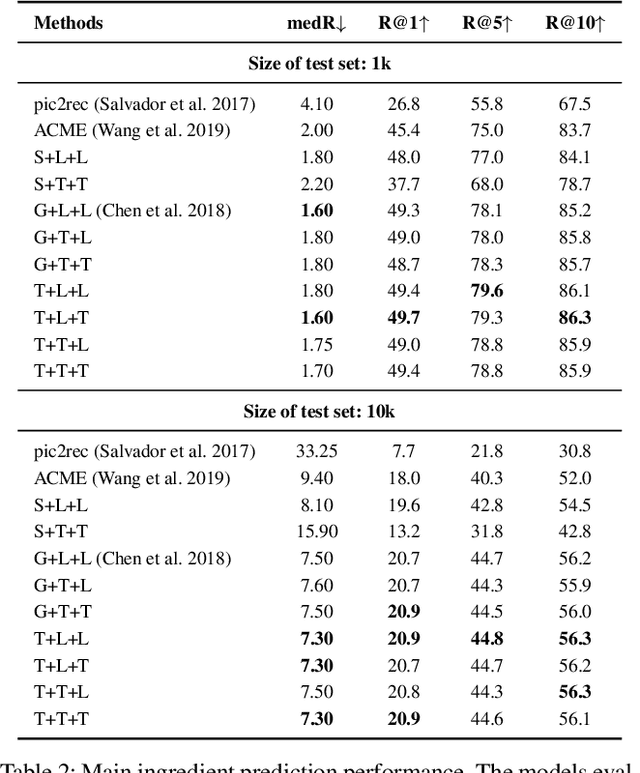
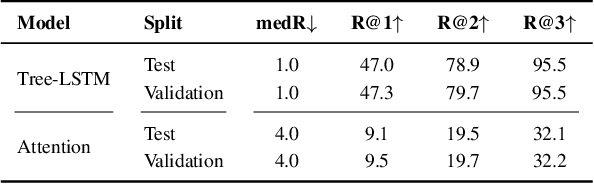

Despite the abundance of multi-modal data, such as image-text pairs, there has been little effort in understanding the individual entities and their different roles in the construction of these data instances. In this work, we endeavour to discover the entities and their corresponding importance in cooking recipes automaticall} as a visual-linguistic association problem. More specifically, we introduce a novel cross-modal learning framework to jointly model the latent representations of images and text in the food image-recipe association and retrieval tasks. This model allows one to discover complex functional and hierarchical relationships between images and text, and among textual parts of a recipe including title, ingredients and cooking instructions. Our experiments show that by making use of efficient tree-structured Long Short-Term Memory as the text encoder in our computational cross-modal retrieval framework, we are not only able to identify the main ingredients and cooking actions in the recipe descriptions without explicit supervision, but we can also learn more meaningful feature representations of food recipes, appropriate for challenging cross-modal retrieval and recipe adaption tasks.
Generative Adversarial Talking Head: Bringing Portraits to Life with a Weakly Supervised Neural Network
Mar 28, 2018
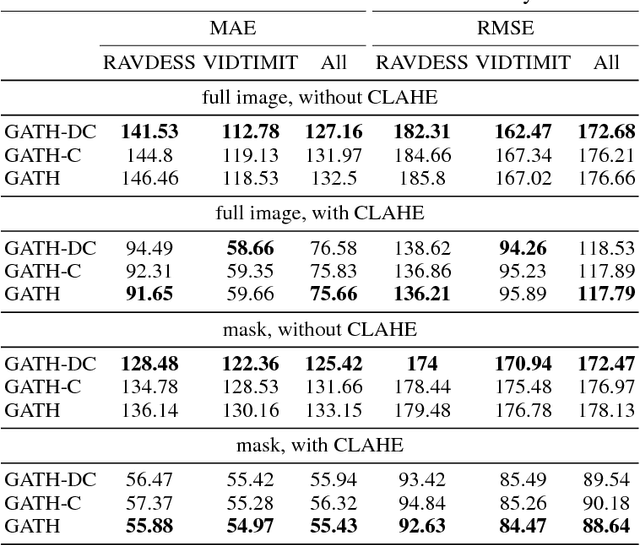
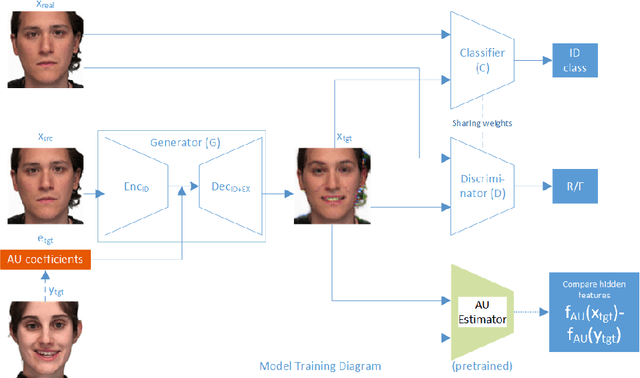

This paper presents Generative Adversarial Talking Head (GATH), a novel deep generative neural network that enables fully automatic facial expression synthesis of an arbitrary portrait with continuous action unit (AU) coefficients. Specifically, our model directly manipulates image pixels to make the unseen subject in the still photo express various emotions controlled by values of facial AU coefficients, while maintaining her personal characteristics, such as facial geometry, skin color and hair style, as well as the original surrounding background. In contrast to prior work, GATH is purely data-driven and it requires neither a statistical face model nor image processing tricks to enact facial deformations. Additionally, our model is trained from unpaired data, where the input image, with its auxiliary identity label taken from abundance of still photos in the wild, and the target frame are from different persons. In order to effectively learn such model, we propose a novel weakly supervised adversarial learning framework that consists of a generator, a discriminator, a classifier and an action unit estimator. Our work gives rise to template-and-target-free expression editing, where still faces can be effortlessly animated with arbitrary AU coefficients provided by the user.
End-to-end Learning for 3D Facial Animation from Raw Waveforms of Speech
Dec 07, 2017
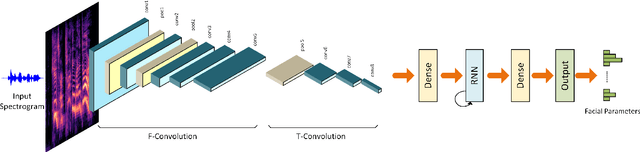

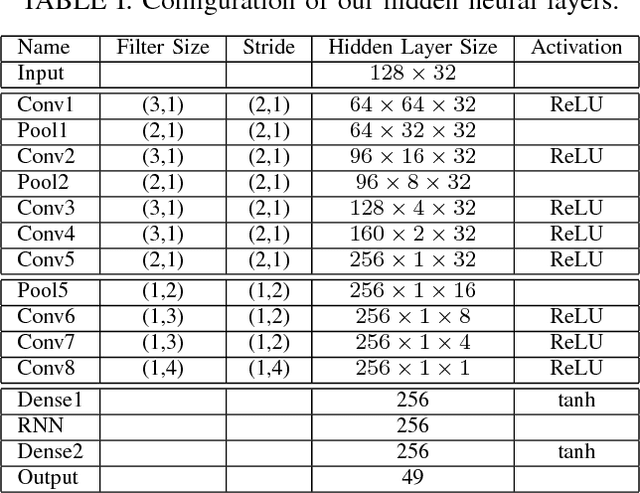
We present a deep learning framework for real-time speech-driven 3D facial animation from just raw waveforms. Our deep neural network directly maps an input sequence of speech audio to a series of micro facial action unit activations and head rotations to drive a 3D blendshape face model. In particular, our deep model is able to learn the latent representations of time-varying contextual information and affective states within the speech. Hence, our model not only activates appropriate facial action units at inference to depict different utterance generating actions, in the form of lip movements, but also, without any assumption, automatically estimates emotional intensity of the speaker and reproduces her ever-changing affective states by adjusting strength of facial unit activations. For example, in a happy speech, the mouth opens wider than normal, while other facial units are relaxed; or in a surprised state, both eyebrows raise higher. Experiments on a diverse audiovisual corpus of different actors across a wide range of emotional states show interesting and promising results of our approach. Being speaker-independent, our generalized model is readily applicable to various tasks in human-machine interaction and animation.
Robust Performance-driven 3D Face Tracking in Long Range Depth Scenes
Jul 10, 2015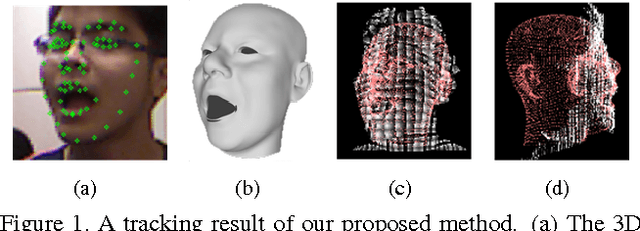
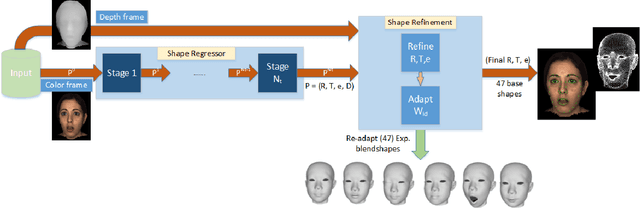
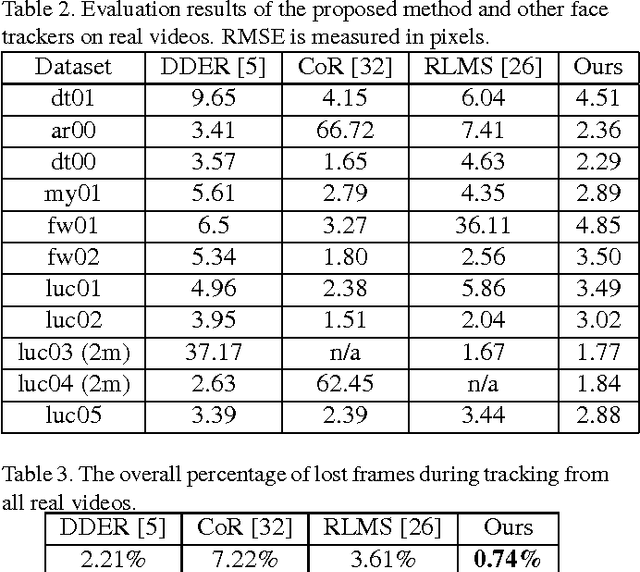

We introduce a novel robust hybrid 3D face tracking framework from RGBD video streams, which is capable of tracking head pose and facial actions without pre-calibration or intervention from a user. In particular, we emphasize on improving the tracking performance in instances where the tracked subject is at a large distance from the cameras, and the quality of point cloud deteriorates severely. This is accomplished by the combination of a flexible 3D shape regressor and the joint 2D+3D optimization on shape parameters. Our approach fits facial blendshapes to the point cloud of the human head, while being driven by an efficient and rapid 3D shape regressor trained on generic RGB datasets. As an on-line tracking system, the identity of the unknown user is adapted on-the-fly resulting in improved 3D model reconstruction and consequently better tracking performance. The result is a robust RGBD face tracker, capable of handling a wide range of target scene depths, beyond those that can be afforded by traditional depth or RGB face trackers. Lastly, since the blendshape is not able to accurately recover the real facial shape, we use the tracked 3D face model as a prior in a novel filtering process to further refine the depth map for use in other tasks, such as 3D reconstruction.