 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGeo: Unifying Geometry Logical Reasoning via Reformulating Mathematical Expression
Dec 06, 2022



Geometry problem solving is a well-recognized testbed for evaluating the high-level multi-modal reasoning capability of deep models. In most existing works, two main geometry problems: calculation and proving, are usually treated as two specific tasks, hindering a deep model to unify its reasoning capability on multiple math tasks. However, in essence, these two tasks have similar problem representations and overlapped math knowledge which can improve the understanding and reasoning ability of a deep model on both two tasks. Therefore, we construct a large-scale Unified Geometry problem benchmark, UniGeo, which contains 4,998 calculation problems and 9,543 proving problems. Each proving problem is annotated with a multi-step proof with reasons and mathematical expressions. The proof can be easily reformulated as a proving sequence that shares the same formats with the annotated program sequence for calculation problems. Naturally, we also present a unified multi-task Geometric Transformer framework, Geoformer, to tackle calculation and proving problems simultaneously in the form of sequence generation, which finally shows the reasoning ability can be improved on both two tasks by unifying formulation. Furthermore, we propose a Mathematical Expression Pretraining (MEP) method that aims to predict the mathematical expressions in the problem solution, thus improving the Geoformer model. Experiments on the UniGeo demonstrate that our proposed Geoformer obtains state-of-the-art performance by outperforming task-specific model NGS with over 5.6% and 3.2% accuracies on calculation and proving problems, respectively.
Structure-Preserving Image Super-resolution via Contextualized Multi-task Learning
Jul 26, 2017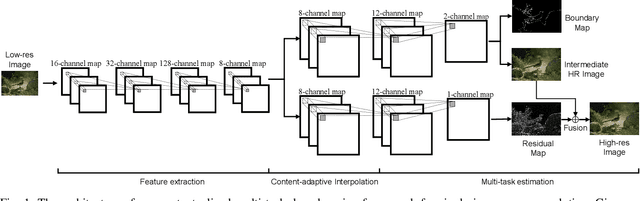

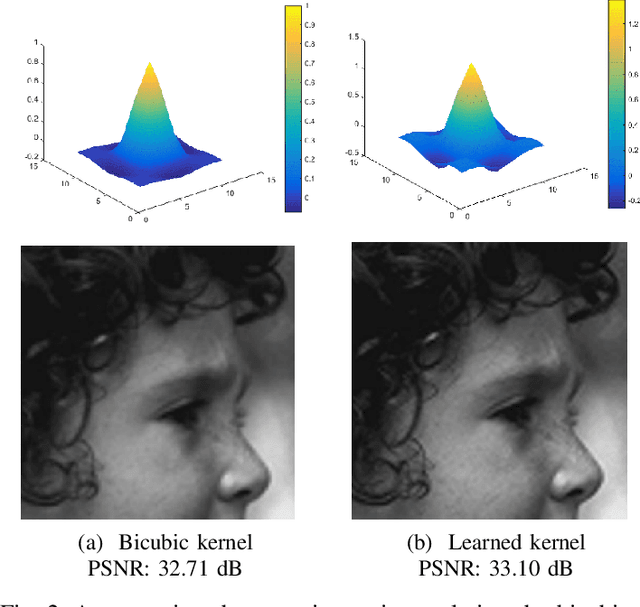
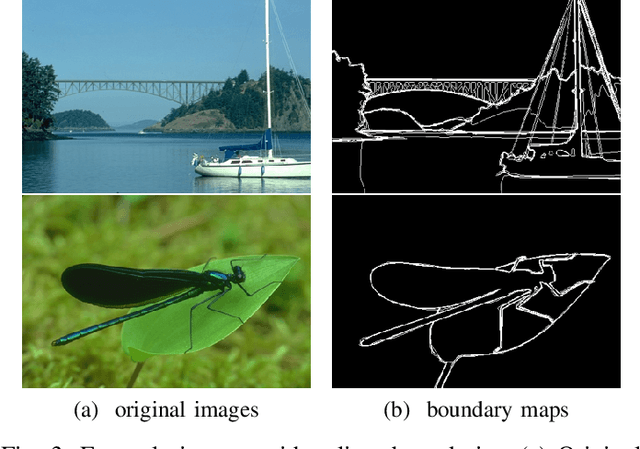
Single image super resolution (SR), which refers to reconstruct a higher-resolution (HR) image from the observed low-resolution (LR) image, has received substantial attention due to its tremendous application potentials. Despite the breakthroughs of recently proposed SR methods using convolutional neural networks (CNNs), their generated results usually lack of preserving structural (high-frequency) details. In this paper, regarding global boundary context and residual context as complimentary information for enhancing structural details in image restoration, we develop a contextualized multi-task learning framework to address the SR problem. Specifically, our method first extracts convolutional features from the input LR image and applies one deconvolutional module to interpolate the LR feature maps in a content-adaptive way. Then, the resulting feature maps are fed into two branched sub-networks. During the neural network training, one sub-network outputs salient image boundaries and the HR image, and the other sub-network outputs the local residual map, i.e., the residual difference between the generated HR image and ground-truth image. On several standard benchmarks (i.e., Set5, Set14 and BSD200), our extensive evaluations demonstrate the effectiveness of our SR method on achieving both higher restoration quality and computational efficiency compared with several state-of-the-art SR approaches. The source code and some SR results can be found at: http://hcp.sysu.edu.cn/structure-preserving-image-super-resolution/
Robust Performance-driven 3D Face Tracking in Long Range Depth Scenes
Jul 10, 2015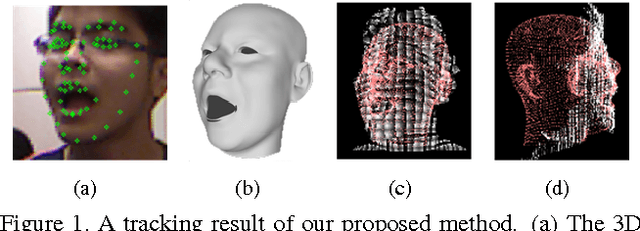
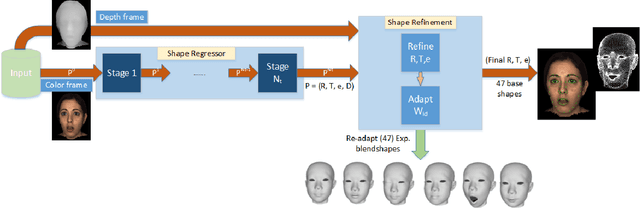
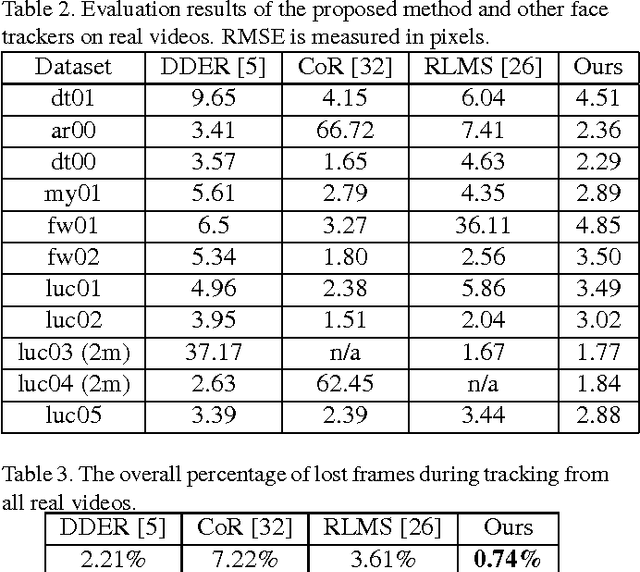

We introduce a novel robust hybrid 3D face tracking framework from RGBD video streams, which is capable of tracking head pose and facial actions without pre-calibration or intervention from a user. In particular, we emphasize on improving the tracking performance in instances where the tracked subject is at a large distance from the cameras, and the quality of point cloud deteriorates severely. This is accomplished by the combination of a flexible 3D shape regressor and the joint 2D+3D optimization on shape parameters. Our approach fits facial blendshapes to the point cloud of the human head, while being driven by an efficient and rapid 3D shape regressor trained on generic RGB datasets. As an on-line tracking system, the identity of the unknown user is adapted on-the-fly resulting in improved 3D model reconstruction and consequently better tracking performance. The result is a robust RGBD face tracker, capable of handling a wide range of target scene depths, beyond those that can be afforded by traditional depth or RGB face trackers. Lastly, since the blendshape is not able to accurately recover the real facial shape, we use the tracked 3D face model as a prior in a novel filtering process to further refine the depth map for use in other tasks, such as 3D reconstruction.