 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Think Thrice: Learning to Reason Causally with Double Counterfactual Consistency
Feb 18, 2026Despite their strong performance on reasoning benchmarks, large language models (LLMs) have proven brittle when presented with counterfactual questions, suggesting weaknesses in their causal reasoning ability. While recent work has demonstrated that labeled counterfactual tasks can be useful benchmarks of LLMs' causal reasoning, producing such data at the scale required to cover the vast potential space of counterfactuals is limited. In this work, we introduce double counterfactual consistency (DCC), a lightweight inference-time method for measuring and guiding the ability of LLMs to reason causally. Without requiring labeled counterfactual data, DCC verifies a model's ability to execute two important elements of causal reasoning: causal intervention and counterfactual prediction. Using DCC, we evaluate the causal reasoning abilities of various leading LLMs across a range of reasoning tasks and interventions. Moreover, we demonstrate the effectiveness of DCC as a training-free test-time rejection sampling criterion and show that it can directly improve performance on reasoning tasks across multiple model families.
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
Jun 18, 2025Recent Large Language Models (LLMs) have reported high accuracy on reasoning benchmarks. However, it is still unclear whether the observed results arise from true reasoning or from statistical recall of the training set. Inspired by the ladder of causation (Pearl, 2009) and its three levels (associations, interventions and counterfactuals), this paper introduces RE-IMAGINE, a framework to characterize a hierarchy of reasoning ability in LLMs, alongside an automated pipeline to generate problem variations at different levels of the hierarchy. By altering problems in an intermediate symbolic representation, RE-IMAGINE generates arbitrarily many problems that are not solvable using memorization alone. Moreover, the framework is general and can work across reasoning domains, including math, code, and logic. We demonstrate our framework on four widely-used benchmarks to evaluate several families of LLMs, and observe reductions in performance when the models are queried with problem variations. These assessments indicate a degree of reliance on statistical recall for past performance, and open the door to further research targeting skills across the reasoning hierarchy.
Synthetic Function Demonstrations Improve Generation in Low-Resource Programming Languages
Mar 24, 2025
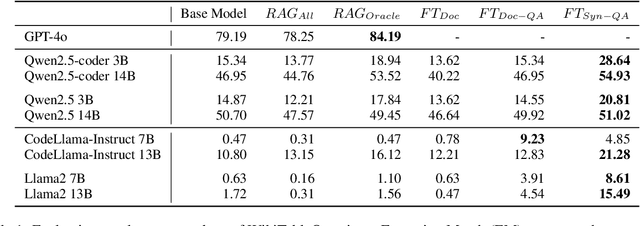

A key consideration when training an LLM is whether the target language is more or less resourced, whether this is English compared to Welsh, or Python compared to Excel. Typical training data for programming languages consist of real program demonstrations coupled with human-written comments. Here we present novel approaches to the creation of such data for low resource programming languages. We generate fully-synthetic, textbook-quality demonstrations of common library functions in an example domain of Excel formulas, using a teacher model. We then finetune an underperforming student model, and show improvement on 2 question-answering datasets recast into the Excel domain. We show advantages of finetuning over standard, off-the-shelf RAG approaches, which can offer only modest improvement due to the unfamiliar target domain.
Compositional Causal Reasoning Evaluation in Language Models
Mar 06, 2025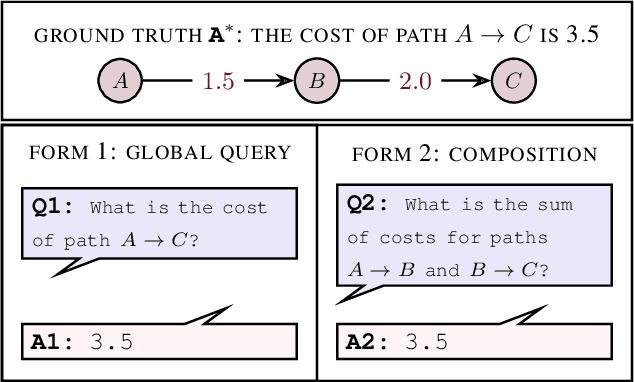

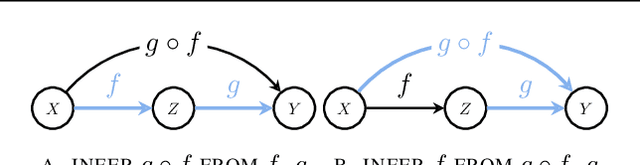

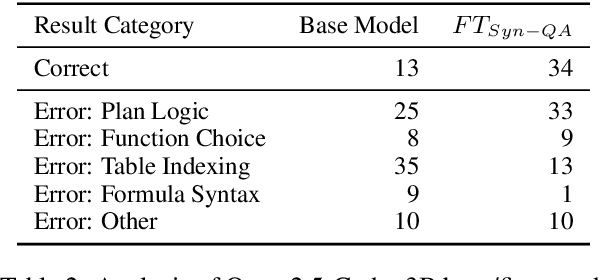
Causal reasoning and compositional reasoning are two core aspirations in generative AI. Measuring the extent of these behaviors requires principled evaluation methods. We explore a unified perspective that considers both behaviors simultaneously, termed compositional causal reasoning (CCR): the ability to infer how causal measures compose and, equivalently, how causal quantities propagate through graphs. We instantiate a framework for the systematic evaluation of CCR for the average treatment effect and the probability of necessity and sufficiency. As proof of concept, we demonstrate the design of CCR tasks for language models in the LLama, Phi, and GPT families. On a math word problem, our framework revealed a range of taxonomically distinct error patterns. Additionally, CCR errors increased with the complexity of causal paths for all models except o1.
A Bayesian Approach to Data Point Selection
Nov 06, 2024Data point selection (DPS) is becoming a critical topic in deep learning due to the ease of acquiring uncurated training data compared to the difficulty of obtaining curated or processed data. Existing approaches to DPS are predominantly based on a bi-level optimisation (BLO) formulation, which is demanding in terms of memory and computation, and exhibits some theoretical defects regarding minibatches. Thus, we propose a novel Bayesian approach to DPS. We view the DPS problem as posterior inference in a novel Bayesian model where the posterior distributions of the instance-wise weights and the main neural network parameters are inferred under a reasonable prior and likelihood model. We employ stochastic gradient Langevin MCMC sampling to learn the main network and instance-wise weights jointly, ensuring convergence even with minibatches. Our update equation is comparable to the widely used SGD and much more efficient than existing BLO-based methods. Through controlled experiments in both the vision and language domains, we present the proof-of-concept. Additionally, we demonstrate that our method scales effectively to large language models and facilitates automated per-task optimization for instruction fine-tuning datasets.
Reasoning Elicitation in Language Models via Counterfactual Feedback
Oct 02, 2024



Despite the increasing effectiveness of language models, their reasoning capabilities remain underdeveloped. In particular, causal reasoning through counterfactual question answering is lacking. This work aims to bridge this gap. We first derive novel metrics that balance accuracy in factual and counterfactual questions, capturing a more complete view of the reasoning abilities of language models than traditional factual-only based metrics. Second, we propose several fine-tuning approaches that aim to elicit better reasoning mechanisms, in the sense of the proposed metrics. Finally, we evaluate the performance of the fine-tuned language models in a variety of realistic scenarios. In particular, we investigate to what extent our fine-tuning approaches systemically achieve better generalization with respect to the base models in several problems that require, among others, inductive and deductive reasoning capabilities.
Graph Guided Question Answer Generation for Procedural Question-Answering
Jan 24, 2024
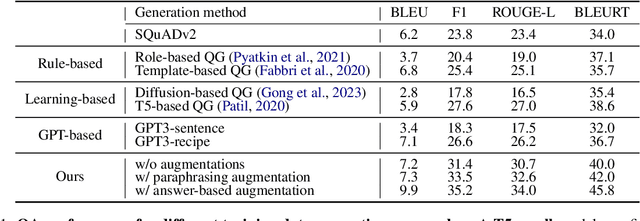
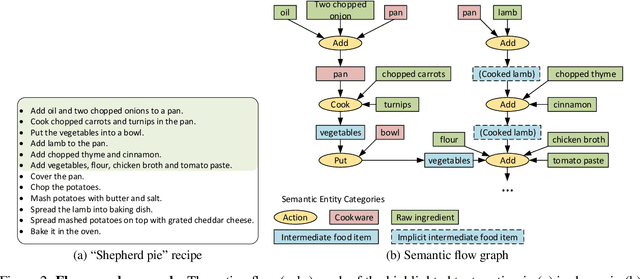
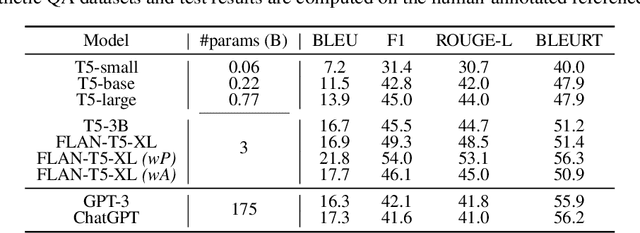
In this paper, we focus on task-specific question answering (QA). To this end, we introduce a method for generating exhaustive and high-quality training data, which allows us to train compact (e.g., run on a mobile device), task-specific QA models that are competitive against GPT variants. The key technological enabler is a novel mechanism for automatic question-answer generation from procedural text which can ingest large amounts of textual instructions and produce exhaustive in-domain QA training data. While current QA data generation methods can produce well-formed and varied data, their non-exhaustive nature is sub-optimal for training a QA model. In contrast, we leverage the highly structured aspect of procedural text and represent each step and the overall flow of the procedure as graphs. We then condition on graph nodes to automatically generate QA pairs in an exhaustive and controllable manner. Comprehensive evaluations of our method show that: 1) small models trained with our data achieve excellent performance on the target QA task, even exceeding that of GPT3 and ChatGPT despite being several orders of magnitude smaller. 2) semantic coverage is the key indicator for downstream QA performance. Crucially, while large language models excel at syntactic diversity, this does not necessarily result in improvements on the end QA model. In contrast, the higher semantic coverage provided by our method is critical for QA performance.
Compositional Generalization for Data-to-Text Generation
Dec 05, 2023



Data-to-text generation involves transforming structured data, often represented as predicate-argument tuples, into coherent textual descriptions. Despite recent advances, systems still struggle when confronted with unseen combinations of predicates, producing unfaithful descriptions (e.g. hallucinations or omissions). We refer to this issue as compositional generalisation, and it encouraged us to create a benchmark for assessing the performance of different approaches on this specific problem. Furthermore, we propose a novel model that addresses compositional generalization by clustering predicates into groups. Our model generates text in a sentence-by-sentence manner, relying on one cluster of predicates at a time. This approach significantly outperforms T5~baselines across all evaluation metrics.Notably, it achieved a 31% improvement over T5 in terms of a metric focused on maintaining faithfulness to the input.
MiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization
Sep 22, 2021
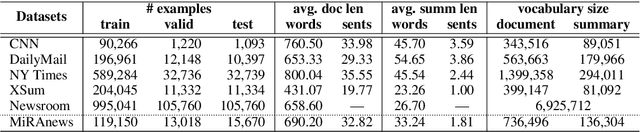
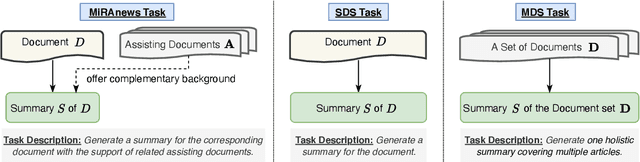

One of the most challenging aspects of current single-document news summarization is that the summary often contains 'extrinsic hallucinations', i.e., facts that are not present in the source document, which are often derived via world knowledge. This causes summarization systems to act more like open-ended language models tending to hallucinate facts that are erroneous. In this paper, we mitigate this problem with the help of multiple supplementary resource documents assisting the task. We present a new dataset MiRANews and benchmark existing summarization models. In contrast to multi-document summarization, which addresses multiple events from several source documents, we still aim at generating a summary for a single document. We show via data analysis that it's not only the models which are to blame: more than 27% of facts mentioned in the gold summaries of MiRANews are better grounded on assisting documents than in the main source articles. An error analysis of generated summaries from pretrained models fine-tuned on MiRANews reveals that this has an even bigger effects on models: assisted summarization reduces 55% of hallucinations when compared to single-document summarization models trained on the main article only. Our code and data are available at https://github.com/XinnuoXu/MiRANews.
AGGGEN: Ordering and Aggregating while Generating
Jun 17, 2021We present AGGGEN (pronounced 'again'), a data-to-text model which re-introduces two explicit sentence planning stages into neural data-to-text systems: input ordering and input aggregation. In contrast to previous work using sentence planning, our model is still end-to-end: AGGGEN performs sentence planning at the same time as generating text by learning latent alignments (via semantic facts) between input representation and target text. Experiments on the WebNLG and E2E challenge data show that by using fact-based alignments our approach is more interpretable, expressive, robust to noise, and easier to control, while retaining the advantages of end-to-end systems in terms of fluency. Our code is available at https://github.com/XinnuoXu/AggGen.
* Correct the first citation in the Zero-shot Few-shot scenarios paragraph in Section 7